cocopar zg-1564k-zxb (YTH156KC) 15.6インチ 4KHDR対応モバイルモニタ
サブモニタに使っていたFlexScan S170が 45747時間の使用の末画素欠け等出てきたので。。
Amazonのタイムセールで3万円だった。
商品説明が変
【ミニHDMIポート二つ搭載】普通のHDMI出力設備全て対応できます、パソコン、ノートPC、プレゼン用、一眼レフカメラ、 PS3/PS4/Xbox One/Nintendo Switchゲーム機、デスクトップPCなど ミニHDMI→HDMIケーブルは付属しております。
商品説明ではmini-HDMIが付いているように書かれているが、これは間違いで、結局のところ説明書が正しかった。実際には標準HDMI(2.0) + mini-DP + USB-C (alt DP)の3端子だった。
全端子4Kで映る
同じCocoparの18インチ品のレビュー( https://gadgeterkun.hatenablog.com/entry/20200524/1590316514 )で2Kしか出ないみたいな言及があったので気になっていたけど、DPもHDMIもちゃんと4K出ることが確認できた。
HDMIはAmazon Fire TV Stick 4K( https://mjt.hatenadiary.com/entry/2019/04/07/185233 )を接続して確認。自動的にHDRモードになってしまうのでちょっと暗く写った。いずれにせよ、HDRに対応したソース機器の場合自動的にHDR出力になってしまうことが多そうなので、据え置きで使うなら、HDRモードを有効にして 輝度最強 にしておくのがたぶん正しい使い方なのだろう。
DP / USB-C はmac mini 2018のUSB-Cで確認した。こちらは8bitディスプレイとして最初認識され、手動で10bitに設定する必要があった。FreeSyncは手頃な対応ソースを持っていないので試せず。
かんそう
モバイルモニタだから当たり前なんだけど、右端からケーブルが出るのでレイアウトに制約が出る。狭額を生かして並べるなら縦位置にするしか無さそう。
なぜかOSDのナビケーションにシーソースイッチ(上・下・押し込み がある奴)を採用していて、特に決定操作(ボタン押し込み)がやりづらい。仕事から入力切り替えを頻繁にやるので、やっぱりココは専用ボタンが欲しいかな。。
3万円で高PPIなディスプレイが入手できるのはリーズナブルなので、前買ったレンチキュラーレンズシート( https://mjt.hatenadiary.com/entry/20140113/p1 )で裸眼立体視ディスプレイを作りたいと思った。
プリチャンランドにおけるAIマスコットTier仮説
※ アニメ感想メモ

- prev: https://mjt.hatenadiary.com/entry/20181208/p1
- プリチャンはどこに向うか
キラッとプリ☆チャンのアニメは毎期でテイストを大きく変える方向に出たようで、営業的な効果はともかく非常に興味深い。1期のYouTuber立志伝、2期のVTuber+AIというトレンドを捉えた方向から、3期では急に多種多様な"マスコット"と呼ぶサポートAIの成長ストーリーに舵を切っている。
- https://www.animatetimes.com/news/details.php?id=1595915052
- TVアニメ『キラッとプリ☆チャン』シーズン2振り返り:大庭晋一郎(タカラトミーアーツ)×依田健(タツノコプロ)インタビュー
あれはAIであり別人格なんですけど、大きく考えると、虹ノ咲さん自身でもあるんですよね。自分で作り出したイマジナリーフレンドというか。
2期はサポートAIに支援されてVTuberデビューするといった示唆的な内容やらRezみたいな電脳空間での戦闘やら コミック百合姫でお勧めアニメになる などバラエティに富んだシナリオで非常に良い作品だったと思う。
3期は通常の展開であれば最終期に相当するため、過去のシリーズとの接続を意識したのかかなりファンタジー寄りの設定でAIを描写していて、それがとても興味深い内容になっている。
マスコットとルール/システム
3期で導入されたマスコット(プリキュアで言うところの妖精に相当する)は以下のような性質を持つ:
- プリチャンランド(= 遊園地)運営からアイドル1グループに1体支給される
- マクロスやキルミンずぅのように3段階の状態を持つ 0) たまご 1) プチマスコット (動物または物体モチーフの形状) 2) プリティーマスコット (人間型だが妖精形態のまま) 3) アイドルマスコット (人間と同じ背格好)
- 認定試験があり、不合格が続くとたまごに戻る
- 本人の能力や実世界との干渉能力で差別化されている
プリチャンは基本的にギャグアニメであるが、何故かマスコットの設定は比較的一貫した形で表現されている。
Tier仮説
おそらく、プリチャンにおける作劇上のマスコット設定は、その能力を階層化した形で管理しているのではないだろうか。これは ブレードランナーにおけるレプリカント(の型) とか 幽遊白書における 〜級妖怪 のようによく見られる手法ではあるが、そもそもストーリーの主軸とは思えないところで作り込まれている理由は現状謎と言える。
Tier3マスコット
一般のマスコットがここに分類される。
- プリチャンランド外部でも存在できる
- プリチャンランド外部では物理世界に干渉できない
- バーチャル〜 と銘打ったアイテムでお世話が可能(バーチャルフード、バーチャル薬等)
- 周囲の環境光源に影響されない
... 周囲の環境光源に影響されないというのが非常に用途が謎だが実際そのように描写されているので。。
マスコット認定試験は、(プリチャンランド内限定とは言え)現実世界に干渉する可能性のあるTier3マスコットの製造者責任を果たすためのものと考えられる。
(プリチャンでは名前が出ていないが、シリーズの伝統として"マスコットの墓場"という設定があり、このシリーズではマスコットに出来損ないがいることが普通に受け入れられている。)
Tier2マスコット
キラッCHU、メルパンのような主人公サイドのマスコットがここに分類される。
- アイドルマスコット形態に(外的要因で)変化できる
今のところこのポイントしかないが、今後Tier2マスコットを差別化させる要素が追加されると予想している。シナリオ上は担当アイドルとの絆なり何なりでアイドルマスコット形態に遷移できるように表現されているが、その実態を Tierの移動 と考えるほうが性質を纏めて表現できるのではないだろうか。
キラッCHUは2期のデザインパレットから移行したキャラクタとして描かれていて、純粋な3期キャラクタであるメルパンよりも劣った描写がされている。物理的な形質の描き方には差が無いものの、今後実装世代の違いによる差が設定されるかもしれない。
Tier1 / Tier0マスコット
ソルル・ルルナの両マスコットは明らかに他のマスコットと区別された形で表現されており、Tier1に位置付けられる。 今後 Tier1マスコットの存在理由と目的 が大きなテーマになるのではないかと思う。
- プリチャンランド外部でも物理世界に干渉できる
- アイドルマスコット形態に(必要に応じて)変化できる
- 周囲の環境光源に影響される
プリチャンランドのキャストマスターであるめが兄ぃは、プチマスコット等の形態を持たない特殊な Tier0 マスコット として位置付けられていると見られる。(人間である必要がない)
ポイントはソルルのパートナーである アリス・ペペロンチーノがTier0マスコットかどうか という点と言える。そのべらんめぇな出自や生活様式、バーチャル目薬を自分に使うといった他のキャラクタから際立った異常性があるため、それをマスコットの性質として処理してしまうのが簡単なのではないだろうか。
