yuniフロントエンドの設計 - expander設計方針
フロントエンドというかexpanderもyuniの枠でポータブルに書くことにした。というのも、これをやるとGambit、MIT/GNU SchemeやSCMのようなモジュールシステムの無いScheme処理系も同時にサポートできるため。
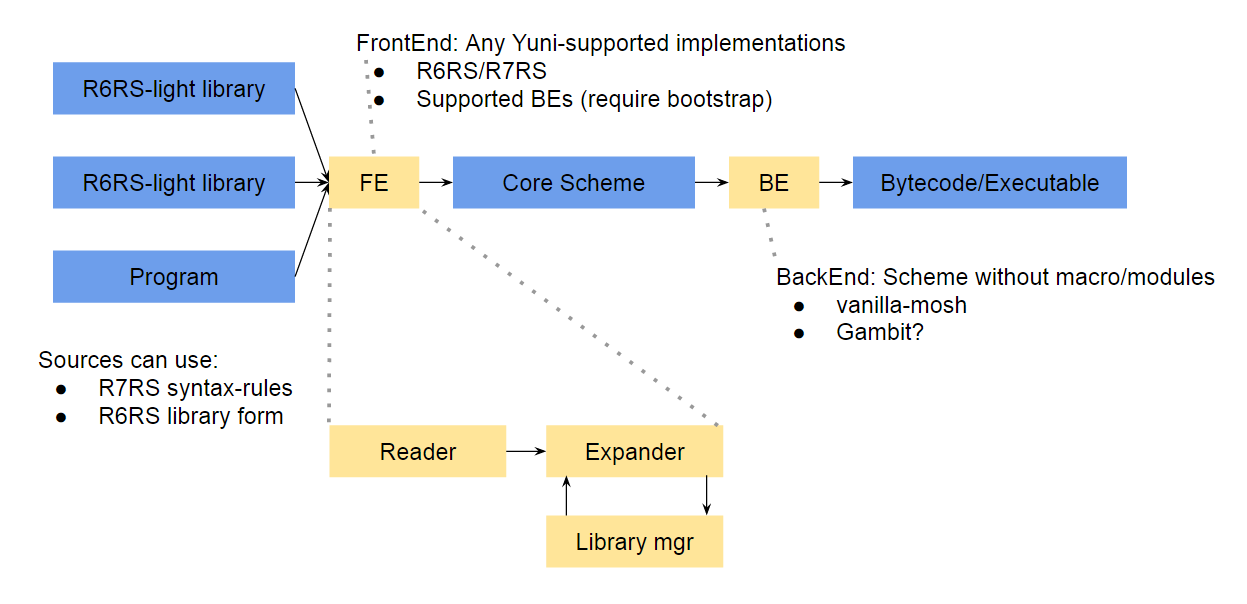
yuniフロントエンドは、ライブラリとアプリケーションコードを読み取って1本のマクロ展開済のSchemeプログラムを出力することになる。core schemeの処理系、つまりホストSchemeはGambitのような既存のR5RSやvanilla-moshを使う。
フロントエンド自体はyuniの枠で書かれるので、yuniがサポートしている処理系は原理上全てホストSchemeになれる。error reporting等の機能でyuniフロントエンドの方がホストSchemeより優れていれば、開発中はホストSchemeのフロントエンドの代わりにyuniのフロントエンドを使うといったことが可能かもしれない。
フロントエンドの役割は、Schemeプログラムを入力し、構文を検証しつつコード生成器のためのcore schemeプログラムを出力することになる。
- readerは特に面白いパートは無いので後回し。ホストSchemeのものを流用する。バイト列を読み取り、ホストScheme内で扱うオブジェクトを生成する。
- ライブラリマネージャはload済のライブラリを管理したり、import指示されたライブラリをパス名に変換してファイルシステムから読み取る等。
- expanderが一番重要なパート。マクロを展開し、ライブラリに宣言されたグローバル変数を適切にリネームする。
以下はexpanderについて。他は後回し。
expanderの仕事
expanderの仕事は平たく言えば:
(library (lib-a) (export theProcedure) (import (yuni scheme)) (define (theProcedure x) (display (list 'From-A: x)))) (library (lib-b) (export theProcedure) (import (yuni scheme)) (define (theProcedure x) (display (list 'From-B: x))))
のようにライブラリ(lib-a)と(lib-b)で同じ名前のtheProcedureが定義されていたとして、
(import (rename (lib-a) (theProcedure theProcedure-A)) (rename (lib-b) (theProcedure theProcedure-B))) ;; Call theProcedure in (lib-a) (theProcedure-A "Test") ;; Call theProcedure in (lib-b) (theProcedure-B "Test")
のようなプログラムと一緒に入力すると、
(define (theProcedure~1 x) (display (list 'From-A: x))) (define (theProcedure~2 x) (display (list 'From-B: x))) ;; Call theProcedure in (lib-a) (theProcedure~1 "Test") ;; Call theProcedure in (lib-b) (theProcedure~2 "Test")
のように、ライブラリを含んで、かつ、意図通りの参照が行われる1本のプログラムを合成すること。フロントエンドはプログラムの合成までしかやらないので、更にバックエンドとなるcore scheme処理系で1本になったプログラムを実行させることになる。
ここで、theProcedure~1とかtheProcedure~2のように適当なサフィックスを付けてリネームを行うのがキモとなる。世間的にはデバッグのために元の名前を残しておくのが流儀になっているが、別に完全に適当な名前でも問題はない。ここで、プログラムのimportではtheProcedure-aとかtheProcedure-bのような名前でimportしているが、出力されるプログラムではexpanderが生成されたシンボルに差し替えられている。
