ファイル更新に耐性のあるテキストタグ手法を考える
コンパイラの警告やシナリオのコメント、クラッシュレポートの処理等、"行の特定位置にタグを振りファイルが更新されても追跡したい"という需要がそれなりにある。...需要自体は有るんだけど、実装がバラバラになってしまっているので、ちゃんとモデル化し、フレームワークとして統一を図りたい。
行コンテンツとblame履歴によるアドレッシング
今回考えたタグのモデルは、ファイルを行に分割し、各行のコンテンツおよび初出現リビジョンのハッシュをアドレスとする。

このアドレッシングにより、ファイルが更新されたとしてもタグを頻繁に書き換える必要は無い。もちろん、行を書き換えた場合はハッシュ値が変わるためタグも"打ち直し"が必要になるが、それでも行番号を使用した場合よりも高い生存率が期待される。
これはblameにタグを付けるのと同じと言える。つまり、 VCS上の履歴を伴ったファイルにしかタグ付けできないし、タグを打つためには必ずblame情報を生成しなければならない 。(blameは一般にVCS上の履歴を集積したビューを指す。例: https://github.com/torvalds/linux/blame/master/Makefile LinuxのMakefileのSUBLEVELバージョンはLinux3.0以降変わっていない)
blameを常に生成することを考えると、ソースコードを行ごとにバラした状態でDBに格納するのが良いと考えられる。Gitを始め多くのVCSではファイル 全体 のハッシュを使用してファイルを管理することになるが、1段階間接参照を増やしてファイルを行ハッシュのリストで表現することで簡単なデルタ圧縮と行に対するID付けの両方を得られる。
タグをwhitespace文字に付与することは無いため、コンテンツのハッシュをwhitespaceを無視したものに対して取ることでwhitespaceの変更について"耐性"を獲得することもできる。この場合行データは本来の行とwhitespaceを除いたデータの両方を持たせる必要がある。
耐性モデル
ここでの"耐性"は、ファイルに付けたタグが "迷子" になりづらい、または正確に迷子と見做されることを指す。例えば、ソースコードをビルドした際に出たコンパイラの警告をタグとした場合、 ファイルを更新したとしても同一の警告が出つづけたならば同じタグと見做す 必要がある。この特性は、例えば警告が導入されてから解消するまでの期間を計測したり、ある特定の警告を無視対象として追加した場合の効力に効いてくることになる。
GitやSubversionのようなVCS上で管理されるファイルの更新にはいくつかパターンが有り、耐性もそれぞれのパターンに対して考えることができる:
- 行挿入耐性 : 特に、タグが付与された行よりも前に行が追加された場合、行番号はズレることになる。例えば、タグの位置情報として"ファイル名:行番号"の2アドレスを使用する方式は行挿入耐性が無いと言える。
- 行コピー/移動耐性 : ある行がファイル中の別の行にコピーされた場合に、タグがどちらの側に付いていたかを判断する必要がある。
- 行改変耐性 : 行の中に文字列が挿入された場合に、当該行に付与されていたタグが生き残る必要がある。また、逆に、タグが付与されていた位置が削除された場合はタグを(積極的に)迷子にする必要がある。Whitespaceの無視をすることで、whitespace変更に対して耐性を獲得することもできる。
- ファイルrevert耐性 : ファイルがrevertされた場合に、元のタグを復活させる必要がある。...これ自体は一般的な期待だが、真面目に実装するべきかは何とも言えない。
これらの耐性モデルを考えた場合、一般的な(例えばCTAGSに見られるような) "ファイル名:行番号:桁番号" のような3アドレス方式ではいかなる耐性も提供できないことはすぐにわかる。例えば、タグ位置よりも上位に行が挿入された場合は、それ以下のタグは全て無効化する必要がある。
単純なblame履歴によるアドレッシングも行挿入以外の編集には耐性が無い。このため、何らかのヒューリステイックや人力のアノテーションを使って異なるタグ同士を纏める手法が別途必要になる。逆に、これらに耐性のあるblameをデザインすることでアサインされるタグにも同様の耐性を付けることができる。
Subversion、MercurialとGitのセマンティクス差をどう埋めるか
ゲームのビルド環境には未だにSubversionやMercurialからインポートしているリポジトリがいくつか存在している(Perforceはついに撲滅に成功した)。しかし、細かいインフラを作っていく中でVCSはできれば統一したい。VCS毎にUIとかいくつも作っていられないからね。。
目標
"あるexecutableのあるバイトを生成する要因になったコードの作者をO(logN)で特定する"
当然ゲームには複数のオープンソースなりNDAしたミドルウェアが含まれるため、
- クロスリポジトリで複数プロトコルのVCSで構成される履歴を処理でき
- ソースコードの行とexecutableのバイトを関連付けることができるビルドシステムを持ち
- 外部プロジェクトの取り込みについて履歴をアノテーションできる
必要がある。全てをGitに突っ込めば(= monorepoを生成すれば)それなりに簡単だが、プロジェクトの規模が大きくなると非現実的になってくるので、在野のリポジトリをそのまま扱うために既存のVCSをそのまま扱えるフレームワークを考察している。
Subversion
Subversionはだいぶ考察が進んできていて、いくつかのFOSSリポジトリを使って実験を進めているところ。
SubversionがMercurialやGitと最も違うのは、そのリポジトリが 再帰的構造を取る 点と言える。普通、つまりGitのようなVCSであれば、リポジトリのルートが厳密に決定でき "リポジトリの履歴 == プロジェクトの履歴" と言える(プロジェクトが複数のリポジトリで構成されることは考えない)。
しかし、Subversionのリポジトリは再帰的であるため、"ツリーのどこを取り出してもSubversionリポジトリとして成立する"。つまり、:
- 任意のサブディレクトリをチェックアウトしてリポジトリとして使用できる
- 無関係なプロジェクトを単一のリポジトリに格納できる
- あるプロジェクトのブランチを自由な場所に作成できる