悪役のいない世界でどうドラマを作るか
一般的にアイドルは人を殺したりしないため、アイドルアニメは勧善懲悪になりづらい。当然勧善懲悪だけがドラマではないのでやりようは有るが、どうやって3年もアニメをやるのかというのは常に難題なのだろうと思う。
プリチャンのアニメは1期・2期については描く必然性のある現代的な内容をテーマとして選んで表現してきた。それが3期ではかなりストレートにキャラクターを推す方向になり、その内容も(女児アニメを3年続けた場合にお約束になる)育成要素を据えている。
この変化がなぜ必要だったのかはどうにも分からない。営業上の要請でマスコットキャラクタを多数出す必要があったとして、現実の問題をストーリーにすることは十分可能に思える。
1つの可能性としては、プリチャンの次の作品のためにテーマを移譲する必要があったためというのが考えられる。しかし、もう1つの可能性として 実は3期のテーマも現実世界の問題を反映している と考えられないだろうか。そして現状出ているシナリオでもっとも描かれそうなテーマが"プラットフォームによる個人と社会の支配"なのではないか。
プリチャンランドという比較的小さなプラットフォームを運営することで人間から信頼される術を身につけたTier2マスコットを作り出し、それにより自社の基盤を強化する。強化されたTier2マスコットがプラットフォーム外部まで影響を及ぼす点がシナリオ上の問題となり、それを解決するためにソルル・ルルナの両陣営が出会うエンディングとなるように思う。
プラットフォームという存在そのものは悪役ではないが、現実でもYouTubeやTwitter、Uber Eatsのようなプラットフォームが転嫁している社会的コストや個人間の問題があり、解決すべき課題を提示できるように見える。
MIT Schemeでdefine-macroする
yuniのレガシーなビルドシステムと決別する最後の壁になっていたMIT Schemeも、define-macro を手作りすることでサポートできた。というわけで、これで従来のビルドシステムから新しいビルドシステムに置き換えられる。。
新しいビルドシステムではLarceny、Vicare、picrin、 nmosh などいくつかの処理系のサポートを停止する。その代わりもっと別の処理系(主に非R6RS/R7RS処理系)をサポートする予定。nmoshを切るのは断腸の思いだけど、別の処理系をスクラッチで作る予定なのでそのための工数をどうしても空ける必要がある。
define-macro を逆sc-macroで定義する
... 今検索したらそのものズバリなStack overflowが有った。。
(define-syntax define-macro (syntax-rules () ((define-macro (name . args) body ...) (define-syntax name (rsc-macro-transformer (let ((transformer (lambda args body ...))) (lambda (exp env) (apply transformer (cdr exp)))))))))
MIT Schemeにおける低レベルマクロは、chibi-schemeと同じく syntactic closure で、sc-macro-transformer は、
- マクロが挿入したシンボル → マクロが定義された場所の意味で解釈される
make-syntactic-closureを通したシンボル → (一般に)マクロが使われた場所の意味で解釈される
という性質がある。ここで使用している rsc-macro-transformer は 逆 で、マクロが挿入したシンボルはマクロが使われた場所の意味で解釈される。これは define-macro でやりたいことそのものと言える。
今回実装したものは、↑の実装に加えて、 define-syntax のための特別対応を入れている:
(define-syntax define-macro (syntax-rules (define-syntax) ((_ (define-syntax name synrule) body ...) ;; Skip syntax-rules (begin)) ((_ (nam . args) body ...) (define-syntax nam (rsc-macro-transformer (let ((xformer (lambda args body ...))) (lambda (exp _) (apply xformer (cdr exp)))))))))
これは、yuniのランタイムが syntax-rules を備えないScheme処理系のために define-syntax をマクロで定義するコードを含んでいることによる。MIT SchemeはR5RS(R7RS)なので syntax-rules は当然持っており、yuniのコードにある (define-macro (define-syntax ...) ...) のコードは無視しなければならない。そうでないと define-macro が define-syntax に展開され、無限再帰してしまう。。
MIT SchemeがR7RSでないところ
MIT Schemeは真の values を実装していない https://mjt.hatenadiary.com/entry/20170515/p1 以外に、yuniのテストケースで見つかったものとしては:
list-copyがペア以外を受けつけない https://www.gnu.org/software/mit-scheme/documentation/mit-scheme-ref/Construction-of-Lists.html#index-list_002dcopylogが底を取らない https://www.gnu.org/software/mit-scheme/documentation/mit-scheme-ref/Numerical-operations.html#index-log
というのが有った。流石に values をエミュレートするのはパフォーマンスペナルティが大きすぎるけど、この辺はエミュレートした方が良いかもしれない。。
それ以前に、MIT SchemeのR7RSサポートは現状ライブラリパスを設定する方法が無く、yuniではR7RS処理系ではなく define-macro 処理系(yuniの用語でGeneric Scheme処理系)として扱っている。
HDMIサラウンド音声フォーマットを手動で設定した場合の挙動の調査
平成最後の買い物ということで(Mac miniと)HDMIから光デジタルで音声信号を取り出すスプリッタを買ってきた。というか秋葉原にカレーショップC&Cが有るのにビックリした。アレ京王沿線じゃなくても良いのか。。
mac miniはXcode用に一番安い奴(Core i3、128GiB)。Metal非対応機はもうサポート無いので。。特記事項なし。
買ってきたHDMI音声スプリッタはアエリア SD-HDSPRL 。
- https://www.area-powers.jp/product/others/4580127692938/
- HDMI信号から音声を分離させて出力が可能なアダプタ「SD-HDSPRL」
...このアダプタ自体はEDIDの書き換えによってSink機器のケーパビリティに依らずサラウンド音声をSource機器に出力させることができるが、 何故かDolby Digital Plusも見せてしまう ため多くの環境で手動設定が必要になっている。今回は、実は大抵の機器に備わっているサラウンド音声の再エンコード機能を活用してみることにする。

