シェルスクリプトでゲーム制作は可能か? - タイマ編
現状の結論: Bashじゃないと無理
シェルスクリプトでゲームを作る試みはいくつか有る。例えば、ChessbashはBashで書かれたチェスプログラムで、Unicodeを使って視認性の高い盤面を出力し、ある程度の"実用性"も確保している https://github.com/thelazt/chessbash 。
じゃぁアクションゲームはできるのかというのは当然出てくるところだが、
- 入力: だいたいの端末はマウス入力をサポートしており、Linux等event deviceから直接取得できるOSもある
- オーディオ: /dev/dsp が 8kHzのmono PCM出力をサポートしている
- 描画: SIXELを使えばビットマップを出せる。極小フォントを使う手もあるが...
と、かなり環境は整っているように感じられる。
ところが一点だけどうやっても解決策が浮かばないのがタイマで、今のところ実用的なタイマはbashのようなシェルの独自拡張を使わないと不可能なのではないかと考えている。たぶんbashで実現したタイマか、perlか何かのワンライナーで実現したタイマの選択式とするのが最もポータビリティが高いのではないかと思う。
(もう一点、いわゆるnon-blocking I/Oも不可能なんじゃないかと思っているが、後述のようにタイマがあればそこからprintするなりsignal送るなりなんなりの方法で無理矢理入力をunblockさせることは簡単なはず。)
ちなみにPOSIX shellには配列すら無いため、常識的な速度でPCM合成を行うには多分loop unrollは必要と思っていて、一旦別の高級言語で書いておいてシェルスクリプトに変換するという過程はどうやっても出てくると考えている。(シェルスクリプトを生成するシェルスクリプトを作り、evalでfunction定義にすれば良いんじゃないかという気もするけど。)
タイマの必要性と求められる性質
ゲームに使用するタイマに求められる性質は:
- "発火"間隔が十分に短い: 一般にゲームは1秒間に30 - 60回画面更新を行う必要があるため、1秒よりも十分に短い間隔で発火する必要がある。
- 他の処理の影響を受けず一定間隔である: 画面更新間隔が一定でないのはプレイフィールに大きな影響を及ぼす。また、オーディオ生成のインターバルも一定でなければならない。
- リスタート可能である(位相が取得または調整可能である): ゲームをバックグランドに廻したり、PCをサスペンド & レジュームさせるような場合に、タイマを再度同期させる必要がある。
シェルスクリプトではスレッドを作成できないため、タイマプロセスを作成し"一定間隔で文字をprintする"ことでタイマを作ることになる。
一番簡単そうなのはOS固有の時刻ソース、例えばLinux/Cygwinで言うところの /proc/uptime を監視し、変化があったタイミングでprintというもの。ただ、今回はこれを却下してbashの独自機能であるreadのタイムアウトを使っている。
× ビジーポーリング、sleep
OSは /proc/uptime やdateコマンドのような時刻表示手法をもっていることが多いため、これをひたすら呼んで変化点でprintとするのが一番簡単そうな気はする。が、これをやってしまうとタイマープロセスがCPUを埋めてしまうため、本来のゲームコードが動作させられなくなってしまう。
POSIXはniceのようなユーティリティ( http://pubs.opengroup.org/onlinepubs/9699919799/utilities/nice.html )を提供しているが、タイマプロセスのniceを上げてしまうと他の処理にタイマプロセスが割り込まれることでタイマの発火そのものが行えなくなってしまう可能性がある。
じゃぁsleepコマンドを挟めば良いじゃん と、思うかもしれないが、sleepは最短で1秒の待ちしか提供しない。
A non-negative decimal integer specifying the number of seconds for which to suspend execution.
