SECDV Schemeの実装 - メモリ管理の基本設計
多分Scheme処理系を作る上で面白いパートの上位3位くらいには入るであろうヒープの設計に入る。
今回もとりあえず動くものを作ることに集中するため、パフォーマンスに関する考察は基本的に後回しにする。
制約と割り切り
今回の企画では最終的に"高級言語上で悪くない速度のScheme処理系を実現してプラットフォーム間でスクリプトエンジンを共通化する"ことを目的としている。このため、どうしてもパフォーマンス的な面ではベストでない実装を採る必要が出てくる。要するにプラットフォームのJITやAOTも進化しているので大して遅くないだろうという期待が有る。
ここでは"ホスト言語"という概念を導入している。ホスト言語は、CとかC#とかJavaのような高級言語を指す。...Cはちょっとココで言うところの高級言語の定義からは外れている気もするが気にしないことにする。
常識的なScheme処理系と大きく違いそうなのは以下の点:
- ヒープは32bit整数のvectorで表現される。ホスト言語は効率的な整数配列の機能を備えていると期待している。例えば、Scheme的なPairは32bit配列の2要素、VectorはN要素で実現されることになる。
- 浮動小数点数は専用のvectorで表現される(プール)。ホスト言語は効率的な浮動小数点数配列の機能を備えていると期待している。大概の言語は浮動小数点数と整数や他のオブジェクトを同一の位置に格納できるが、BASICのようにコレができない言語も存在するため、分離する。
- その他のオブジェクトも専用のvectorで表現される(これもプール)。例えば文字列とかbytevectorがコレに相当する。実際のベクタの分け方はホスト言語の仕様に依る。Cであれば大体のオブジェクトはmalloc()で確保されるただのポインタだが、文字列に専用の考察を持っている言語では専用の文字列型が使われるかもしれない。
- マークビットは専用のbytevectorで管理する。chibi-schemeのように、マークビットをオブジェクトの方に持たせている処理系の方が多い気がするが、通常のホスト言語には当然"文字列オブジェクトにマークビットを立てる機能"みたいなのは存在しないため独自の管理が必要になる。
- internされたシンボルはGCしない。シンボルは生成順に番号を振り、単にハッシュテーブルに詰めていくだけにする。面倒なので。。
- 整数の上位ビットでタグ付けする。通常の処理系は"ポインタの下位2ビット程度がゼロ"という事実を使用して下位ビット側にタグを入れている印象がある。ただ、今回はホスト言語にビット演算が有ったり無かったりする都合でタグを上位に置いている。上位のタグは抜去に引き算が使えるが、下位のタグは除算が必要なため。言い替えると、数値として使用される箇所をシフトしない。