yuniでは基本的にR7RSの機能性はサポートしないといけないので、syntax-rulesを使ったマクロの展開もexpanderの仕事になる。これは長くなりそうなので別途。
expanderのRequirements
yuniのフロントエンドには諸般の事情で自明でない要求がいくつかある:
- ライブラリの展開結果をキャッシュ可能であること
ここは非常に悩ましいポイントで、Chezのようにexpandがインクリメンタルに行える処理系ではそもそもライブラリのexpand結果をキャッシュする必要は無い。デザインも幾分シンプルになる。
が、どうせread自体のコストを圧縮するためにFASL化するのは不可避であるため、だったらexpand後のライブラリをキャッシュした方が効率的なのではないかという気がしている。C++で言うところのPrecompiled headers vs. Pretokenized headersのような議論とも言える。
ちなみに、現状のnmoshやpsyntax-moshもライブラリファイル単位で展開結果をキャッシュしている。yuniは1ファイル1ライブラリなので重要な違いではない。
- 余計なシンボルをinternしないこと = 余計なrenameを行わないこと
現状のnmoshでは、expanderがリネームしたシンボルを全部internして使っている -- これにはlambdaの仮引数等も含まれる。lambdaの仮引数のリネームは無駄。
(define (theProcedure~1 x~1) (display (list 'From-A: x~1)))
(ちなみに現状のnmoshでも、core schemeで定義されている手続きはリネームしない)
Chezのようにシンボル名の生成(gensym)そのものをlazyにやることで高速化する( http://www.cs.indiana.edu/~dyb/pubs/hocs-talk.pdf http://www.kmonos.net/wlog/65.html#_1433060921 )という方針も有るが、可能な限りバックエンドのScheme処理系に対する要求を積み増ししない方が望ましい気がしている。
ただ、これはライブラリのキャッシュと相反する項目と言える。つまり、ライブラリのグローバルな定義はどうせリネームしないといけないため、どうしても人間が書いたわけではないシンボルがコード上に残ることになる。
- ライブラリキャッシュは正当なcore schemeプログラムになること
専用ランタイムも含めあまり複雑なインテグレーションを要求するのは賢くない。というわけで、依存関係順にloadすればとりあえず動作するようにライブラリキャッシュを構成する。このようにしておくと処理系のREPLでデバッグするときに便利。
Gambitのようなコンパイラがターゲットであれば、単にconcatしてコンパイルすることになる。この場合は、依存関係順にロードされたことは仮定できるので、いくつかのチェックは省略できる。
- readしたプログラムをヒープ上で改変しながら動作し、かつ、expandトレースを残せるようにすること
nmoshでは、renameしたシンボルそのものに行番号情報(元のシンボルがどこに記述されていたか)が保持されているため、マクロによって生成されたプログラムのS式を毎回consして作成しても大きな問題は無かった。普通のSchemeでは、シンボルそのものに行番号情報を付けるのではなく、consペアに付与するのが普通と言える。vanilla-moshにも、annotated-pairとしてペアにメタデータを付与する仕組が有る。
readerが生成した行番号情報と同じものをプログラムがconsしたペアに付与できるとは限らないので、可能な限りreaderがreadしてきたオブジェクトを改変しながら動作する。こうすることで行番号情報を維持しつつ、かつ、ポータブルに書くことができる。(行番号情報へのアクセス自体は処理系毎に用意する必要があるが。。)
weakハッシュテーブルを使ってこの手のメタデータを自前で実装するという手もあるが、weakハッシュテーブルは処理系によって有ったり無かったりするので微妙。展開器の寿命をちゃんと管理できるなら、weakでないハッシュテーブルを使うという方法も一応考えられる。