- 単一のコミットで複数のブランチを同時に修正できる
という特徴がある。どれを取っても比較的最悪で、例えばSubversion自身のリポジトリは、ASF財団の 100万リビジョンを超える Subversionリポジトリ https://svn.apache.org/repos/asf/ の一部を占めていて、Subversion自身の trunk (Gitで言うところの master )は subversion/trunk/ に位置している。 ...Subversionでは、こういうリポジトリの構造を人間が決めることができ、機械で自動的に検出するには、ある程度inferが必要になる。
(実際には、Subversionのリポジトリには単一のUUIDが有り、そのUUIDに紐付く静的なrootも1つに決定できる。ただし、このroot自体にはプロジェクト履歴という意味ではあんまり意味が無い。リポジトリの操作履歴では有るんだけど。)
1つのリビジョンで複数のブランチを変更するというのが妥当かどうかは何とも言えない。履歴をconciseに保つためにそのようなスタイルを好む人が居るかもしれないし、コミット単位のrevertができなくなるので避けるべきという意見も有るかもしれない。
DB実装のnmosh→MongoDB置き換えがやっと終ったので試しにRubyのGitミラー投入。最大fanoutは5でr35619 https://t.co/Lkwc15tVU3 https://t.co/uQ1rm1ADdI https://t.co/TSYstB0Fu3 https://t.co/7HokYAgkRu https://t.co/qu3oBhC9Dl https://t.co/rNbyAp6fa6 とr17460 の2つ。r66699 = 68303 commits. pic.twitter.com/tlE9RLLLht
— okuoku (@okuoku) 2019年1月3日
例えば、Rubyは1つの修正を複数のブランチに単一のコミットで導入していて、
- https://svn.ruby-lang.org/cgi-bin/viewvc.cgi?view=revision&revision=35619
- https://github.com/ruby/ruby/commit/af310963abb1ef737d52b29ec77f6598ac505472
- https://github.com/ruby/ruby/commit/9c3bf9bec4927510c881ee807de5d37026fa89a8
- https://github.com/ruby/ruby/commit/67166228c63983d98805846edcce4897f3eb9068
- https://github.com/ruby/ruby/commit/8acdd955f98cf6515da37f54b9f8003f224f9cb2
- https://github.com/ruby/ruby/commit/a4e76099bf44ae7d75bd24c3c8233d710e590fac
Subversionでは1つのコミットになっているものが、そのGitミラーでは複数のコミットに分散しているのがわかる。
文化的差異
Subversionリポジトリの文化的差異として挙げられるのは:
- 無関係なヒストリを単一リポジトリで扱う - Gitで言うと
subtreeマージのように、複数の無関係なツリーを単一のリポジトリで扱う傾向にある。例えば、OSのような大きなプロジェクトにはvendorブランチがあり、他所のプロジェクトのリリースをブランチ経由で取り込むために使用されることがある。 - コミットログにサブジェクトが無い - これはRCSやCVSから由来した文化と言えるが、コミットログに1行の要約を付ける文化が無い。このためUIの方で適当にコンテキストを抽出して表示する必要がある。
- 巨大ファイルをコミットしがちである - これはゲーム固有かもしれないがSubversionやPerforceのようなVCSを採用したプロジェクトはアセットの管理にもVCSを使う傾向がある。
- 空ディレクトリを扱える - ...CVSの反省だろうか。。ただしこの特徴はブランチを扱うために重要になる(後述)
- 独特のmergeinfo属性を使用する - Subversionにはリポジトリのマージを構造として持たず(= リポジトリの履歴は厳密に木構造となる )、UIヒントとしてmergeinfo属性を使用する。実際にはサーバ側でもmergeinfoを使用するがリビジョンが明確な親を複数持てるGitやMercurialとは異なっている。
vendorブランチの処理はまだ上手いソリューションが浮かんでいない。この問題はGitでもSubtreeマージや、外部プロジェクトの取り込みが課題として有りVCS非依存の問題として解くことになるんじゃないかと思っている。
コミットログの問題は、コミットのコンテキストを抽出するためにビルドリプレイを使用したアーティファクトの抽出(ソースコードとC関数の対応表をメタデータとして持つ)と、コミットログへの静的なタグ付けをサポートする方向で考えている。例えば、手元のRubyミラーでは
- ruby-redmine0: type: tag id: ruby-redmine url: https://bugs.ruby-lang.org/issues/NNNNN pattern: "[Bug #NNNNN]" - ruby-redmine1: type: tag id: ruby-redmine url: https://bugs.ruby-lang.org/issues/NNNNN pattern: "[#NNNNN]"
のように、コミットログに付与されるバグトラッカへのリンクを抽出してタグを打つことにしている。
巨大ファイルと空ディレクトリはどうしようもないので外部にメタデータリポジトリを持つことになる。
mergeinfoは単にヒントとして使うのが良いと考えている。Subversionの文化として、mergeはGitで言うところの cherry-pick に近く、それまでの履歴を全て包含することは保証していないことが多い印象がある。リリースブランチを持つプロジェクトでは、上記のようにcherry-pickやマージではなく別立てのコミットを実施することが多い。
ブランチ作成を追え!