IronSchemeとかKawaのような真面目なManaged処理系は、そもそもGCを自前で実装せずにホスト言語のオブジェクトシステムに任せている。まぁ常識的に考えて普通そうするよな。。
整数ヒープ(fixnum heap)
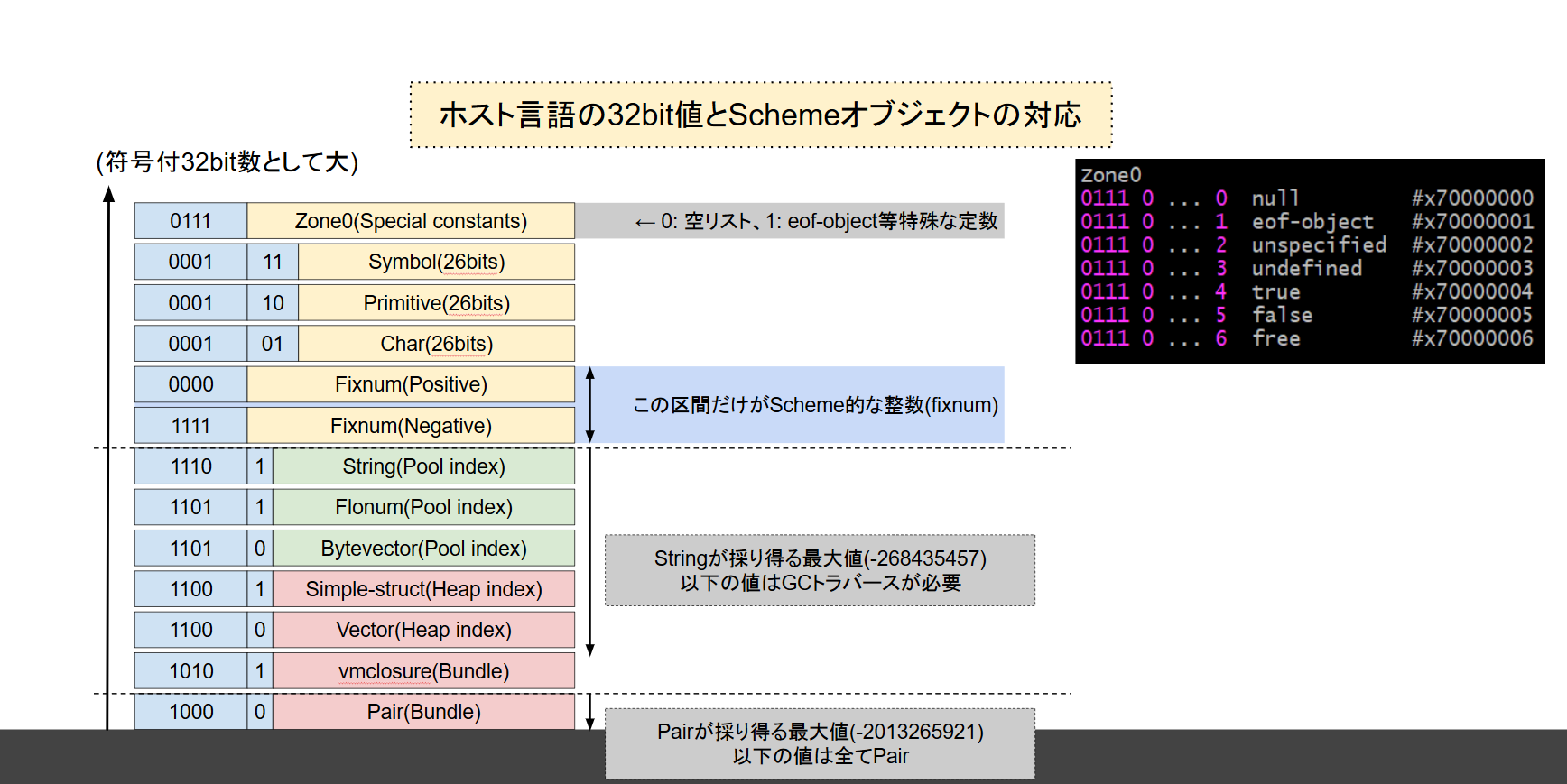
ここで言う"整数ヒープ"とは、Schemeのヒープをホスト言語の整数の配列で表わすことを指す。常識的なプログラミング言語では大体整数として符号付き32bit数をフルに使えるので、整数の巨大な配列をヒープに見立てて、その上にオブジェクト機構やGCを実装していくことになる。
(実際には、JavaScriptやGameMakerのように数値の内部表現がdoubleしかない言語も存在する。もっとも、JavaScriptにはTypedArrayが有るし、GameMakerにはbufferが有るため一応逃げ道は有るはず。)
当然、32bit全体を本来の整数、つまりfixnumに割り当てることはできず、どうしても切り崩して使うことになる。今回のエンコードでは整数には28bitを割り当てているため、処理系が直接扱える整数は-268435456 〜 268435455の範囲となる。整数以外のデータにはインデックスが埋め込まれる。埋め込まれるインデックスには以下の5種がある。
- vector等: 整数ヒープ内部を指すインデックス。
- pair等: "バンドル"の内部を指すインデックス。これはvector同様に整数ヒープ内部のインデックスということになる。
- string等: "プール"のエントリを指すインデックス。これは整数ヒープ内部のインデックスではなく別途確保した配列のインデックスになる。基本的にホスト言語のオブジェクトを操作する必要が有る場合に使う。
- char等: 単なる識別用の整数。
更にeof-objectやtrue、falseのようにインデックスを一切持たない値も存在する。例えば、数値 0x70000004 は整数としての 1879048196 ではなく、true(#t)として扱う。ホスト言語には 1879048196 として見えるので、true?手続きはこの値との比較で実装できることになる。
以降、整数ヒープの配列の要素をwordと表記する。wordは整数ヒープ内部以外にも、VMのレジスタやグローバル変数としても使用されることになる。
wordの設計
wordは28ビットまでの整数は直読できるように空けている(マイナス方向のデータも直読できるように配慮する)。これにより、残りの自由なビットは4bitになる。
...流石に4bitでは処理系の型を表現するのには不足なので、アドレス範囲を27bitsに減らし、型の表現には5bitsを確保する。このため、ビット演算の無い処理系では、あるwordの型を特定するのに7回(fixnum判定のために2回、型ビット5つ)の比較が必要になってしまう。。ランタイムではメモ化なりなんなりの方法が有るからどうでも良いが、この点はGCのトラバースコストに直接掛かってくる。