EDID上のオーディオの見え方は、例えばWindowsを使えば確認できる。ここで確認できるように、スイッチを"5.1CH"側に切り替えると、通常のPCモニタでもサラウンド音声が受信できるかのようなfakeを行ってくれる。この状況で、サラウンド音声を光デジタルから取り出すには手動で設定が必要なので、それぞれ設定して挙動を見てみた。
AppleTV
AppleTVはサポートページ https://support.apple.com/appletv/audio で言及されているように、"設定" → "ビデオとオーディオ" → "オーディオフォーマット" から設定できる。

この設定を行っても、通常のシステムUIは2chで出力され、手元ではPrimeVideoも2ch出力だった。再エンコードを良しとしていないんだろうか。。iTunes store側の映画トレイラーはDolby Digitalになったので、実装に依るのかもしれない。
FireTV
FireTVでは、"設定" → "ディスプレイとサウンド" → "オーディオ" → "サラウンド音響" → "常にDolby Digital" でDolby Digital出力を強制できる。

横にチェックマークが付いた状態になっていれば正常に設定されている。このスクリーンショットでは、この選択状態だとOffかのように読めるが、実際には、選択前には
選択すると "常にDolby Digital" がオンになります。
のように表記されている。これは誤訳ではなく英語UIでも同様の文言が表示されているため、単に仕様上の見落しだろう。
FireTVではAppleTVと異なり常時エンコードされる。更に、他の機器と異なり、システムUIではDolby Digital 2ch にエンコードされる。

手元のDP-1000だとDolby DigitalとDolby Pro Logic IIの両方が点灯する珍しい状況になる。
XboxOne
"設定" → "画面とサウンド" → "オーディオ出力" → (スピーカーオーディオ) "HDMIオーディオ" を "ビットストリーム出力" に設定し、更に "ビットストリーム形式" を"ドルビーデジタル" か "DTS" のどちらかに設定する。

XboxOneではシステムUIを含め基本的に全ての出力が8ch出力なため、常時Dolby Digital / DTSエンコードされることになる。ちなみに、PS4もほぼ同じ仕様となる(Atmosが無い)。
再エンコード機能の挙動
というわけで、各社のサラウンド再エンコード機能の挙動を纏めると:
| プラットフォーム | AppleTV | FireTV | XboxOne/PS4 |
|---|---|---|---|
| システムUI | PCM | AC-3 2ch | AC-3/DTS 5.1ch |
| LPCMコンテンツ | ? | ? | AC-3/DTS 5.1ch |
| Dolby Digital コンテンツ | AC-3 5.1ch | AC-3 5.1ch | AC-3/DTS? 5.1ch |
※ XboxOne/PS4はbitstream pass throughに対応しているため、DTS選択時にAC-3コンテンツを再生しようとした場合は再エンコードしないはずだが、手元ではそのような挙動にならなかった。 まだ設定が悪いかも しれない。
AppleTVは保守的に、必要の無い限り再エンコードを避けている。逆に、Amazon FireTVやゲーム機は 常に エンコードを掛けている。これは切り替え時に無音や雑音が入るのを嫌っていると考えられる。FireTVが2chのDolby Digitalを採用した理由は謎で、ProLogicのようなマトリックスサラウンドを生かしたいのであれば、AppleTVのように2chコンテンツをLPCMにした方が合理的に思える。
ゲーム的に気になるのはサラウンドなLPCMコンテンツがどうなるのか。。Qiitaに書いたように https://qiita.com/okuoku/items/eb70c14def3c4122d7af リアルタイムDolby Digitalエンコードをしても良いかもしれないけど、面倒なので避けたい。多少ストアを見て廻った限りでは、LPCMサラウンドなアプリは皆無で、そもそも実装可能なのかもよくわかっていない。
Amazon FireTV Stick 4K
3台目、スマートTV機器としては5台目。
- https://mjt.hatenadiary.com/entry/20150923/p1
- Nexus Player
- https://mjt.hatenadiary.com/entry/20151103/p1
- AppleTV gen4
- https://mjt.hatenadiary.com/entry/20151220/p1
- FireTV Stick (gen1)
- https://mjt.hatenadiary.com/entry/20151210/p1
- FireTV gen2
... 以前のはみんな2015年に買ってるのか。。当時は各社からこの手のデバイスが次々と投入されていて、microconsoleという言葉もちょっとしたブームになっていた。現状ではApple TV+ がFireTVに投入されることが発表される等、ハードウェアの主戦場は既にスピーカーに移っており、TVは当時ほどの盛り上りを見せていない。
今回は普通にAmazonで購入。AmazonのデバイスはAmazonで購入した場合アカウント紐付になるという説明があるが、今回はセール期間に購入したためか、手動でアカウントの登録作業をする必要があった。

年々大型化している気がするAmazon Fire Stick。上が初代Stick(2014) 、下が今回購入したFireTV Stick 4K。初代はそもそも超クッソ激烈に熱暴走しやすくアプリのインストールやWebブラウズ等を行うと直ぐ熱暴走していた。

今回のStick 4Kは流石に通常の使用範囲では熱暴走することはなかった。
初代のGPUはRaspberry Piと同じVideo Core 4、今回のStick 4KのGPUはPowerVRになっている。初代FireTV Stickは既にディスコンなため、実は現状のFireTV(やAppleTV)は全てGLES 3.0以降を仮定できる。
- https://gist.github.com/okuoku/256606ab897c4dc284ae421ee9acbf7d#file-firetv_stick_features-txt
- 初代FireTV StickのFeatures (
adb shell pm list featuresの結果)
- 初代FireTV StickのFeatures (
- https://gist.github.com/okuoku/256606ab897c4dc284ae421ee9acbf7d#file-firetv_gen2_features-txt
- FireTV gen2のFeatures
- https://gist.github.com/okuoku/256606ab897c4dc284ae421ee9acbf7d#file-firetv_4k_features-txt
- FireTV Stick 4K のFeatures
FireTV Stck 4KのUIパフォーマンスは比較的良好で、特に初代Stickと比べると雲泥の差がある。
FireOS 5 vs FireOS 6