× PCM再生によるブロック
では /dev/dsp が一定ペースで書き込みバイトを消費するのを使うのはどうか?例えば、Cygwinで30秒ぶん、つまり 8000 バイトで1秒を30個 /dev/dsp に出力するとかなり正確に30秒掛かることがわかる。
$ dd if=/dev/zero of=/dev/dsp bs=8000 count=30 30+0 レコード入力 30+0 レコード出力 240000 bytes (240 kB, 234 KiB) copied, 30.1313 s, 8.0 kB/s
... しかし、この方法には微妙な罠があって、
- /dev/dspの処理ブロックサイズに依存する: /dev/dspはある一定のバイトを受信しないと処理を開始しないため、このブロックサイズ単位でしかタイマとして機能しない。
- 本来のオーディオ出力に干渉する: 上記コマンドラインを音楽なりなんなりを再生させながら実行するとボリュームが低下するのがわかる。計時のための音声と本来の音楽のミキシングが行われてしまう。
特に前者が深刻で、
Implementation Notes
1. Audio structures are malloced just before the first read or
write to /dev/dsp. The actual buffer size is determined at that time,
such that one buffer holds about 125ms of audio data.125ms = 1/8 秒、つまり、この方法では最高でも 8Hz のタイマしか作れないことになる。これはゲームのタイマとしては少々精度が足りない。もちろん、/dev/dspをioctlで制御すればこの辺のパラメタは変更可能な可能性が高いが、どっちにせよシェルスクリプトからは直接ioctlを発行することはできない。
後者の問題も、本来のBGMで計時すれば良いじゃんと思われるかもしれないが、Cygwinの場合1秒程度のバッファを持っているためこれがそのままオーディオのレイテンシになってしまう。このため、常識的なレイテンシを保ちながらインタラクティブオーディオを出力するためには、一定ペースでPCMを生成して書き込みつづけるくらいしかなく、ブロックするまでひたすら書き込むという手法は取れない。
○? bashのread拡張を使用する
というわけで、bashの拡張を使うしか無いんじゃないか。。
- ticker.sh https://github.com/okuoku/shtimertest/blob/fb8c4f8ed16ba128a89188bc5b3d299a7fdfb7b7/ticker.sh
#!/bin/bash while true; do read -t 0.02 ; printf "C\n" ; done
bashのreadは小数のタイムアウトを取れることを使用して、そのタイムアウトをtickとして出力するタイマにしてみた。timeoutに小数が使えるのはbash4以降(2009 -)に限られる。このため、それなりに最近のbashを要求することになる。
y. The `-t' option to the `read' builtin now supports fractional timeout
values.
- measure.sh https://github.com/okuoku/shtimertest/blob/fb8c4f8ed16ba128a89188bc5b3d299a7fdfb7b7/measure.sh
#!/bin/bash function ticker_wait { # ★ これもbashism local MM=; read -u 4 MM } # Bashism exec 4< <(./ticker.sh) while true; do COUNT=0 printf -v NOW0 "%(%s)T" -1 # ★ これもbashism while true; do printf -v NOW1 "%(%s)T" -1 ticker_wait; COUNT=$(($COUNT+1)) if [[ $NOW1 != $NOW0 ]] ; then break; fi done echo $COUNT done
measure.shは計測用のコードで、1秒間のtick数を出力する。出力は大体48 - 49で安定しており、この精度であればゲーム用のタイマとしても使用可能なのではないかと思う。
$ ./measure.sh 7 49 48 49
ちなみにprintfによる時刻取得もbashism(bashの独自拡張の利用)で、そもそもPOSIX shellでは外部コマンド/ファイルに依存しない時刻取得自体不可能なのではないだろうか。。
read timeoutの精度
(あとで真面目に書く)
この手のread timeoutを移植性の高いタイマとして使う手法は比較的よく見られる手法で、C言語ではselect()がWindowsを含めたOSに大抵存在することを使用してselect()をポータブルなsleepとして使ったりもする。
ただし、タイムアウトの精度は基本的によろしくないことが多い。
bashのread timeoutはfalarm()関数で実装されており、これはsetitimer()に依存している https://git.savannah.gnu.org/cgit/bash.git/tree/lib/sh/ufuncs.c?id=b0776d8c49ab4310fa056ce1033985996c5b9807#n48 。setitimer()の無いプラットフォームではalarmにfallbackし、これは1秒の精度しかない。
システムが1秒未満のタイムアウトをサポートしていたとしても、タイマの起床がtick(HZ)の単位に丸められるプラットフォームも有る。このため、この手の手法で実現されるタイマは"1000Hz程度のスケジュールタイミングにアラインされ、多少のジッタを常に含む"というのを前提に考える必要がある。
? pingのタイムアウト、他
