nmoshのスレッドモデルを整理したいの会
正直作っている本人すらよく説明できていないnmoshのスレッドモデル。0.2.8に向けて用語を整理する。
NMosh Offload
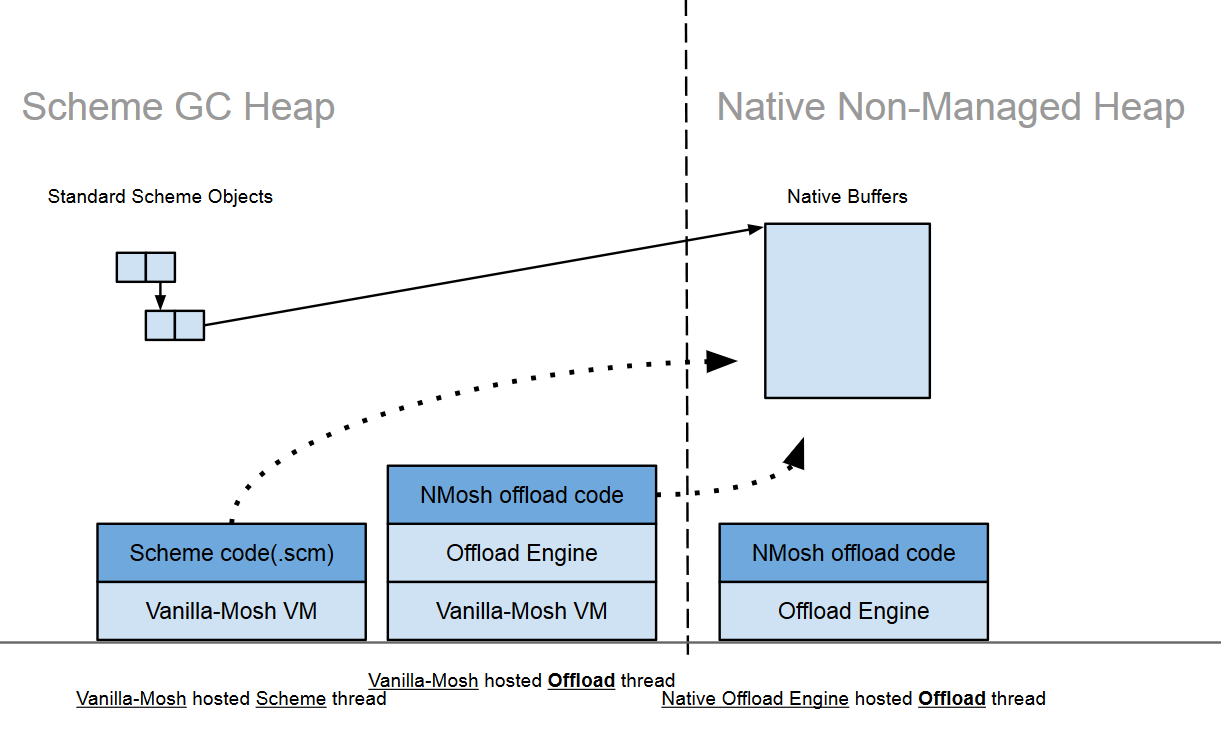
従来FFI VMと呼んでいた、FFI専用のlightweight VMをNMosh Offloadとマーケティング向けの名称に改称。NMoshと名前が付くがyuniの方に実装するので他の処理系でも同様に使用できる(予定)。
NMosh Offloadは、NCCCによるFFI呼び出しの前処理用のVMとその言語仕様。NMosh OffloadのVMはScheme版とCで記述したインタプリタの両方を用意し、RacketのようなJITC処理系ではJITCの恩恵を受けられるように配慮する。
全部Schemeコードで済ませないのは、ヒープオブジェクトを触ることによって発生するGCポーズが許容できないユースケースに対応するため。例えば信号処理や割り込みハンドラ等。
従来のScheme言語はNMosh Scheme言語となる。NMosh Offloadの言語仕様はまだ未定だが、NMosh Schemeの方にもループ構文等は合せて提供し、ライブラリとしてもScheme側と共通のR6RS-lightフォーマットとして相互運用性に配慮するつもり。NMosh Offloadの方をNMosh Schemeの厳密なサブセットにするアプローチはpypyにおけるRPythonに近い。
NMosh SchemeとNMosh OffloadはFFIバインディングを共用することができ、Offloadで書いたプログラムはScheme側からはNCCCなFFI関数と同等のものになる。このため、NMosh Schemeでテストを記述しつつ、実際の運用はNMosh Offloadのコードで行うといった分担が考えられる。
2種類のヒープと3種類のスレッド
ヒープには大きく分けて2種類になる。
- Schemeヒープ。GCされ、普通のSchemeオブジェクトを格納するヒープ。アクセスに必要な時間は不定。Native Offloadスレッド(後述)からはアクセスできない。
- ネイティブヒープ。いわゆるunmanagedなヒープでGCされない。GCが必要な場合は、Scheme側でWeakハッシュテーブル等を使用して手動で実装する。アクセスに必要な時間はmlock等を正確に行えば一定にできる。
スレッドは正確には2種類と1バリアント。
- 1) Schemeスレッド。普通のSchemeはこちら。NMosh Schemeコードを実行する。
- 2a) Scheme Offloadスレッド。NMosh OffloadのScheme版VMを実行するSchemeスレッド。NMosh Offloadコードを実行でき、かつ、ホストVMを使用して(NCCCの提供するSchemeコールバックを使用して)Schemeオブジェクトにもアクセスできる。Scheme実装なのでリアルタイム性は保証されない。