readしてきたオブジェクトを書き換えながら動作するということは、トレースを残す良い方法が無いということになる。nmoshはマクロの起動によって差し替えられる前のオブジェクトを取っておくことでトレースを実現しているが、今回は明示的にトレースを生成しなければならない。
expanderの仕事
expanderの仕事は以下の2点に集約できる:
- ライブラリ内のグローバル変数定義をリネームし、後続のライブラリ/プログラム内での参照をそれに合わせる
core schemeにはマクロの参照は残らないため、マクロをリネームする必要は無い。ただ、マクロの展開と変数のリネームが有るためプログラム全体を一度はスキャンする必要がある。Schemeなのでlet等のブロック内部にある変数名をリネームする必要はない。
- マクロの展開
実はマクロを展開することは今回の問題のためには必須ではない気がしている。バックエンドのSchemeがR5RS syntax-rulesさえサポートしていれば、(syntax-rulesはhygenicマクロで参照透過なので)グローバルに定義された変数/マクロのリネームだけで正当なコードを出力するはずで、実際プログラムのデバッグのためにはそちらの方が有利なのではないかと思う。一度S式フォーマットのライブラリを出力してしまうと文脈情報が失われる。
今回はBiwaSchemeのようなhygenicマクロの一切無い処理系もターゲットにしたいのでマクロは完全な展開を行うことにした。
出力プログラムをletで囲むか問題
R6RSではインポートしてきた変数の変更は禁止なので、コードをletで囲み、以下のような構造にすることでプログラム上のシンボルをリネームする必要はなくなる。
プログラム上のシンボルをリネームしなくても良いということは、core scheme処理系が出力されるエラーも元のプログラムコードのシンボルで出るという大きなメリットが有る。(syntax-rulesの生成するシンボルは結局常にリネームする必要があるが、これはどうやっても救えない。)
;; Global variables (define theProcedure~1 #f) (define theProcedure~2 #f) (let () ;; Expanded (lib-a) (define (theProcedure x) (display (list 'From-A: x))) (set! theProcedure~1 theProcedure)) (let () ;; Expanded (lib-b) (define (theProcedure x) (display (list 'From-B: x))) (set! theProcedure~2 theProcedure)) ;; Expanded program (let ((theProcedure-A theProcedure~1) (theProcedure-B theProcedure~2)) ;; Call theProcedure in (lib-a) (theProcedure-A "Test") ;; Call theProcedure in (lib-b) (theProcedure-B "Test"))
実際nmoshはこのようなコードを出力するが、これがコンパイラを惑わすことになる(異なるライブラリで参照されるグローバル変数が等価でなくなる)んじゃないかという心配は有る。というわけでyuniフロントエンドではこの方針を採らず、全てのグローバル変数参照をリネームする方針でやることにした。つまり、可能な限りプログラムの構造を変更しないようにする。ライブラリ内でグローバルに宣言された変数は、core scheme出力でもグローバルのままになる。
実行時にエラーが発生した場合には人間には読みづらいエラーやbacktraceが出てしまうが、これはちょっと仕方ない。
次の一手
まず、Gambitにyuniを移植するをターゲットに、キャッシュ機構の無いexpanderを用意する。キャッシュ機構を実現するためにはどうしてもPIDとか現在時刻のようなユニークIDを取得する仕組みが必要になり、何らかの形で移植層を追加しなければならないため。どうせyuniの開発中はキャッシュなんて殆ど効かないので、キャッシュ機構自体の優先度はあまり高くない。むしろキャッシュが不要になるくらいexpanderが高速である方が望ましい。