他の没アイデアとしては、pingコマンドのタイムアウトを使う(BSDのpingは1秒未満のintervalを使えるはず)というものも有ったが、どっちにせよ絶対時刻の取得もできないので実験していない。
2CPU以上のシステムを仮定するなら、ビジーポーリングは選択肢になるかもしれない。CPUを占有してしまうこと以外にはこれといって問題は無いように思える。仮に1秒未満の変化が取れなかったとしても、ディレイループの長さを動的に調整するといった方法で必要なタイミングを抽出することは可能なのではないかと思う。
busyboxをはじめ、実はsleepコマンドはミリ秒精度のsleepをサポートしていることが多い。このため、sleepコマンドループもそれほど悪くはない(ただし重い)選択肢になるかもしれない。
マイコン向け処理系の実装戦略を調べる会
追記: mruby/c 1.1にはGCが有るらしい http://www.s-itoc.jp/news/notice/726
C向けにヒープ実装を用意するにあたって、まぁ富豪的にガツンとやってしまえば良いんじゃないかと適当に考えていたけど、営業上どうしても32KiBヒープで動くアプリを用意する必要が出てきたので比較的真面目にROM化やポインタの圧縮等を考える必要が出てきた。というわけでいくつか処理系を見てまわることにする。
PICOBIT (R4RS Scheme)
- https://github.com/stamourv/picobit
- 本家
- http://users.eecs.northwestern.edu/~stamourv/slides/picobit-ifl09.pdf
- スライド
- https://github.com/stamourv/sixpic
Gambitの一派としてPICOBITが有り、Schemeで書かれたTCP/IPスタック(https://github.com/stamourv/s3 , http://users.eecs.northwestern.edu/~stamourv/slides/s3-sw08.pdf )のようなアプリケーションも抱えている。
興味深いのは、わざわざ自身のVMをコンパイルするためのCコンパイラまで用意していて(SIXPIC)、当時の純正コンパイラを超えたパフォーマンスを出している点。これはwhole program optimizationや関数ポインタのfold等を実装しているためとしている。(amalgamationする等しないとフェアな比較でない気もするけど)
オブジェクト表現等は標準的な実装。32bitワードにcar/cdrを収めてcellとしている。
mruby, mruby/c (Ruby)
- https://github.com/mruby/mruby/blob/3c18ec27e917edcf7d0c5093d5d09a735d6ca71c/src/gc.c
- mrubyのGCコード
- https://tyfkda.github.io/blog/2013/04/18/mruby-gc.html
- mrubyのGCの仕組みを調べた
- https://github.com/mrubyc/mrubyc
- mruby/c
- https://github.com/mrubyc/mrubyc/blob/814725908305f380cd761057dd97fd616b8bec07/src/value.h#L100
- mruby/cのオブジェクト
意外にmrubyはこの領域に何も提供していない。mrubyはかなり真面目なヒープ実装を持っているがメモリ消費量も400KiB程度(mruby/cサイトの公称)でマイコン向けには厳しいものがある。
mruby/cはmrubyのバイトコードを実行するコンパクトな処理系で今回のターゲットにより近いが、そもそもGCをしない(追記: 1.1には有るらしい)。オブジェクトも単なるunionで、逆にここまで単純化して良いのかというところ。"グルーロジックをRubyで書ける"というポイントをどの程度評価するのか。下のmJSも同じような立ち位置のインタプリタと言えるが、mJSはGCも実装している。
(追記: mruby/c 1.1以降には有るというリファレンスカウント式のGC https://github.com/mrubyc/mrubyc/blob/814725908305f380cd761057dd97fd616b8bec07/src/value.c#L154 )
MicroPython (Python3)
- http://www.micropython.org/
- 本家
- http://docs.micropython.org/en/latest/pyboard/reference/constrained.html
- ドキュメントのマイコン制約について解説した章
- https://github.com/micropython/micropython/blob/970eedce8f37af46cb2b67fa0e91d76c82057541/py/mpconfig.h#L52
- オブジェクト表現
MicroPythonはこの手の言語として考えうる殆どの機能を備えている。ROM化、マルチスレッド、インラインアセンブラ、バイトコードコンパイル、マシンネィティブワードの使用(Viper)、補完付きのREPL、...。
ワード中のオブジェクト表現は4種用意されていて、コンパイル時に選択される。
- MICROPY_OBJ_REPR_A: ポインタを4バイトアラインで表現する
- MICROPY_OBJ_REPR_B: ポインタを2バイトアラインで表現する(fixnumを犠牲にしたコンパクト表現、デフォルトで使用されるのはPIC16のみ)
- MICROPY_OBJ_REPR_C: 32bitマシン向けのNaN boxing
- MICROPY_OBJ_REPR_D: 64bitマシン向けのNaN boxing(ポインタは32bit範囲)
特徴的なのはinternされた文字列として"qstr"を持っていることで、これにより文字列オブジェクトをinternしてROM上に配置することで省メモリを実現できる。
eLua (Lua)
- https://github.com/elua/elua
- プロジェクト