前回のFireTV(gen3)はスキップし、FireTV Cube(gen1)は日本での扱いが無いので、今回のFireTV Stick 4Kが手元のデバイスとしては最初のFireOS 6デバイスになった。
FireOS 5 は Androidで言うところの 5.1 Lollipop (API Level 22)に相当し、 FireOS 6 は Android で言うところの 8.1 Nougat (API Level 25) に相当する。基本的にFireOS6はFireOS5の後方互換となっているが:
- Miracastサポートが廃止された... が、最近急にアップデートが配信されサポートが復活した。https://japanese.engadget.com/2019/04/06/fire-tv-stick-4k/
- 純正アクセサリのうち、FireTVゲームコントローラはサポートされなくなった。
といった絶妙な違いがある。
ホーム画面や設定UI等Amazon独自アプリはFireOS5デバイスとFireOS6デバイスで共有されており、初代FireTV StickとFireTV Stick 4Kでパフォーマンスは大きく違うものの 基本的に全く同じ UIが表示される。(もちろんデバイスのケーパビリティや地域に合わせた変更は行われる -- 手元ではアップデート前は日本未発売のFireTV Recastの設定項目が表示されていたが、アップデートで削除された)
まだ 4Kでない FireTV stickがFireOS5で販売されているので、FireOS5が絶滅したわけではない。
基盤バージョンの違いが一番不味い形で表われるのはDolby Digitalのサポートで、最初にJelly Beanベースでリリースされた初代FireTV / FireTV Stickを想定すると相当に複雑な処理が必要になってしまう( https://developer.amazon.com/ja/docs/fire-tv/dolby-integration-guidelines.html )。Amazonは、これらの旧世代機向けにExoPlayerの移植版を提供( https://github.com/amzn/exoplayer-amazon-port )することで移植コストの低減を図っている。
ゲーミング
Amazon FireTV gen2 は専用のゲームコントローラを同時に発売し、コントローラ側のヘッドホンサポートや専用ゲームの展開等それなりにゲームを推していた。しかし、2017年以降はこの傾向は失われてきた。専用のゲームプラットフォームであり、初代ゲームコントローラには専用ボタンまで存在した GameCircleは廃止 されているし、FireTVのパッケージでも一切ゲームへの言及は無い。過去のFireTVでは:
(初代FireTV stickのパッケージ)
簡単に使える
テレビに直接差し込んで、すぐに使い始められます。簡単な操作で映画、TV番組、アプリ、ゲームが見つかります。
(FireTV gen2のパッケージ)
快適なゲーム体験
アクションからカジュアルまで、人気のゲームが勢揃い。別売りのゲームコントローラーを追加すればゲームがより本格的に。
のようにゲームに言及していた。
Stick 4Kのゲーム対応状況は何とも言えない。聖剣伝説( https://www.amazon.co.jp/dp/B01CZKNQQM )は 非対応 、GLES2でも動作する脅威の互換性のアスファルト8( https://www.amazon.co.jp/dp/B00EQ0CKRQ )は当然の権利のように対応、Unity製のクロッシーロード( https://www.amazon.co.jp/dp/B00QW8TYWO )も当然対応。スクエア・エニックスはAmazon AppStoreに積極的にゲームを提供しているが、ネイティブ動作のゲームでStick 4K対応のものはかなり少い。(FF12等、G-Clusterが展開するクラウドストリーミング版は相当な数があるものの。)
もっとも、Amazonがゲームから手を引いたわけではない。自身のゲームスタジオであるAmazon Game Studiosは現在はPCやコンソール向けにゲームを供給しており、Prime Videoコンテンツのゲーム化である The Grand Tour Game をリリースしている。
ちなみにFireTVは標準のWebブラウザとしてFirefoxを採用しており、このFirefoxは ゲームコントローラAPIやWebGLもサポートしている (元々YouTube見せる用なんだからWebAPIの対応状況が良いのは当たり前な気もするが)。XboxOneのBluetooth対応コントローラも接続でき、ゲームコントローラとして使用できた。

(スクリーンショットは初代FireTV StickにFireTVゲームコントローラとXboxOneコントローラの両方を無線接続したもの。 最近のFireTVはFireTVゲームコントローラに対応しない 。)
ただMansion Demo( https://www.babylonjs.com/demos/mansion/ )でも10fps出るかどうかというところなのであんまりゲームプラットフォームとして使うのは実用的ではないかも知れない。

他のブラウザ選択肢としてはAmazon Silkが有り、タブレット版とは異なり単なるWebKitベースブラウザのようだ。
Unbox Experience
最近のFireTVは電源投入時の導入動画に続けて、アプリケーションのインストールを促す画面が挟まれるようになった。

"趣味・教養"の欄には麻雀ゲームであるMaru-Jan、"その他おすすめ"には オンラインカジノ 、 トレバ (ストリーミングによるクレーンゲーム)、テトリス等がある。表向きにはゲームは推していないものの、セットアップ時にはインストールを促されるし、アプリのカテゴリにはゲーム自体は健在となっている。
Amazonのアカウントリンクはパスワードを手で入力する必要があり、なかなか辛いものになっている。Nexus Playerではワンタイムパスコード6桁の入力で済む( http://g.co/AndroidTV )ことを考えると。。ちなみに箱に載っているniconicoも同様で、OSKでパスワードをポチポチ打つ必要がある。
開発、PowerVR SDK
GPUとしてIMGのGE8300を搭載しているため、PowerVR SDKを使用してパフォーマンスカウンタ等の読取が可能になっている。ただし、 Vulkanは使用できない 。ファイルシステムには libvulkan.so が有るものの /vendor 側にドライバが無く、正常にロードできないようだ。公称のOpenGLESバージョンは 3.2 。
SDKサンプルはそのままで正常にインストール / 起動できる。

Graphics APIとしてOpenGL ESを含めておけばUnityのプロジェクトもそのまま実行でき、PVRHub経由で起動すればプロファイルも可能となっている。
FireTV伝統のオンスクリーンデバッグインターフェースである System XRay はなんと 完全に日本語化 され、項目の拡充が行われている。(同じ機能はFireOS5を採用するデバイスでも使用できる)

System XRayはビデオCODECの状況を表示するデバッグ機能が有るなど、ストリーミングプレイヤとしての機能性にそれなりの配慮が見られる。

基本的にハードウェアCODECを使用すると常に表示されるため、例えばMiracast受信を行ってもちゃんとCodec情報やFPSが表示される。MiracastはWi-Fi directであるため、NETが空欄で表示される。
FireTV Stick 4K は最後のTVデバイスになるか?