- 2b) Native Offloadスレッド。NMosh OffloadのC版VMを実行するスレッド。NMosh Offloadコードしか実行できず、Schemeヒープオブジェクトには一切アクセスできない。
イベントキュー
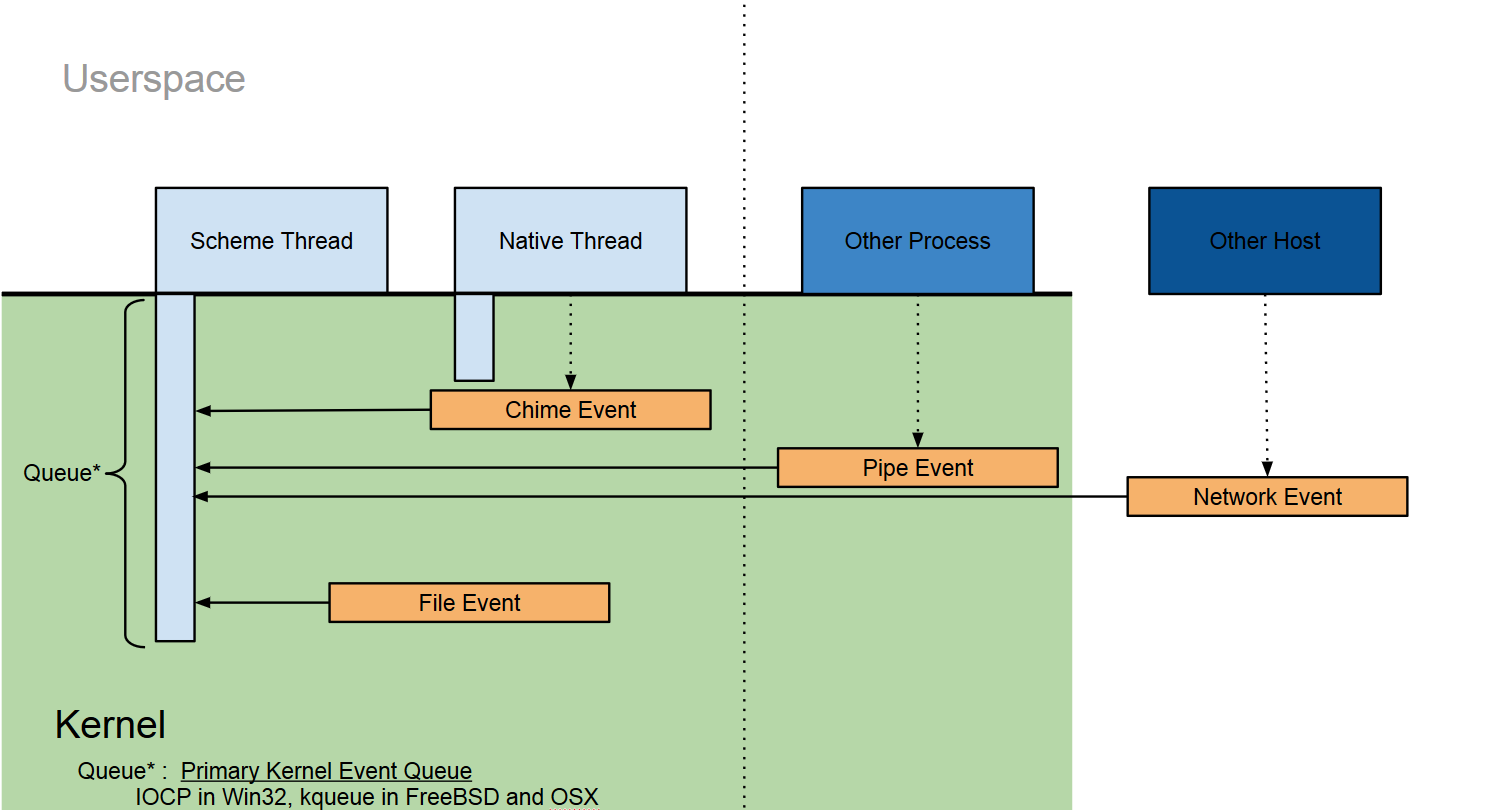
個々のScheme/Offloadスレッドはデフォルトキューとしてカーネルイベントキューをひとつ持つ。カーネルイベントキューはカーネルからの起床要求を受けとるためのキューで、WindowsであればIOCP、FreeBSDやMacOS Xであればkqueueが使用される。
他のスレッドやプロセス、ノードは起床要求を様々な形で送信することができる。同一ノード内であればpipe、異なるノード間であればネットワークが例えば使用される。同一プロセス内での起床要求はNMoshではchime(チャイム)と呼ぶ。chimeはOffloadスレッドとSchemeスレッドの通信にも使用できる。
(図には盛り込むことができなかったが、)カーネルイベントキューは一般的なイベントキューのサブクラスとして表現される。一般的なイベントキューはカルチャを持つことができ、APIセット固有のキューメカニズムを使用することもできる。
イベントキューがchimeの生成をサポートしていれば、それを使用して複数のキューを束ねることができる。カーネルイベントキューは常にchimeの生成をサポートしている。イベントキューがchimeの生成をサポートしていない場合は、キューを待ち合わせる専用のNMosh Offloadスレッドを生成し、そのスレッドにchimeを鳴らさせることで擬似的にイベントキューを束ねることができる。(もっとも、SDL2のように、ライブラリを初期化したスレッドでしかイベントキューを待ち合わせられないライブラリやOSも存在するため、この手法も万能ではない。)
課題
まだ考察が追い付いていない重要な問題がいくつか有る:
- Offloadでの外部ノードサポート
OffloadのScheme側インターフェースを工夫することにより、OpenCLのような独立したメモリ空間を前提としたAPIを良くサポートできるように見える。ただ、今のところ良い方法が思いついていない。
- mmap()されるバッファをBytevectorに見せて良いのか問題
今のところ、yuniがサポートしようとしている処理系は全て任意のポインタをbytevectorとしてScheme側に公開することはできる。これがどの程度役に立つのかはなんとも言えない。
外部ノードや、キャッシュ属性の異なるバッファのサポートを考えると、単純にbytevectorとして見せるよりはアクセス用の専用のプリミティブを用意してbytevectorからは独立したオブジェクトとした方が有利かもしれない。