SubversionリポジトリをGit風のセマンティクスで扱う上で最大の障害になるのは、 人間が自由に決められるリポジトリ構造を自動的に認識しGitリポジトリの構造に反映する 点となる。
もっとも、Rubyのような単一プロジェクトで単一のSubverionリポジトリを使っている場合は、標準レイアウトをそのまま使用できるので大きな問題にはならない( git-svn もそれを想定している)。問題になるケースは、例えば、個人がサブディレクトリを掘ってそれ以下にブランチを作ったりしているような大きなリポジトリの構造を良く認識することにある。
ブランチを自動認識する、とは、 ユーザが実行した svn copy コマンドをリポジトリの履歴から推論する ことと等価と言える。未だきちんと纏められていないが、いわゆるFOSSのSubversionリポジトリで svn copy をディレクトリではなくファイル単位で実行してブランチを作っている事例は発見できなかった。
gccのリポジトリをGitに変換するのにRAMが64GiBでも足りないみたいな話 https://t.co/7MSbukyhnj が有って、そんなに食うのかよと思ったけど、手元のツール(ChezScheme製)に履歴データ読ませただけで知らない間に10GiBくらい喰ってて、やっぱりでかいリポジトリのオンメモリ処理は難しい。 pic.twitter.com/WtvxdYfd9Z
— okuoku (@okuoku) 2018年7月16日
他のアプローチとしては、ファイル単位の履歴を全て追跡してツリー内の全ファイルで比較を行う手がある。ただ、これが必要なケースは皆無で、個人的には ディレクトリのコピーさえ追えばブランチは発見できる と結論している。そもそもディレクトリ以外も追跡するアプローチだと各パス毎に履歴情報を記録する必要があって、あまり現実的なコストで実現できない気がしている。
もちろん、 svn copy コマンドを抽出するだけではブランチの推論にはならない。COPYが発生するのは
- ブランチの作成
- ブランチ内でのファイルコピー
git-svnのようなツールが生成するブランチを超えたファイルコピー- vendorブランチからのコピー
といった要因があり、適切なヒューリスティックを使ってブランチの作成イベントを抽出する必要がある。簡単には "trunkのコピー、または、そのコピーのコピーはブランチと見做す" というものが考えるが、
といった例外的なワークフローが有るため一筋縄では行かない。
git-svn はブランチ内のファイルコピーを積極的にCOPYに展開するが、適切に設定されていない場合ブランチを超えたコピーをinferしてしまうことがある。
Mercurial
Mercurialの考察は始まったばかりの状態に有るが、SDLやUnityのような重要なミドルウェアがMercurialなので避けては通れないと思っている。
もっとも、MercurialとGitの表現力はかなり近く、Mercurial固有の機能(タグや名前付きブランチの履歴管理)はメタデータを別のリポジトリで管理することで代替できるためSubversionよりはシンプルでコンパクトに表現できるのではないかと考えている。
MercurialからGitへのミラーツールはHgGitやgit-cinnabar( https://github.com/glandium/git-cinnabar )が既にあり、これらは今回の目的に十分な機能性を持っている。よって、今回実装する必要があるのはメタデータの抽出部分だけになる。
メタデータの抽出
Subversionと同じく、メタデータを一旦テキストファイルに変換し専用のGitリポジトリに格納する形で管理したい。このためには、リポジトリに対してメタデータの 列挙 を行う。 Subversionでは svndump の出力をパースする形で行ったが、Mercurialでは割合スマートに実現できる。
- 0。 Bareリポジトリの生成
hg clone <REPOSITORY> hg checkout null hg pull
MercurialにはBareリポジトリの概念が無いが、単に hg checkout null することでworking directoryを空にすることができる。
- 1。タグ、ブランチのHEADの取得
hg tags --template "{node}\t{tag}\n"
hg branches --template "{node}\t{branch}\n" -c
Gitで言うところのコミットハッシュは {node} で表現される。Mercurialの名前付きブランチにはcloseの概念があり、 -c オプションで表示を有効化できる。
- 2。Changeset(リビジョン)の列挙
hg log -r "all()" --template "{node}\t{rev}\t{p1node}\t{p2node}\t{branch}\n"
Mercurialにはrevsetsと呼ばれる専用のクエリ言語があり、これで表示対象のリビジョンを選択できる。MercurialでのChangesetには親は高々2つまでであるため、p1nodeとp2nodeの指定で必要十分な情報を出力できる。
このコマンドは
8db358c7a09ac8827c384030ce80b4abb864465d 12532 af47ff0de5ab1ddd8dbf0e30dd982a23fa45ab5f 0000000000000000000000000000000000000000 default eb22f5f6d5a54b8f3d441fc1874e0e5ab0b09d7a 12533 8db358c7a09ac8827c384030ce80b4abb864465d 0000000000000000000000000000000000000000 default 682d9b5ecbedab90f0ddf647cd8124fdd39607c2 12534 eb22f5f6d5a54b8f3d441fc1874e0e5ab0b09d7a 0000000000000000000000000000000000000000 default edb58d9516563ac8a01d8a04a5c3ef1d19babf8f 12535 2560bdcf3130485c44409fe6bb04e87961a9af4b 0000000000000000000000000000000000000000 SDL-1.2 6472da23f3ef931c9694ee4602867bf25a69d5b8 12536 edb58d9516563ac8a01d8a04a5c3ef1d19babf8f 0000000000000000000000000000000000000000 SDL-1.2 8586f153eedec4c4e07066d6248ebdf67f10a229 12537 6472da23f3ef931c9694ee4602867bf25a69d5b8 0000000000000000000000000000000000000000 SDL-1.2
のように、ブランチを跨いだ履歴を表示できる。 12537 のような番号はリポジトリローカルのリビジョン番号だが、ローカルのコミットが一切無ければリモートのものと一致する。
- 3。Changesetのダンプ
hg debugdata -c 8586f153eedec4c4e07066d6248ebdf67f10a229
Changeset内容のダンプは、 debugdata コマンドで行える。(FIXME: logはmanifest(Gitのtreeオブジェクトに相当する)が出ない .,.?)
