SURFを読む の0
- http://www.vision.ee.ethz.ch/~surf/papers.html - 本家
- http://opensurf1.googlecode.com/files/OpenSURF.pdf - Implementation note
下のPDFを理解するのに十分な量を書けたらという感じで。
SIFTやSURFの仕事
SIFTやSURFの最終的な仕事は、"スケール(大きさ)と回転に対して不変な特徴量を求めること"。
コンピュータにデータを比較するためには、データを(複数の)数値 = 特徴量に変換してやる必要が有る。
人間にとっては、ある画像を拡大縮小したり回転させたりした画像も"同じ"画像なので、特徴量も回転や拡大縮小の後も同じである(あまり変化しない)ことが望ましい。
構造
一般的にSIFTとかSURFといった名前で参照される仕事は、(キーポイント,特徴点の)"Detector"と(特徴量の)"Descriptor"で構成される。どっちも重要だが、大抵アルゴリズムの名前になるのは後者。
これらのアルゴリズムが研究される背景には異なる2画像間でのmatchingが有るが、それはまた別の話(RANSACとか)。
SURFの重要な特徴はDetectorとDescriptorの両方に対してIntegral Imageを適用できるアルゴリズム(一種の近似)を選択している点。もっともSIFTにもIntelgral imageを適用できる近似が提案されている。
| (alg.) | SIFT | SURF |
| Detector | DoG | Fast Hessian |
| Descriptor | SIFT | SURF |
といった感じ。DoGはDifference of Gaussianの略。SIFTチュートリアルを参照のこと。
Detectorの仕事
Detectorはいわゆる"特徴点の抽出"に使われる。もっとも、これらのアルゴリズムでは点ではなく画像を分割し一部分を抽出するくらいに考える方が良い。
一般によく理解されているのはSUSANオペレータのようなコーナ検出で、画像中の"角"に相当するコントラストの急峻な変化点を検出するもの。角同士を対応付けることができれば、移動する物体を追跡することも不可能ではない(やめといた方がいいと思うが)。
もっとも、SIFTやSURFで使われるようなDetectorは特徴点の大きさも情報として持つという重要な特徴が要求されている。
Detectorの仕事は2つに分割して考えることが出来る。
- 特徴点となる点の候補 = コントラストが変化している点を探すこと
- 特徴点の大きさを求めること
もっとも、SURFもSIFTもDetectorが一撃でこれらの操作を行うようにデザインされている。
特徴点の大きさを求めるためには"スケールスペース"が使われる。
一般的な特徴点抽出のしくみ
まず、一般的な特徴点抽出のしくみに関して知る必要がある。
特徴点抽出アルゴリズムというのは、基本的に"画像の変換"でしかなく、そこから適当な閾値や極大値を探すことで初めて点になる。
簡単のために一次元で考える。
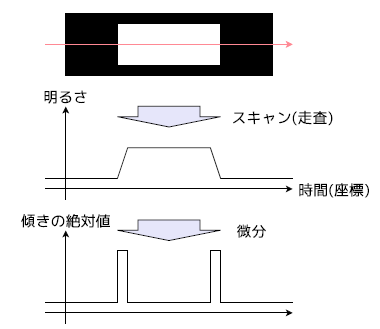
もし、このような波形(白い四角形の上を走査して得たと考える)の境界点を求めたいのならば、微分して極大点を取れば良いことがわかる。これによって分かったのは"特徴点の時間的(空間的)な位置"と言える。
さて、求めたい"特徴点の大きさ"を言い換えると、"特徴点のスケール的な位置"ということになる。これは端的に言えば画像を拡大縮小することによって考えることが出来るが、諸般の事情でいわゆる"ガウスぼかし"をつかう。
様々なガウスぼかしの強度によるぼかした画像についても画像を変換し、極大値をとることで特徴点のスケールとする。
これらの変換は基本的に畳み込み(convolution)で記述されるため、たたみこみ"される"画像側をぼかすこともあれば、たたみこみ"する"画像側をぼかすこともある。