- スレッドがMutex等の同期プリミティブで寝るケースをどうすんのか問題
現状のスレッドモデルは、スレッドの実行がブロックされるのはカーネルイベントキューに"アタッチ"できるオブジェクトにアクセスした場合のみという仮定がある。この仮定は正しくなく、実際にはMutex等でもスレッドは寝ることがある。
悪いことに、殆んどのPOSIX系OSはpthreadsのmutexや条件変数、セマフォをカーネルイベントキューに関連付けることができない。このため、ライブラリ内で実行がブロックされてしまった場合に、chimeによってスレッドを起床させる良い手段は存在しない。
ブロックする関数を呼ぶ可能性が有る場合はOffloadで作成したworker threadに任せてOffload側からchimeするというのが基本的なコーディングスタイルになると予想している。
- 非同期割り込み
非同期割り込みは意図的にサポートしていない。POSIXにおけるシグナル、WindowsにおけるAPCはOffloadで専用の処理ルーチンを与えた場合にだけ処理できる というのを制約にする。Schemeヒープを非同期割り込みセーフに書くのはあまり単純な仕事でないので、現状ではサポートは考えていない。
非同期割り込みを非サポートとすることで制約になるのは、浮動小数点例外やCPU例外(SIGSEGV, SIGBUS)をキャッチするタイプのSchemeコードが書きづらいという問題にもなる。mmap()したバッファをbytevectorに見せると、bytevectorへの通常のアクセスでCPU例外が発生するケースをケアする必要がある。
- スレッドやイベントの優先度、スケジューリング
カーネルでI/O優先度やQoSをサポートしているOSは多いが、この機能を公開するために良い抽象化ができるかというとそうでもない。Linux等はposix_madvise()/posix_fadvise()でアクセスパターン制約を与えることができるが、これらがI/O効率に与える影響を理解するには熟達が必要になる。
スレッドの優先度やスケジューリングはOSによって違いが大きすぎる。WindowsにおけるMMCSSのように"オーディオシーケンス用"とか"バックグラウンドでのデータ生成用"のようにスレッドを適当にラベリングできるような仕組みを導入する必要が有るかもしれない。
Schemeスレッドの状況はより悪い。低優先度なスレッドがヒープのGCを発生させてしまうと、高優先度のスレッドが必要以上にブロックされる優先度逆転現象を起こす可能性がある。(低優先度なスレッドがGCを実行している間でも、スレッドの優先度は低いままなのでなかなかスケジュールされないため。)
例えば、GCスレッドはVMのスレッドとは別に起動しておき、それに高い優先度を与えるといった配慮が必要かもしれない。