- prev: https://mjt.hatenadiary.com/entry/20150926/p1
- ゲームプラットフォームとしてのスマートTV
Stick 4KはそれなりのパフォーマンスをStick型のフォームファクタで実現した。有線LANの無いシステムはこれが最終形なのだろうか。
依然RokuやAppleは4Kプラットフォームを箱型で提供しているし、FireTV Cubeのようなハイブリッドデバイスには依然席は有るかもしれない。しかし、microconsoleに始まる"インタラクティブな10-feet screenプラットフォーム"としては、Stick 4Kの実現している内容が最終形に見える。
今のコンテンツプロバイダが提供する、HDR 4K + Dolby Atmosコンテンツ以上のスペックのコンテンツがストリーミングプロバイダから出てくることは考えづらいし、Stadiaのようなインタラクティブストリーミング技術のリーチは今後それなりの人口に達すると見られている。これが意味する所は、(ゲーム専用機のような例外を除いて、) スマートTVのスペックは限界に達した という点だろう。
その限界に達したスペックは、カメラ処理や他の需要によって進化を続ける電話のスペックを微妙に下回った位置にあるため、スマートTV向けのインタラクティブコンテンツの状況はあまり良い位置に居ないと言える。
逆に言えば、スマートTV向けのアプリケーションについては強い省力化の圧力があるため、そこを埋めるようなテクノロジには需要があるかもしれない。インタラクティブストリーミングに掛かるコストと、スマートTVネイティブアプリケーションのコストには広いギャップが有り、そこに"タダ乗り"するようなプラットフォームが今後登場するのではないだろうか。
処理系間で共通にできるeval APIのサブセット
小ネタ。処理系毎にevalやそれに与えられる環境の機能性が微妙に違うので共通APIを考える会。
eval APIの移植性
Lisp、Schemeと言えばeval。JavaScriptや他の言語でもAPIとして存在するが、Lispではその場でS式を組み立てて使えるのでそれなりに利便性が高い。ただ、意外と移植性が低く、
- R6RS / R7RS標準には環境を操作する手続きが無い 。多くのSchemeでは
eval手続きに与える環境をfirst class objectとして扱い、それなりの数の操作APIを用意していることが多いが、これらが標準に含まれない。このため、任意のバインディングを環境に取り込むためには、事前にライブラリにしておく必要がある。 - そもそも環境を指定できない処理系がある 。Gambit等。
独自の環境操作手続きとしては、例えば Chez Schemeの set-top-level-value! が有り、yuniではGuile( module-define! https://github.com/okuoku/yuni/blob/96fa6edd7c0b2b6c97597c60ccf1a3314b73ace1/lib-runtime/selfboot/guile/selfboot-entry.sps#L142 ) やRacket( namespace-set-variable-value! https://github.com/okuoku/yuni/blob/96fa6edd7c0b2b6c97597c60ccf1a3314b73ace1/lib-runtime/selfboot/racket/selfboot-entry.rkt#L212 )で同じAPIを実装している。
更に、これらの手続きはマクロも操作できることが多い。例えば、MIT/GNU Schemeには environment-define-macro があり、任意の環境に対してマクロを導入できる。
... 大抵の処理系でこれらの環境操作手続きが使えるならyuniで互換層を提供しても良いかもしれないが、Gambitのように、そもそも eval が環境を取らない処理系ではどうしようもないため最大公約数を探す方向とした。
(eval expr [env]) procedure
The first parameter is a datum representing an expression. The eval procedure evaluates this expression in the global interaction environment and returns the result. If present, the second parameter is ignored (it is provided for compatibility with R5RS).
環境を取らないevalで環境をエミュレートする
実はすっごく難しく考えていて、これ実装できないんじゃないかと思っていたが、実は超簡単だった。 普通に環境を let に見立て、これを lambda に変換すれば良い。
よくある even? odd? の例を考えると、
(define (odd? i) (if (= i 0) #f (even? (- i 1)))) (define (even? i) (if (= i 0) #t (odd? (- i 1))))
を eval して、できた手続き odd? と even? を取り出したいとする。例えば、R7RSでは (scheme repl) ライブラリに interaction-environment 環境が規定されているのでそれを使って、
(import (scheme base) (scheme write) (scheme eval) (scheme repl)) (define env (interaction-environment)) ;; envはREPL環境を指す ;; REPL環境を破壊的に更新する (eval '(begin (define (xodd? i) (if (= i 0) #f (xeven? (- i 1)))) (define (xeven? i) (if (= i 0) #t (xodd? (- i 1))))) env) ;; 更新したREPL環境からxeven?とxodd?を取り出して使う (let ((xeven? (eval 'xeven? env)) (xodd? (eval 'xodd? env))) (display (list (xeven? 2) (xodd? 2))) (newline))
と書ける。しかし、 eval の引数に環境を取らないSchemeではこの方法は取れない( eval 間で環境が共有される保証が無いため)。代わりに、大抵のSchemeには define シーケンスと同等の効果を持つ letrec* 構文があるため、これに変換して、
;; このevalは作られた odd? even? の手続きを返す (eval '(letrec* ((odd? (lambda (i) (if (= i 0) #f (even? (- i 1))))) (even? (lambda (i) (if (= i 0) #t (odd? (- i 1)))))) (list odd? even?)))
のようにできる。つまり、 letrec* で束縛したものを、リストかベクタに纏めて、そのオブジェクトを受け取れば良い。
この定義された odd? や even? を使った式を eval したいときは、単に lambda に変換して、 eval からは一旦クロージャを受け取ることで実装できる。
(let ((proc (eval (lambda (odd? even?) ;; odd? と even? を束縛するためのクロージャを返す ;; ココの内容は上の例と同じ (display (list (even? 2) (odd? 2))) (newline))))) ;; 実際に呼び出す (proc xodd? xeven?))