e6e2f259e0fb09741aa4c393d9aff7bcc35ee9a7 Patrice Mandin <patmandin@gmail.com> 1547389670 -3600 branch:SDL-1.2 src/audio/mint/SDL_mintaudio.c src/audio/mint/SDL_mintaudio.h src/audio/mint/SDL_mintaudio_it.S atari: Fill audio buffer with silence when too many interrupts triggered on same buffer
(manifest以外の部分はlogコマンドにテンプレートを与えることで出力させられる。)
$ hg log -r 8586f153eedec4c4e07066d6248ebdf67f10a229 --template "{author}\n{date}\n{desc}"
Patrice Mandin <patmandin@gmail.com>
1547389670.0-3600
atari: Fill audio buffer with silence when too many interrupts triggered on same buffer
リビジョンのマッチング
リビジョンのマッチングは、トポロジを考慮した方式やら色々試したが、殆どのケースで authorと時刻のペア によるマッチングが期待通り動作する。もちろんトポロジの一致をチェックする必要が有るが、 殆どのケースで人間は常識的な方法でコミットを実施する と裏付けられたと言える。
ただ、Subversionでは Authorのマッチ自体が一仕事 になる。というのも、Subversionは履歴にauthorのメールアドレスを一般に持っておらず、Gitミラー側に付与するメールアドレスとのマッチングを考察する必要がある。(SubversionはDVCSではないため、単一のユーザ名名前空間を持つ。対して、MercurialやGitはDVCSであるためメールアドレスを使用することでユーザのuniquenessを確保している。)
簡単な方法は、RubyのGitHubミラーのようにe-mailアドレスを git-svn 形式( <SVNUSER>@<SVN-UUID> )のままにすることが考えられる。GitHub(Enterprise)ではこの形式のメールアドレスもe-mailアドレスとして設定できるため、PGP署名のような機能を使わないならこれで十分と言える。
ミラーによってはe-mailを真面目に設定していることがあるため、この方法は万能ではない。
Mercurialについては、コミットオブジェクトの表現力がほぼ同じため、各コミットオブジェクトとMercurialのChangesetは1対1対応させることができる。
未解決の問題
現状の構成、つまり、 Gitミラー + メタデータを外部リポジトリで持つ という構造はそれなりの表現力が確保でき、かつ、実際にビルドシステムを廻す上でも運用上十分なことが多いというのが結論になりつつある。(もちろんプロジェクトによっては自身がSubversionのキーワード置換に依存していたり等100%の互換は無いが。。)
現時点で未解決の問題は、
- マージアノテーション 。blameを実現する上でマージ情報を良く処理するのは重要なことだが、同時に、マージ情報そのものが正しいかどうかを検証したり、不正なマージ情報を打ち消すといったアノテーションの付与が必要になるのではないかと考えている。
- 巨大ファイル 。
git-lfsに開くのが簡単な気もしているが、これを行ったリポジトリでgit-svnを使えるのかが未調査。 - Rename表現のアノテーション 。Subversionはファイルの移動/コピーをアノテーションできる。Gitはtreeという形でディレクトリ単位の抽象化を選択しているが、ファイル単位での処理にした方が良いかもしれない(1つのオブジェクトが複数のファイル名を持つモデル)
- リポジトリ間のマージ 。いわゆるVendorブランチのマージのような操作を表現するためのメタデータをどのように持つべきかは考察し切れていない。
あたりがある。
define-macro処理系をできるだけHygieneにする
追記: これsyntax-rulesに展開されるsyntax-rulesがダメなんじゃないかという気がする。もっとも、何度リネームしても実害は無い気がするけど。。
前回( http://d.hatena.ne.jp/mjt/20181209/p1 )、define-macro処理系上のsyntax-rulesでシンボルのリネームを実現するために __1 とか __2 のような予約シンボルを導入する方法を考えたが、既存のコードを書き換えるのは超たいへんなのでテンプレートの方を暗黙に書き換えるというインチキで乗り切ることにした。
とりあえず手元のアプリを分析したところ、lambdaとlet、defineさえ救えば十分なことがわかったのでそれらだけ救う対応を入れた。
救われるコード
lambda、let、defineでのbindingは暗黙にリネームされるようになった。つまり、
(import (yuni scheme)) (define-syntax out (syntax-rules () ((_ x code) ((lambda (a) (code a)) x)))) (define-syntax out2 (syntax-rules () ((_ x code) (let ((a x)) (code a))))) (define-syntax out3 (syntax-rules () ((_ x code) (begin (define a x) (code a))))) (define a 10) ;; それぞれsyntax-rulesの中ではaに20を代入している (out3 20 (lambda (b) (display (list a b)) (newline))) (out 20 (lambda (b) (display (list a b)) (newline))) (out2 20 (lambda (b) (display (list a b)) (newline)))
のようなコードがs7やBiwaSchemeでも正常に"(10 20)"を出すようになった。これは、例えば上記のdefineであれば、
(define-syntax out3 (syntax-rules () ((_ x code) (begin (define __1 x) (code __1)))))
のように暗黙に書き換えるのと同じ操作を実装している。
前提
この対応によって救うことができるのはletやdefineといった予約語がsyntax-rulesのテンプレート内に完全な形で出現している必要がある。つまり、
- letやdefineの定義を置き換えていない。yuniでは構文のリネームは許さない方向で制約しているが、依然letとかlambdaで別のものを束縛するのは合法となっている。今のところ、define-syntaxをトップレベル以外では許していない(= define-syntaxされる文脈は常にtop-levelなので他の構文がbindされようが無い -- (define let 10) とかしない限り)が、今後define-syntaxもスコープできるようにすると問題になるかもしれない。
- syntax-rulesテンプレート中に完全な形で構文を使用する。syntax-rules内のテンプレートを見てテンプレートを直接書き換える手法は、2段以上のマクロ展開を使った場合に成立しない可能性がある。letやlet*のような構文シンボルをマクロの外部から与えること自体は合法だが、今回のsyntax-rulesではこのようなケースでは内部でletが行われることを知りようが無い。
前者はともかく、後者はついうっかりやってしまいそうな気はする。
もちろん、処理系がdefine-record-typeとかその他bindをする非標準の構文を持っていたら、それぞれの対応を導入する必要がある。
実装
実装は、syntax-rulesのテンプレートをスキャンし、letとかdefineでbindされる位置にあるシンボルが有ったら、そのシンボルをテンプレート変数の1つとして昇格している。Generic runtimeではchibi-schemeのsyntax-rules実装を改造してsyntax-rulesを実装しているので、それをパッチする形で実装した。
- letとかdefineに対する、bindされる可能性があるシンボルを抽出する手続きをそれぞれ用意する https://github.com/okuoku/yuni/commit/19495050f7ea03e9f461be43a2007e6e925351d6#diff-6fc3666a46e36a52d314bb3257b9b2edR117
- expand-pattern に引数を追加し、テンプレート内でbindされる可能性があるシンボルのリスト(potential-binds)を渡せるようにする https://github.com/okuoku/yuni/commit/19495050f7ea03e9f461be43a2007e6e925351d6#diff-9e4667071efa1a5846f19ee88540ae32R272
- expand-pattern 先頭で、bindされる可能性があるシンボルのリストを map してそれぞれgensymしておく https://github.com/okuoku/yuni/commit/19495050f7ea03e9f461be43a2007e6e925351d6#diff-9e4667071efa1a5846f19ee88540ae32R198
- テンプレート変数を展開するときに、テンプレート変数のシンボルにマッチしなかったものをpotential-bindsと突き合わせて、マッチした場合はgensymしたシンボルに差し替える https://github.com/okuoku/yuni/commit/19495050f7ea03e9f461be43a2007e6e925351d6#diff-9e4667071efa1a5846f19ee88540ae32R217
現状の実装は処理系独自のscan手続きを追加することができない。
意義
ここまでしてsyntax-rules"風"の構文を使うことに何の意味があるのかというのは微妙な問題だが、これ(define-macroでエミュレートできるようにsyntax-rulesの機能を制約する)が今のところ各種Schemeでマクロを記述する最大公約数なのではないかと思っている。もちろんexpanderを載せて真面目にsyntax-rulesなりsyntax-caseなりを実装する手も有るが。。
完全にテンプレート展開のみに絞って明示的に __1 のようにgensym位置を書かせるのと、今回のように暗黙にリネームを挟むのとどちらが良いのかはなんとも言えない。ただ、個人的には暗黙にリネームを挟む方がUXとしては優れているのではないかと考えている。bindされるシンボルに意味のある名前を付けられるし、処理系が対応していればそれなりに見易いエラーを出力することもできる。
例えば、
(import (yuni scheme)) (define-syntax check (syntax-rules () ((_ temp) (define (temp in) (car in))))) (check check2) ;; 手続きcheck2を定義 (check2 10) ;; check2にペアでない値を渡す(エラー)
のようなコードをyuniのGeneric runtimeをloadしたs7で実行すると
;car argument, 10, is an integer but should be a pair ; check.sps[10] ; ; check2: (car {in}-16) ; {in}-16: 10 ; ((load prog)); ((cdr args*) (%%extract-program-args (cdr... ; ((set! %%selfboot-yuniroot "."))