GCのトラバースコストを抑えるため、型ビットはトラバースが必要かどうかを早期に判別できるようにビットの割り振りを行っている。ここではヒープへのポインタを含む型を符号付32bit数の下の方に集め、ある値以上ならトラバース不要となるようにアサインしている。
また、特に数の多いpair?の判別を比較1回でできるように、pairをもっとも"外側"に配置している。整数は正負がありどうしても2箇所になってしまう(C言語のようなunsignedはホスト言語に有ったりなかったりするため使用できない)。
(空き)領域の管理
率直に言って良いアイデアが無い。いわゆるbump allocatorと通常のアロケータの2段階戦略も考えられるが、今回はゲーム用なんでコストが可能な限り一定になっていてほしい。例えば、REエンジンではスレッドローカルなアロケーションとしてのbump allocatorと、グローバルヒープとしての通常のアロケータを分離しており( https://www.slideshare.net/capcom_rd/re-engine-72302524 )、通常のアロケータではオブジェクトへの参照を含む型のみをトラバースすることで負荷を軽減している。
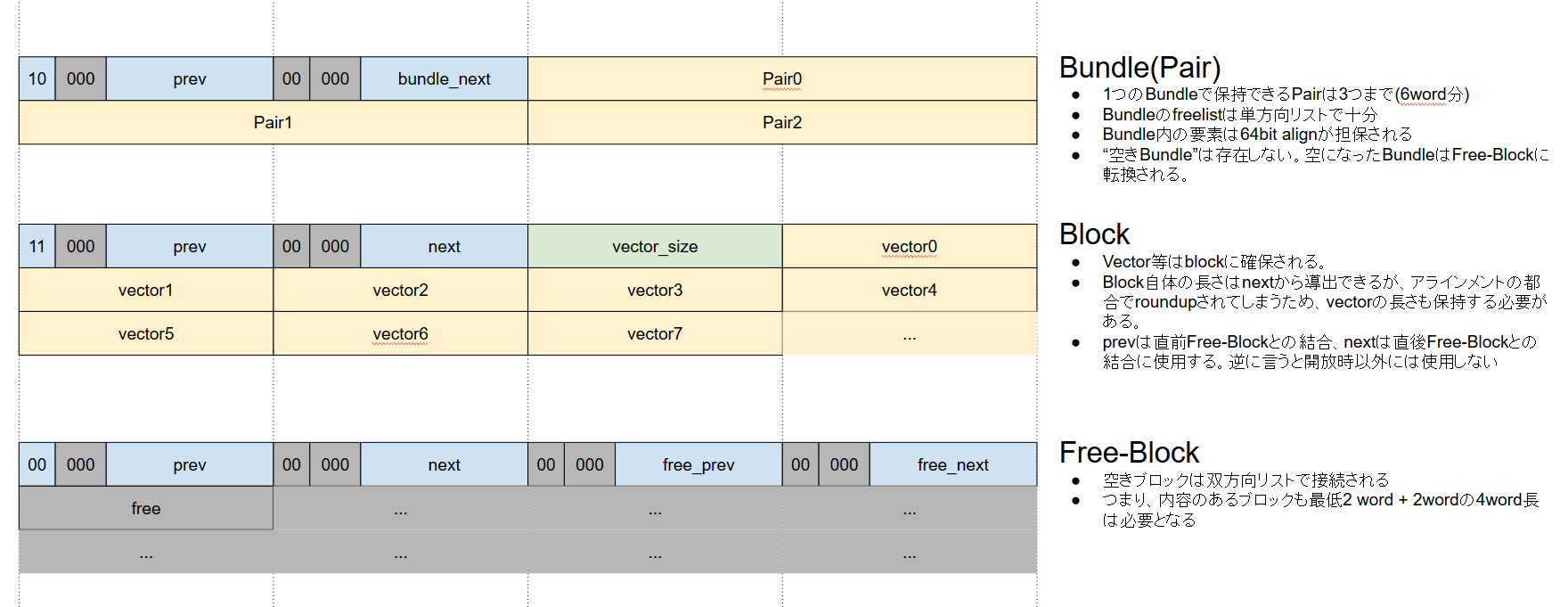
ここでは、ヒープを分割した領域を"バンドル"と"ブロック"の2種類に分け、両者を空間的に(ヒープとして用意した配列の内部で)混在できるようにしている。ブロックにはprev、nextの2値がヘッダとして必要であり、それぞれが領域の管理のために使用されるが、バンドルは固定長であるためprevだけが領域管理に使用され、nextだった場所は型毎に固有の目的に使用できる。
領域のフラグメントを防ぐためには領域の結合を行う必要があり、領域の結合をO(1)で行うためには直前と直後のブロックヘッダの位置をO(1)で参照できる必要があるため(要出典)、どうしても領域をリンクリストで結合する必要がある。つまり、領域を分割する度に、領域には最低でもポインタ2つ分のムダが出ることになる。これはScheme/LispにおけるPairのような超小さいオブジェクトを大量に作る環境ではあまり美味しくない。
ただし、GCのsweepは先頭から順番に行われるため、実は領域にprevは必要無い(ある領域を解放する際に、直前の領域がどこにあったのかを覚えておくのは容易)。ただ、ヘッダ領域を1wordぶん減らすことによるアドバンテージが思いつかなかったのでそのままにしている。
バンドルは、Pair等小さな固定長オブジェクトの特別扱いのために使用する。Pairは3つ(計6要素)をまとめて確保し、必ず8要素アラインで配置する。バンドルの8要素後ろは必ず次の領域の先頭になるようにし、nextフィールドが無くても良いようにする。nextフィールドは"バンドルのフリーリスト"におけるnextを表現するために使用する。これにより領域のオーバヘッドは2要素となり、2要素アラインが必要なデータ(C言語のdouble等)もヒープに直接格納できるように配慮している。