この方法は環境に構文を導入することはできない という欠点は有るものの、環境を取らないevalで環境を取るevalと同様に手続きの定義や使用を行うことができる。
APIの実装
今回、この制約に従う eval を lighteval と呼ぶことにしてyuniのライブラリに導入した。lightevalはyuniがサポートしている処理系全てについて、環境付きのevalをエミュレートするためのツールを提供する。
eval プリミティブ
yuniでは、基盤となるScheme語彙として (yuni scheme) をライブラリとして定義している。ライブラリとしては この環境のみを eval の環境として保証し 、唯一の移植性のある eval 手続きとして提供する。R6RS/R7RSでは、このevalは以下のように定義できる:
(define (eval/yuni frm) (eval frm (environment '(yuni scheme))))
Gambitのように eval が環境を取らない処理系では、単に (define eval/yuni eval) し、実行環境に (yuni scheme) の語彙が揃っていることは別の手段で保証する。
この eval/yuni が唯一の移植性プリミティブとなる。(lightevalライブラリ自体は環境の表現にハッシュテーブルを使用するため、ハッシュテーブルも実装されている必要があるが。。)
環境オブジェクトとadd-globals!
環境オブジェクトとしてはハッシュテーブルを直接使用する。というわけで、 make-symbol-hashtable したものがそのまま環境オブジェクトとして使用される。
add-globals! は環境にグローバル変数を define するための手続きで、シンボル名と eval したいコードの連想リストを受けとり、その内容を letrec* に開いた上で eval/yuni して結果を環境に格納する。
(define (lighteval-env-add-globals! env alist) (let ((names (map car alist)) (code (map (lambda (p) (let ((name (car p)) (obj (cdr p))) (list name obj))) alist))) ;; lighteval-bind(後述) 手続きが、環境の内容を展開した上でeval/yuniを行う (let ((out (lighteval-bind env `(letrec* ,code (list ,@names))))) (for-each (lambda (name obj) (lighteval-env-set! env name obj)) names out))))
bind
環境内のシンボルを使用したコードをevalするには、bind手続きを使う。bind手続きは、環境を lambda に開いて eval/yuni し、更にevalが返したクロージャを apply した結果を返す。
(define (lighteval-bind env frm) (let-values (((k v) (hashtable-entries env))) (let* ((names (vector->list k)) (objs (vector->list v)) (proc (eval/yuni `(lambda ,names ,frm)))) (apply proc objs))))
... 名前が良くない気がする。
何の役に立つのか?
lightevalでは、全ての変数定義を明示的な add-globals! 手続き、または、環境を表現するハッシュテーブルのアクセスを通して行う必要がある。このような eval が何故必要かというと、 define-macro のexpanderをyuni上に実現するために必要になる。。
s7やBiwaSchemeのようなdefine-macroを使用した処理系で、パフォーマンスのため事前にマクロを展開した状態でyuniライブラリを提供したいという気持ちがある。この展開処理自体もyuniのプログラムとして書いてしまいたい。
yuniにはScheme-on-Schemeに実装されたVMがライブラリとして有る( https://mjt.hatenadiary.com/entry/20170525/p1 )ので、それを使えば eval をエミュレートすること自体は可能だが、それだとあんまりなので互換性を考慮した eval ラッパーAPIを用意し、処理系を生かす形でexpanderを実装したかった。
他の応用としてはREPLの実装が考えられるが、実用的なREPLを実装するためには例外の処理もどうにかポータブルに記述できるようにする必要があり、なかなか難易度が高い。
yuniのselfboot
もう当分Racket触りたくねェ... (後述)
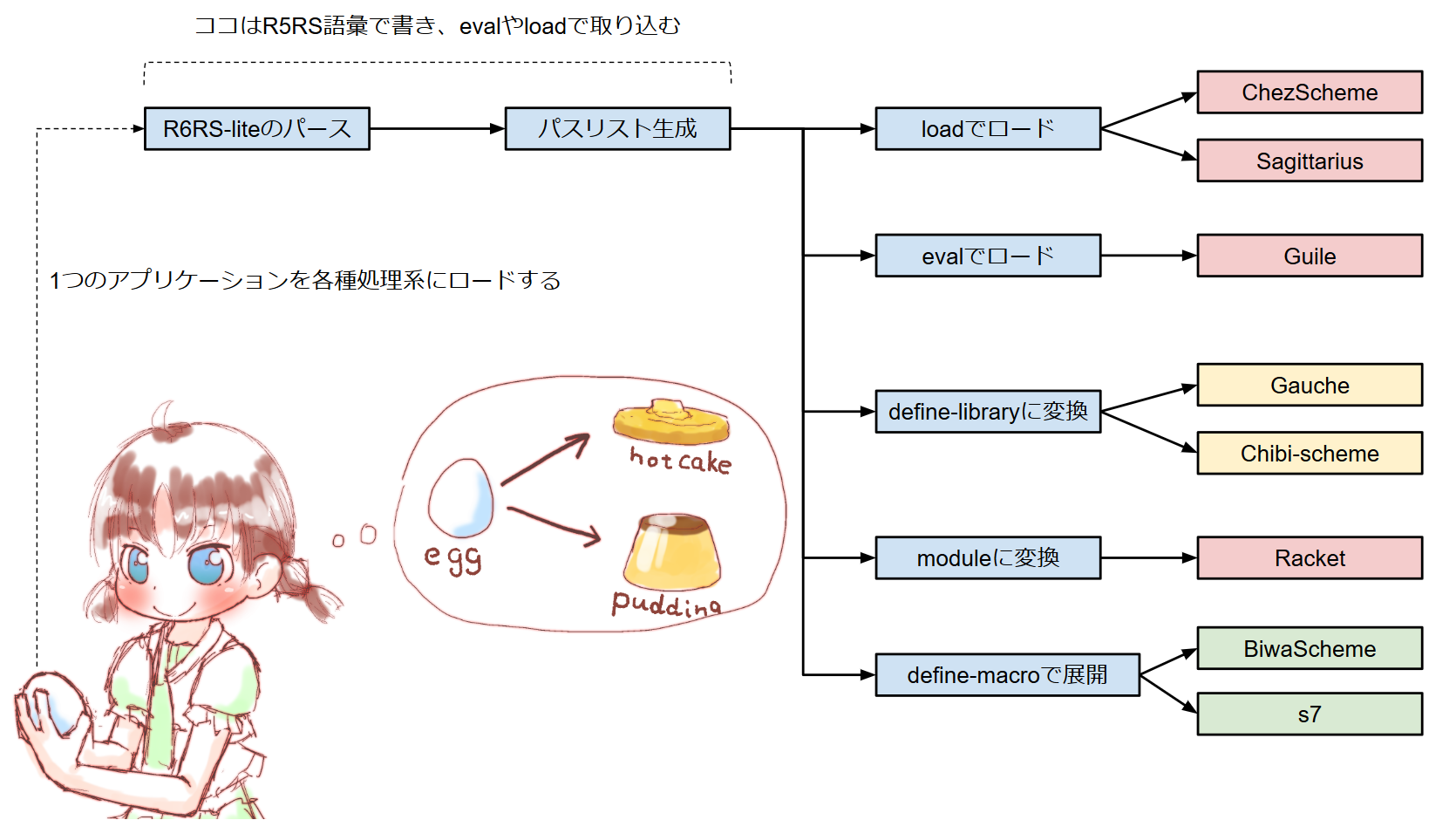
nmoshの互換ライブラリ層を分離した yuni は、どんなScheme実装でもR6RS風のライブラリシステムとR7RS-smallのサブセットを提供することを目的としている。で、従来はCMakeを使ったビルドシステムで一旦ビルドしないと使えないという微妙に面倒な仕組みになっていたが、"selfboot"と呼んでいる新しいbootstrapによって リポジトリをチェックアウトするだけで使える 状況を目指している。
もっとも、selfbootはyuniのbootstrap -- 普通のライブラリで言うところの"ビルド" -- と、簡単なテストのために使うことを想定している。特に、 selfbootはFFI互換層を提供しない ため、(yuni自体のビルドを除いた)実用的なアプリケーションをselfbootで実行することはスコープにない。例外的に、BiwaSchemeとs7ではselfbootが今のところ唯一のyuni環境になっている。
selfbootでできること
yuniのリポジトリに簡単なサンプルを置いた:
- https://github.com/okuoku/yuni/tree/6d968de0df1541ad63319be73aa11ccf8e450daf/samples/hellolib -- 簡単なサンプルプログラム
(library (A) (export A stxA) (import (yuni scheme)) (define-syntax stxA (syntax-rules () ((_ sym) (begin (display "stxA: Symbol ") (display 'sym) (display " value is: ") (write sym) (display "\n"))))) (define (test) (display "This is `test` in library (A)\n") 'A) ... )
のようなライブラリを使ったプログラムが、非R6RS処理系や syntax-rules の無い処理系でも同様のコマンドラインで実行できる:
- (Chibi-scheme - R7RS)
chibi-scheme ../../lib-runtime/selfboot/chibi-scheme/selfboot-entry.scm -LIBPATH . app.sps - (Gauche - R7RS)
gosh ../../lib-runtime/selfboot/gauche/selfboot-entry.scm -LIBPATH . app.sps - (Sagittarius - R7RS/R6RS)