のように、ちゃんと引数名が表示される。
syntax-rulesじゃなくてdefine-macroの方に寄せないのかよという意見も有るかもしれないけど、fomentのようにsyntax-rulesしかマクロを持たない処理系も有るし、何よりletくらい普通に書かせてくれた方が便利だし。。
"Generic Scheme"仕様を考える
yuniのBiwaScheme対応を進める上で用意した"Generic Scheme"仕様が意外と便利な気がしてきたので一般化してSRFI-96( https://srfi.schemers.org/srfi-96/srfi-96.html )のようなrequirement仕様にできないか考えてみる。
"Generic Scheme"はexpanderが簡略化されるぶんR7RS Smallよりも更に小さなScheme仕様になるので、syntax-rulesのサブセット実装をyuniに丸投げすることで簡単に市場の他のScheme処理系と共通のライブラリを使える環境を目指したい。
BiwaSchemeの制約
BiwaScheme( https://www.biwascheme.org/ )はJavaScript上に実装されたSchemeインタプリタで、R6RSの多くの手続きを実装している。(Bytevector等のバイナリ手続きは無いのでyuniでは専用のforkであるbiwasyuni https://github.com/yuniscm/biwasyuni/blob/0e5339ecbce44b148137070bfc7acf285da958b4/biwasyuni_core.js を使用している)
yuniは基本的にR6RS/R7RS処理系専用だが、GambitのようにAlexpanderを使って無理矢理サポートしている処理系もいくつかある。BiwaSchemeでもAlexpanderを使うことを考えたが、Alexpanderはちょっと遅いためBiwaSchemeの仕様に合わせて適度に規模縮小を図って実装することにした。
重要な制約には以下がある:
- syntax-rulesなどの健全マクロは無く、define-macroのみ備える。yuniのGambitサポートはAlexpanderを使って完全にexpandしてから処理系に渡すアプローチを取っているが、これはexpandのコストが掛かるため避けたい。このため、syntax-rulesを適当に制約を付けてdefine-macroで実現する( http://d.hatena.ne.jp/mjt/20180521/p1 )方向を取った。
- define-macroをトップレベルにしか書けない。Gambit等のdefine-macro処理系は通常defineとの混ぜ書きが可能で、let等によってスコープすることができる。BiwaSchemeではmacroはスコープすることができない。
マクロがスコープできないということは、let-syntaxが実装できないという点が問題になり得る。しかし、yuniでlet-syntaxを使っているのはidentifierと ... (ellipsis)の検出に使っているOlegのテクニック https://github.com/okuoku/yuni/blob/dcffed4556cdbccef46bba0a9c1198a8be2fe527/lib/yuni/base/match.sls#L566 くらいなので、ここだけライブラリ化してしまえば事足りる。
もっと直接的な問題は構文をリネームする方法が無い点が有るが、通常のシチュエーションではユースケースは無い、と思う。
これをユーザに見える制約にすると、
- define-syntaxはライブラリ/プログラムのトップレベルにしか書けない。手元のSchemeアプリだとたまにletの中でdefine-syntaxしているものが有り、そういうコードはトップレベルに移動してやる必要がある。マクロを使ってトップレベル以外で定義したものを挿入できないという制約とも言える。
- define-syntaxしているライブラリはトップレベルにしかimportできない。逆に言うと、define-syntaxを含まないライブラリは(let () ...)で囲むことでグローバル定義を汚さずにimportできる。Gambitやs7のようなdefine-macroをスコープできる処理系にはこの問題は無い。
- syntax-rulesは特殊なサブセット仕様となる。これはちょっと複雑。
syntax-rulesサブセット仕様
define-macroを使って、かつ、(letやdefineのような)組込み構文の知識無しでsyntax-rulesを実装する場合、どうしても避けて通れないバインディングの生成問題がある。syntax-rulesで新しいバインディングを導入する場合は、字面上の名前が同じであってもマクロが展開される度に新しいバインディングを生成しなければならない。
- Generic Schemeでは上手くいかないケース
(import (yuni scheme)) (define-syntax chk (syntax-rules () ((_ nam val) (begin (define tmp val) ;; ★ Generic schemeではそのまま "tmp" をdefineしてしまう (define (nam) tmp))))) (chk a 10) ;; (a) => 10 のはず (chk b 20) ;; (b) => 20 のはず (display (list (a) (b))) (newline) ;; ★ (20 20) を出力