バンドルにアライン要請が有るため、vectorも8要素アラインで確保する。(短いvectorの格納効率改善を狙って一応short-vectorとしてのビットも振っているが後回し -- vectorの大半は6要素以上あるためあまり意味が無さそう)
空き領域はそのサイズに従ってbinに分類され、bin上の空き領域はフリーリストで管理される。フリーリストのlookupにはTLSF( http://www.gii.upv.es/tlsf/main/docs )を使う。TLSFは、2段階のビットマップを使用して"空領域が存在するbin"をO(1)で導出するテクニックで、要求サイズをキーにした2回のbit演算で必要なbinを特定できる。TLSFではブロックのみを管理し、Pairのようなバンドル群は専用のフリーリストを持つことになる。
空きブロックは、prevフィールドの上位2bitを'0'にすることで表現する。逆に、使用中のブロックはprevフィールドの上位2bitを'1'にする。バンドルであることを識別するには、prevフィールドの上位2bitが'10'であることを使う。GCによってバンドルが解放された場合、つまりバンドル内の全てのオブジェクトが解放された場合は、バンドルは通常の空きブロックに転換される。
空きブロックには追加のnext_free、prev_freeが有り、当該binでのフリーリストを(双方向リストで)構成する。このため、空きブロックの最小オーバヘッドは4要素であり、これよりも小さく領域を分割することはできないということになる。フリーリストを双方向リストにすることで領域の抜去がO(1)で可能になる。今回解放された領域は基本的に即mergeするため、フリーリストからの領域の抜去は頻繁に発生する。
バンドルの空きの探索は、Schemeコードで生成されることの無い"free"値を使用して行う ...要するにバンドルは十分に小さいので、毎回領域をスキャンしても大したコストにはならないだろうという読みが有る。
...そもそも、バンドルの空きを管理する必要があるかどうかは議論が有る。つまり、一度全要素を埋めたバンドルは内部の要素全てが解放されるまでは放置するという方向も考えられる。これを行うとマークビットの数を8wordにつき1bitにできるため、考慮の価値は有る気はする(が、領域のフラグメントはより激しく発生することになる)。現状のオブジェクト機構では、Pairがアドレス可能なオブジェクトとして最小サイズで、かつ、偶数インデックスでのみ開始するため、マークビットは2wordにつき1bit必要となる。
(隣接ブロックポインタをオブジェクト内に持つということは、sweep時にヒープの書き換えが必要になるということになる。そもそもビット転置のようなテクニックで外部に置けないだろうか。。?)