sagittarius ../../lib-runtime/selfboot/sagittarius/selfboot-entry.sps -LIBPATH . app.sps - (ChezScheme - R6RS)
scheme --program ../../lib-runtime/selfboot/chez/selfboot-entry.sps -LIBPATH . app.sps - (s7 - Generic scheme)
s7yuni ../../lib-runtime/selfboot/s7/selfboot-entry.scm -LIBPATH . app.sps - (Racket)
racket ../../lib-runtime/selfboot/racket/selfboot-entry.rkt -LIBPATH . app.sps
(s7は単体の処理系が存在しないので、自前の s7yuni がyuniのリポジトリに収録されている。)
selfbootによって可能になるのは、yuniの基本ライブラリで構成された、R6RS風アプリケーションを適当なSchemeで起動できること。 ...たったコレだけでは有るけど、各処理系で微妙に異なるライブラリ構成や構文を無視して各種処理系で一発動作するのは中々に気持が良い。特に、s7のような素のSchemeからR6RS、R7RSまでをカバーしているローダーは多分他に無いんじゃないだろうか。SLIBとか他のライブラリと一緒になった奴は有るけど、インストール不要ではない。
しくみ
selfbootなyuniは、 load 呼び出し生成器 と要約できる。通常のScheme処理系は load 手続きでファイル名を指定すればライブラリをロードできるが、R6RSプログラムではライブラリ名は (rnrs) とか (yuni scheme) のようにシンボルで記述されるため、これを適当にファイルパスに変換してやる必要がある。
よって、
- プログラムを読み取り、依存ライブラリを収集する
- 依存ライブラリシンボルをパスに変換し、依存ライブラリの依存関係を再帰的に収集する
- ライブラリの依存関係をトポロジカルソートし、パス名をロード順に並び換える
- 処理系の
loadに渡し、ライブラリを実際にロードする
yuniではどの処理系でもyuniのライブラリを直接読み取れるように構文要素を注意深く選んでいる。このため、yuniのソースコードは基本的に処理系の read で直接読み取ることができる。...その後更に load するので2度読みになってしまうが。。依存関係の抽出等の処理は、各処理系に共通する語彙だけを使って共通のSchemeソースとして記述できる。
ただ、処理系の load が直接yuniのR6RS形式ライブラリを読み取れるのは 当然R6RS処理系に限られる ため、これができない処理系では load に相当する手続きを自前で実装している。この 自前で実装した load こそがselfbootの実装のキモ ということになる。
rationale
Schemeアプリケーションを書いている人にとっては、yuniの "ライブラリ書式はR6RS、語彙はR7RS" という組み合せに違和感が有るかもしれない。これには幾つか理由があって、
- ライブラリシステムは差し替えが難しいため、低機能な方に合わせる方が好ましい。つまり、R7RSの
define-libraryよりもR6RSのlibraryのほうがずっと低機能なので実装しやすい。 define-libraryは実装によって挙動がまちまちで使いづらい。例えばincludeフォームがライブラリパスを尊重するかどうかに標準が無い。このため、define-libraryはライブラリ定義と実装の分離を念頭にデザインされているものの、ライブラリ定義とライブラリファイルを同じディレクトリに置かないとうまく働かない。- R6RSの標準ライブラリよりもR7RSの標準ライブラリの方が普及している実装に合っている(既存のSRFIに素直な仕様になっていることが多い)。
selfbootを実装するまでは、R6RS処理系の一部(Chezやnmosh)だけがyuniのアプリケーションを直接起動することができた。これらの処理系では、単にライブラリパスにyuniのライブラリを追加するだけで直接R6RSプログラムとしてyuniのアプリケーションを処理できた。R6RS処理系全部をサポートできないのは、Racketのように #!r6rs を付けないとライブラリがR6RSとして認識されなかったり、Guileのように補助構文が束縛されていなかったりといった細かい違いによる。
selfbootの実装で、yuniをいちいちビルドしなくてもyuniアプリケーションが起動できるようになるので、もうちょっとyuni自体の開発効率が上がるんじゃないかという気がしている。
各種処理系でのselfboot実装
各Scheme処理系でselfbootを実装する方法は、処理系毎に異なる。...要するに、R6RSとかR7RS標準だけではyuniのselfbootは実装できないため、処理系固有の実装がどうしても必要になってしまう。。
selfbootの実装に必要なのは:
libraryに相当する構文をevalで処理すること- 後続の
evalで、事前にevalされたライブラリをimportできること
の2点で、おおざっぱに言えばREPL上で module とか library を定義し、使用するのと大して変わらない。
ChezScheme
- https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/chez/selfboot-entry.sps#L91
--
interaction-environmentによる環境定義 - https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/chez/selfboot-entry.sps#L94
--
loadによるファイルのロード
ChezSchemeのselfboot実装はそんなに難しくない。ChezではREPL用に interaction-environment が提供されるため、単にその環境をコピーして library でも何でも eval してしまえば良い。
yuniはR6RS形式のライブラリを採用しているため、Chez上では単純に load すれば良い。Chezの load は第3引数としてハンドラを渡すことができ、その中で eval することになる。
Guile
- https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/guile/selfboot-entry.sps#L92
--
interaction-environmentによる環境定義 - https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/guile/selfboot-entry.sps#L108
--
exportのフィルタ処理
GNU GuileはChez同様 interaction-environment を備えている。ただ、Guileは標準ライブラリ内部で補助構文を束縛していないため、 export 内で再エクスポートされる場合は取り除く必要がある。このため、 load のような直接ロードは使用できず、フィルタ処理が必要になる。