ここで定義している構文 chk は、引数に指定した値を返す手続きをdefineするが、テンポラリなシンボルとして使用したtmpがそのままコードに出力されてしまうため、2回目の chk の使用でtmpが上書きされてしまい、Generic Scheme処理系ではうまく動かない。これはsyntax-rulesを適切に実装した処理系ではちゃんと (10 20) を返す。
(define-syntax chk (syntax-rules () ((_ nam val) (begin (define __1 val) (define (nam) __1)))))
そこで、Generic Schemeではsyntax-rulesの_ とか ... のようなリテラルに加えて、 __1 〜 __9 を予約して、tmpのような仮置きのシンボルとして使えるようにした。(R7RSやSRFI-46では ... を置き換えることができるが、__1 〜 __9 を置き換える方法は提供しない。) これは内部的にはよくある gensym 手続きを呼び出すだけとなっている。
... たぶん、letやlambdaのような標準のbind構文は全て自動的にこれらを置き換える機能を用意してあげた方が良い気はしている。現状だと
(lambda (a) a)
のような記述をsyntax-rules内に書く場合、
(lambda (__1) __1)
のように書き換えてやらないと、マクロ展開の外で識別子 a がbindされていた場合に意図せずマスクしてしまう。
- 上手くいかない例
(import (yuni scheme)) (define-syntax out (syntax-rules () ((_ x code) ((lambda (a) (code a)) x)))) (define a 10) (out 20 (lambda (b) (display (list a b)) (newline))) ;; ★ やっぱり (20 20) と出力される
- 手動で書き換えた例
(define-syntax out (syntax-rules () ((_ x code) ((lambda (__1) (code __1)) x))))
通常の展開器実装では、define-syntaxした位置で出力テンプレートがbindされていなければ適宜リネームという戦略を取ることができるが、今回はdefine-macroを使う縛りなのでsyntax-rulesの側にlambdaとかletといった標準構文の知識が必要になる。
Generic Schemeの意義
こんなサブセットをしてまでdefine-macro処理系を取り込む必要が有るのかはちょっと何とも言えないが、ちゃんとしたライブラリのサポートとsyntax-rulesの実装は意外と面倒で、かつ、どうしても処理系のバリエーションを増やしてしまうので、それをyuniに丸投げして処理系本体をコンパクトにできるなら言うほど悪くないんじゃないかという気がしている。
今のところGeneric Schemeターゲットになり得るのは:
- s7: https://ccrma.stanford.edu/software/snd/snd/s7.html
- BiwaScheme: https://www.biwascheme.org/
- Gambit: https://github.com/gambit/gambit
あたりが有る。Gambitにはpsyntaxベースのsyntax-rulesが有るが、Gambit本体のマクロ展開器とよく連携しないので、直接Gambitのマクロ展開器を使うにはGeneric Schemeのようなアプローチが必要になる。
もちろん上にライブラリシステムやexpanderを被せてこれらの処理系をちゃんとしたR7RS処理系にすることも不可能ではないと思うが、処理系本来のdefine-macroとマクロ展開器を活用した、可能な限り薄い互換レイヤというのも方向性としては有りなんじゃないかと思う。すくなくともこの3つとも非常に魅力的な処理系で、syntax-rulesが無いからといって非サポートにするのは非常に惜しい。
プリチャンはどこに向うか

桃山。
前回( http://d.hatena.ne.jp/mjt/20180401/p1 )の予想は新加入キャラが紫ってのしか当たってない!しかもクロスオーバーは初年度である今年からゲームの方で展開されている。VTuberはアイカツがやった( http://nlab.itmedia.co.jp/nl/articles/1806/07/news141.html )けどストーリーキャラクタではない。マイルームは"プリ☆チャン わちゃわちゃ会"としてコミュニケーションパートが実装されたがチーム構成がephemeralなのは変わっていない。宇宙はモチーフとしてアニメに登場しているが、さすがにもっと現実的な方面の切り方となった。
来年どうすんのかというのは非常に難しいところで、"キラっと"だけ替えるのかタイトル総替えか。。個人的には総替えすべきと思うけど。。
うまくいっていると思うところ
プロジェクト全体のコスト効率はかなり改善されたと感じる。
アーケード筐体はプリント筐体になっているが、このプリントはおそらく40〜50円/プレイのコストが掛かっていてこれを無くすことはできないので、どうしても開発や運用のコストを削ることでの利益確保になる。プリパラでは各キャラクタ毎に筐体オリジナル曲を制作していたが、プリチャンではこれを原則的に廃し、"歌ってみたシリーズ"としてインフルエンサー(乃木坂46)、LOVEマシーン(モーニング娘。)のカバーを制作している。...なぜこのラインナップになるのかはちょっと解らないが、アニメ楽曲がavex制作なのに、こちらはSMEの楽曲というあたりに事情を感じる。
コーデはブランド推しをやめて2チーム両方に同じものを着せ、更に限定カラーなどを駆使してバリエーションを出している。パーツや楽曲、モーションも含め相当量のアセットは前作プリパラからの再利用で構成されており、物量感を出すことにはある程度成功していると思う。
おもちゃ類はなんと1種に抑え、タカラトミー(!= アーツ)として出しているおもちゃ(カード/収納除く)はプリチャンキャストただ一種、しかも過去のシリーズとは異なりデジタルトイではない。筐体連動も印刷されたコードのみ。
運用面でも重篤な不具合(cf. http://nlab.itmedia.co.jp/nl/articles/1812/06/news115.html )を出すこともなく比較的おだやかに進行した印象。プリパラでは雑誌付録のコードがredeemできない等課金系の問題が見られたがシステム側の成熟があるのかもしれない。クラッシュ等のソフト品質はデータが無いので謎。
好みの問題
個人的にはプリチャンのデザイン方面は絵が若い感じというかなんというかフレッシュで良いと思っているけど、世間的にはあんまりそういう評価を聞かないので感覚がズレてるかもしれない。
アニメも当初見られた暴力的な傾向は鳴りを潜めていて日曜朝らしい良いアニメになっていると感じる。ただ、一貫した目的の無いドラえもんのようなアニメで良いのかというのは否定的意見が多い印象がある。
うまくいっていないと思うところ
着地点の無いコンテンツは売りようが無いのは前回ので散々書いたけど、それ以上にプロモーションが不味いんじゃないかという気がする。たとえば公式YouTubeチャンネルの登録者数は1万程度で、アイカツの公式チャンネルの1/10以下となっている。開設期間や視聴層(= 国籍など)の差は有るものの、予測されるプレイヤー数にここまで差は無い。公式の略称で"プリ☆チャン"(間に☆を入れるぶん検索性が低くTwitterのようなSNSでのトレンドになりづらい)を使うといった小さな問題から、そもそもIPホルダーの分散がそのままコミュニケーションの分散になってしまっているという大きな問題まで、さまざまな問題を解決していく必要がある。
コスト面の努力は感じるが、逆に言えば"そこまでしないと生き残れないのか"というのが正直な感想でもある。...まぁそれでもアイカツフレンズよりは贅沢を感じるし、オトカドールに至っては今年はアップデートが無いし。。
シリーズはどこに向うのか
まったく良いアイデアが無い。ハイターゲット(いわゆる大型女児)向けに営業を続けるのか、プリパラのようにもっと低年齢層に振るのかは決断が要るポイントだけど、正直リスクを取ってまで営業を拡大することを支持できるポイントが無い。
アニメキャラクタの商売はプリティーオールフレンズとして主に筐体外で展開している。逆にマイキャラの商売は(グッズ販売は設定されているものの)筐体内に閉じているので、展開のしようは有るかもしれない。プリチケメーカーのようなアプリは過去に展開していたので、同様にWebサイト等外部でマイキャラを作らせて誘引するなど。
マイキャラの音声は当初ボーカロイドを使うことが企画されていた( https://twitter.com/SHINOHBA/status/976571267942834176 )など、まだまだマイキャラのシステムには技術的制約で構想を実現できていないポイントが数多くあり、技術的なブレークスルーによって"ウリ"が産まれる可能性は大いにあると考えている。アニメキャラクタと同じプラットフォームで活躍するマイキャラの存在はコンテンツとの新たな関わり方になる可能性がある。
逆に言えば、これらの技術的なブレークスルーを取り入れていないうちは、新規のコンテンツが入り込むスキのあるニッチが存在すると言える。例えば変身前のマイキャラを含めた2世代キャラクタの実装には衣装のスケーラビリティを実現する必要があるが、そのためには衣装のあらたなオーサリング方法論が必要になる。
Anker Soundsync A3341
- https://www.ankerjapan.com/item/A3341.html
- 製品サイト
- https://k-tai.watch.impress.co.jp/docs/column/todays_goods/1139433.html
- ケータイWatchの製品レビュー
AptX sink機器が手元に無いので購入。Windows10以降は標準でAptX codecがシステムに搭載されているのでAptXで再生された(2回点滅)。