このようなソースコードの書き換えが必要な処理系では、構文情報が抜けてしまうため行番号情報等が無くなってしまうというデメリットがある。真面目に syntax-case で加工すれば多分何とかなるが。。
Sagittarius
- https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/sagittarius/selfboot-entry.sps#L95
--
interaction-environmentへのロード - https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/sagittarius/selfboot-entry.sps#L106 -- 処理系付属ライブラリの定義
SagittariusでもChez同様に実装できる。
selfbootでは、ライブラリパスの解決は自前の処理で行うことになるが、処理系付属のライブラリは検索する必要がないため事前に除く必要がある。SagittariusはR6RS/R7RS Hybrid処理系なため、R6RSライブラリとR7RSライブラリの両方が列挙されることになる。
Racket
これが本当に辛かった。。
- https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/racket/selfboot-entry.rkt#L114 -- R6RS read処理
- https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/racket/selfboot-entry.rkt#L200
--
module構文への書き換え - https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/racket/selfboot-entry.rkt#L146 -- R6RSのmutable pairからRacketのimmutable pairへの載せ替え
- https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/racket/selfboot-entry.rkt#L123 -- ライブラリlookupの実装
Racketは言語処理系の実装フレームワークとも言うべく充実を誇っているが、この手のhackを実装するのは本当に超クッソ激烈に大変でゼロから実装した方が早いんじゃないかという気がしてくる。
標準のR6RS実装はRacketの言語として実装されており、単体で流用することをあまり想定していないように見える。selfbootではreaderだけ流用し、Racketネイティブの module への変換は自前のものを実装している。このとき、何故か (quote id) 形式のライブラリ解決が quote: not a require sub-form と言われて使用できず( quote を再exportしているから?)、自前のライブラリlookupも追加で実装している。。
R6RSのreaderを使うには、 (require (prefix-in r6rs: r6rs/lang/reader)) のように r6rs/lang/reader を直接importし、このライブラリの read-syntax を使う。これによって読み取ったコードは自動的にRacketの module 構文に開かれるが、この module はRacketのR6RS実装に固有のものなので直接使い廻すことができない。今回は syntax-case で中身を取り出し、更に syntax->datum して構文情報を取り去ってから、改めて module を組み立てて eval している。
また地味なポイントとしてRacketでは cons 等の手続きが生成するペアはimmutable pairとなっており set-car! 等が使用できない。RacketのR6RS実装では自動的にmutable pairを使うが、これらには専用の mcar といった手続きを使う必要があるため、R6RSとRacketでやりとりするには変換が必要になる。ここではイテレータ in-mlist を使って (for/list ((y (in-mlist x))) y) で変換を済ませている。
多分Racketのプロなら syntax-case で直接実装できると思うがどうやってもreaderが作ってくるsyntaxを使いつつ module 構文だけ差し替えるということが出来ず、4時間くらい格闘した挙句諦めてしまった。。Racket標準のR6RS実装は R6RSライブラリがRacket的な意味でCollectionを構成する必要が有り 、yuniのようにR6RS / R7RSの両処理系から読み取れるという要件を同時に達成するのは不可能になっている。
chibi-scheme、Gauche
- https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/chibi-scheme/selfboot-entry.scm#L100 -- ライブラリ構文のみの環境定義 (chibi-scheme)
- https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/gauche/selfboot-entry.scm#L86 -- 対話環境の取り出し (Gauche)
- https://github.com/okuoku/yuni/blob/6d968de0df1541ad63319be73aa11ccf8e450daf/lib-runtime/selfboot/chibi-scheme/selfboot-entry.scm#L113 -- ライブラリの別名定義(エイリアス)
chibi-schemeでは、 define-library のようなライブラリ構文は "(meta)" と呼ばれる環境に入っているためこれを environment 手続きで取り出して使う。Gaucheでは current-module 手続きで現在の環境を取り出してそちらを書き換える方向で実装している。
chibi-schemeの include は何故か絶対パスを処理できないため、単にソースコードを read してそのまま quasiquote で直接突っ込みevalしている。...手抜きでGaucheでもまったく同じ実装にしている。
どちらの処理系でも、環境内に library 構文を定義してしまって直接 load するという手法は使えるはずだがまだ検証していない。
残件
- KawaやIronScheme等他の処理系での実装。
- ビルドシステムの移行。今はbootstrap schemeとしていくつかのR6RS/R7RS処理系を選び、それらに純粋なR6RS/R7RSで書いたビルドシステムを実行させているが、selfboot処理系に置き換えることでもっと多くの処理系をyuniのビルドに使用できるようになると期待される。
- R7RSやRacketで構文情報を捨てているのをやめる。
- OS情報などビルド時定数を何とかサポートできないか検討する。
実際に作ってみると、selfbootは何で今まで無かったんだろうという便利さで、もう毎回ランタイムをビルドしていた生活には戻れそうも無い。多分FFI互換層だけをCMakeでビルドするように替えて、Scheme側はCMakeでビルドするのを止めても良いんじゃないかと思っている。