光デジタル入出力を備えていて、光デジタル機器を無線化する用途に使える。また、アナログ入出力も備えている -- 説明書には"AUX input"としか記載されていないライン入力端子は実は出力にも対応しており、ケータイWatchのレビューにも有るように適当なスピーカーを無線化する用途にも使うことができる。ただし、充電しながらの使用を推奨していないので設置用途に向かない。ヤマハYBA-11( https://jp.yamaha.com/products/audio_visual/accessories/yba-11/index.html )とかelecom LBT-AVWAR700( http://www2.elecom.co.jp/products/LBT-AVWAR700.html )みたいにBluetoothのデジタルレシーバって存在しないわけでは無いんだけど。。
説明書記載の点滅回数とCODECの対応は以下のようになっていて、
- 1 SBC
- 2 AptX
- 3 AptX LL(LowLatency)
- 4 AptX HD
- 6 AAC
なぜか5番が無い。
S/PDIF出力周波数はBluetooth側の入力と一致。手元の環境では44100Hzでの出力になる。バッテリ駆動の製品だけあって比較的真面目に出力制御を実装していて、PCのS/PDIF入力で聞くと曲間等でノイズが入る(出力が途切れる?ためと考えている)。例えばAUXに入出力デバイスを接続した場合はちゃんとS/PDIF出力は消灯する。
持ち歩きを想定したバッテリ搭載だけど、ちょっとその意義はわからず。入出力ともにマルチペアリングは2台まで、同時処理は1台のみなのでシェアリングには使えないし、公式サイトの画像だって明かに据え置きで使ってるし。。
AptX codecは既にAOSP( https://android.googlesource.com/platform/system/bt/+/3a3ec66a1bb7f5c99b17239021d6d184a3abd4ee%5E%21/ )やffmpegに入っている( https://patchwork.ffmpeg.org/patch/5879/ )。
オブジェクトベースオーディオのためのE-AC-3拡張の規格書を読む
Dolby AtmosのようなオブジェクトベースオーディオをSTBで動作するアプリから出力するにはE-AC-3くらいしか現状選択肢がない。E-AC-3(いわゆるDolby Digital Plus)上のJOC(Joint Object Coding)は一応AppleTVとAmazon FireTVの両方がサポートしている。
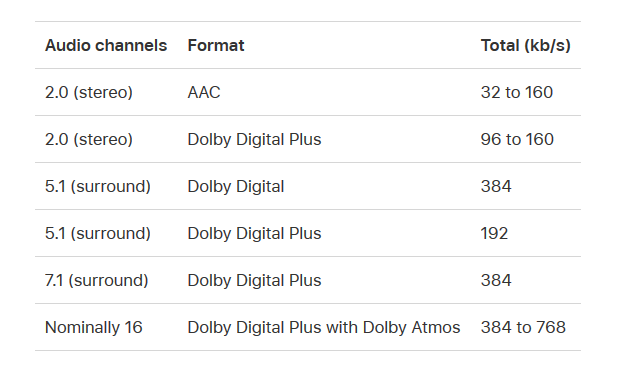
"Nominally 16"(16チャンネル相当)って微妙な表現だな。。
で、このDolby Digital Plus上のオブジェクトオーディオは一応標準化(ETSI TS 103 420)されていて、Dolbyのかなり簡潔なKBにURLが有る。
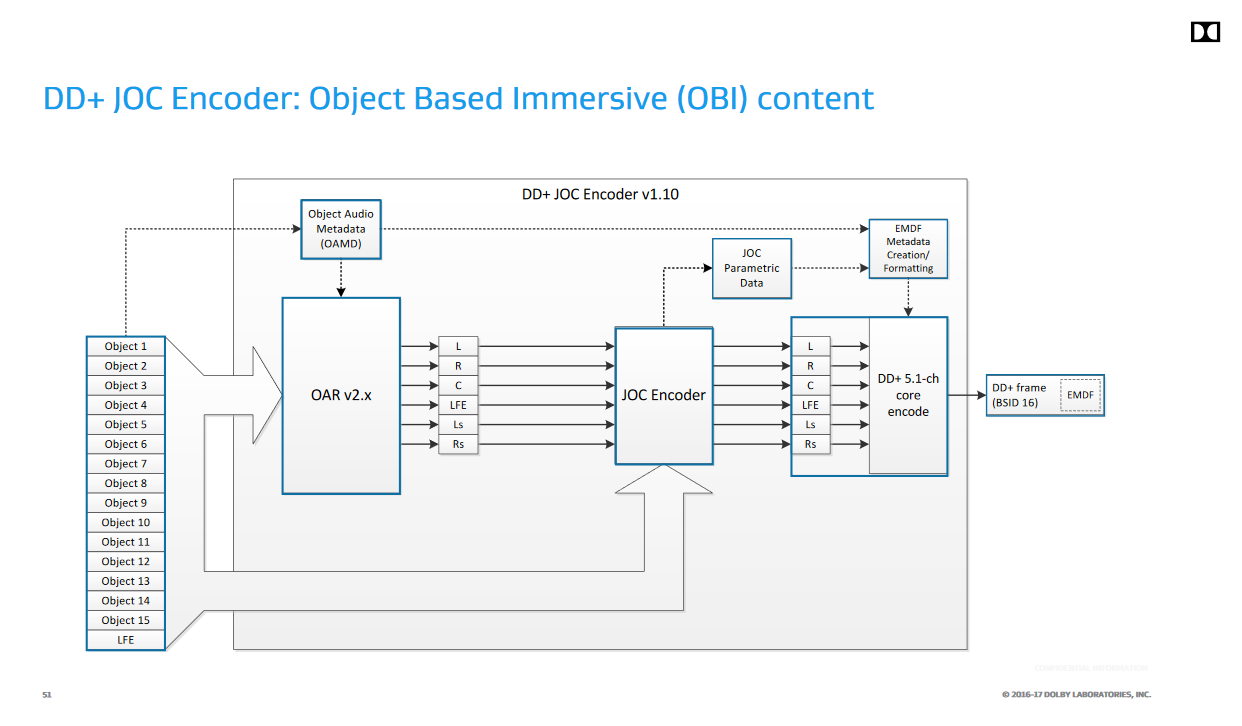
いきなりコレを読むよりも、AESでのDolbyの発表スライドにある図を見た方が良い気がする。
(エンコーダ)
(デコーダ)
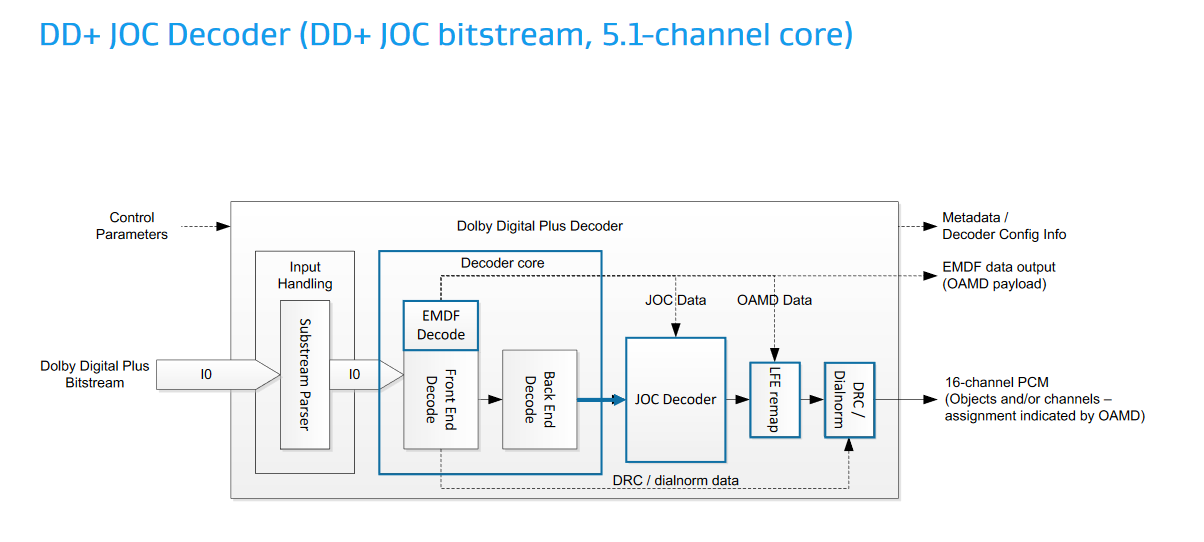
規格は図中の、OAMD(Object Audio MetaData)やJOCの仕様を規定している。この図では16 chを出力するように書かれているが、規格自体は最終的なスピーカーマッピング等は規定していないので、もっと多くのPCMチャンネルにデコードする実装も考えられる(一般家庭に16個以上スピーカーを置くのは非現実的だが、バーチャルサラウンドではずっと多くの仮想スピーカーを使用できる)。要するに元の5.1 / 7.1ストリームを16とかそれ以上の数のオブジェクトに"拡張"するのがJOCで、ETSI TS 103 420は16chのストリームを直接扱えるようにAC-3を拡張するわけではない。
オブジェクトのプロパティとしてはSizeがWidth、Height、Depthの3値を持つ直方体で規定されるのが目を引く。全てが0なら点音源、1なら無指向でリスニングルーム全体を占めるサイズの音源ということになる。
... これ直接Ambisonicsとかを伝送できるようにした方が良くない。。?何か特許を採用する必要があったとかでどうしてもJOCを採用しなければいけない事情が有ったのかもしれないけど。。JOCによって各オブジェクトの特徴量として出てくるのはQMFフィルタバンクの係数マトリクスなので、オーディオエンジンはオブジェクトの位置だけでなく各チャンネルへのダウンミックス係数やオブジェクトの元波形やミックス先から抽出した各サブバンド毎のゲインを保持しておく必要がある。そこまで複雑なデータを用意するなら、最初から7.1ミックスとヘッドホン用のミックスに絞った方がマシだな。
一応この規格ができたのが2016年で、そろそろFOSS実装が有っても良さそうなもんだけど、MediaInfo( https://mediaarea.net/en/MediaInfo )のライブラリ( https://github.com/MediaArea/MediaInfoLib )がフォーマット情報の表示に対応しているくらいで、デコーダやエンコーダは未だ無いようだ。