- http://www.eluaproject.net/doc/v0.9/en_arch_ltr.html
- Luaの省メモリ化パッチであるLTRの解説
- http://www.eluaproject.net/doc/v0.9/en_elua_egc.html
eLuaは通常のLua5.1にいくつかパッチを当てて組込み動作に向くようにしたもので、uIPのバインディングやXMODEMのサポート、I/O等ライブラリサポートの方がどちらかというと力点になっているように見える。オブジェクト表現等も通常のLuaと同等ということになる。
LTR(Lua Tiny RAM)はC APIを想定した専用のクロージャであるlightfunctionとROM化されたtableであるrotableを実装する。どちらもLuaコードから直接定義することはできない。つまり、純粋にアプリケーション統合のための機能ということになる。
JerryScript (JavaScript)
- http://jerryscript.net/
- 本家
- http://jerryscript.net/internals/
- 充実した内部解説ページ
元Samsung、現JS Foundation( https://github.com/jerryscript-project/jerryscript/pull/1446 )のJerryScriptは、16bitの圧縮ポインタを採用し、512KiBヒープを表現する。オブジェクトの各プロパティは線型リストに接続され、さらに参照のキャッシュとして"LCache"と呼ぶハッシュテーブルを持っている。このレベルの考察を持っている組込みJavaScriptは意外と珍しい。
ワードは8バイトアラインポインタで、fixnumは29bits。
また、JerryScriptはASTを構築せず直接バイトコードをemitする。MicroPythonはASTを構築してconstant folding等の最適化を実装しているのと比べると対称的と言える。
Espruino (JavaScript)
- https://www.espruino.com/
- 本家
- https://github.com/espruino/Espruino
- 処理系の実装
- http://www.espruino.com/Internals
- 内部解説
- https://github.com/espruino/Espruino/tree/6a01f1df3de46fd12d711e12703cb7fcf8617f0e/src
EspruinoはJerryScriptのようにバイトコードを出力するのではなく、パーサが直接コードを実行する。歴史的にはこちらのデザインの方が一般的だった気がするが、mrubyやLuaのようなバイトコード型の実装が組込み言語として一般化したので比較的珍しい構成と言える。
ヒープは16bytesまたは12bytesの"block"単位で処理される(32bitポインタ環境では32bytes)。特にオブジェクトを1024個以下を想定して12bytesで済ませるモードは強烈な割り切りと言える。stringやバッファは複数のblockを占有してポインタ用のフィールドに実データを埋め込んでいる(1ブロックあたり4〜5バイト)。これはオブジェクト管理方法を相当に単純にできるが当然オーバーヘッド面では不利になる。
Espruinoの置いているデザインゴールがすごくて:
Espruino is designed to run on devices with very small amounts of RAM available (down to 8kB) while still keeping a copy of the source code it is executing so you can edit it on the device. As such, it makes some compromises that affect the performance in ways you may not expect.
Forthでもこんなのやらないと思う。
mjs (JavaScript)
- https://github.com/cesanta/mjs
- 本家
- https://mongoose-os.com/blog/mjs-a-new-approach-to-embedded-scripting/
- プロジェクトの告知
組込みHTTPサーバのmongooseで知られるCesantaの組込みJavaScriptエンジンmjsは、旧v7( https://github.com/cesanta/v7 )を受けついでいるもので、RAM footprintは脅威の1KiBとしている。もっとも、RegExpのような標準ライブラリを欠いている他、言語的には相当な制約を設けている。Schemeで言うと:
- lambdaなし。letのみ。
- eqv? なし。 eq? のみ。
- stringはbytevectorのsyntax sugar。
ただしJSON parser等は備えている。GCやオブジェクト表現にはコレといった特徴はない。
mjsは自社のMongooseOS用のJavaScriptインタプリタ( https://mongoose-os.com/docs/quickstart/using-javascript.html )として使用されていて、そこでは "One of which is an mJS library that adds JavaScript prototyping ability." と明確にプロトタイプ用の環境であることを打ち出している。
実装はバイトコードベースのインタプリタでヒープ実装も普通。ASTを持たず、直接バイトコードをemitする。
KeycloakとGitBucketとRocketChatをリバースプロクシ以下に置いて認証させる
ちょっと諸般の事情で製作中のゲーム(teslawire)で使うゲームサーバのコンポーネントを可能な限り既製品で構成することになった。
元々はゲームAPIサーバと自前のOpenID Connect認証ブローカーで済ませるつもりだったのが、既存の企画を生かしたまま既製品をあてはめるとすごい事に:
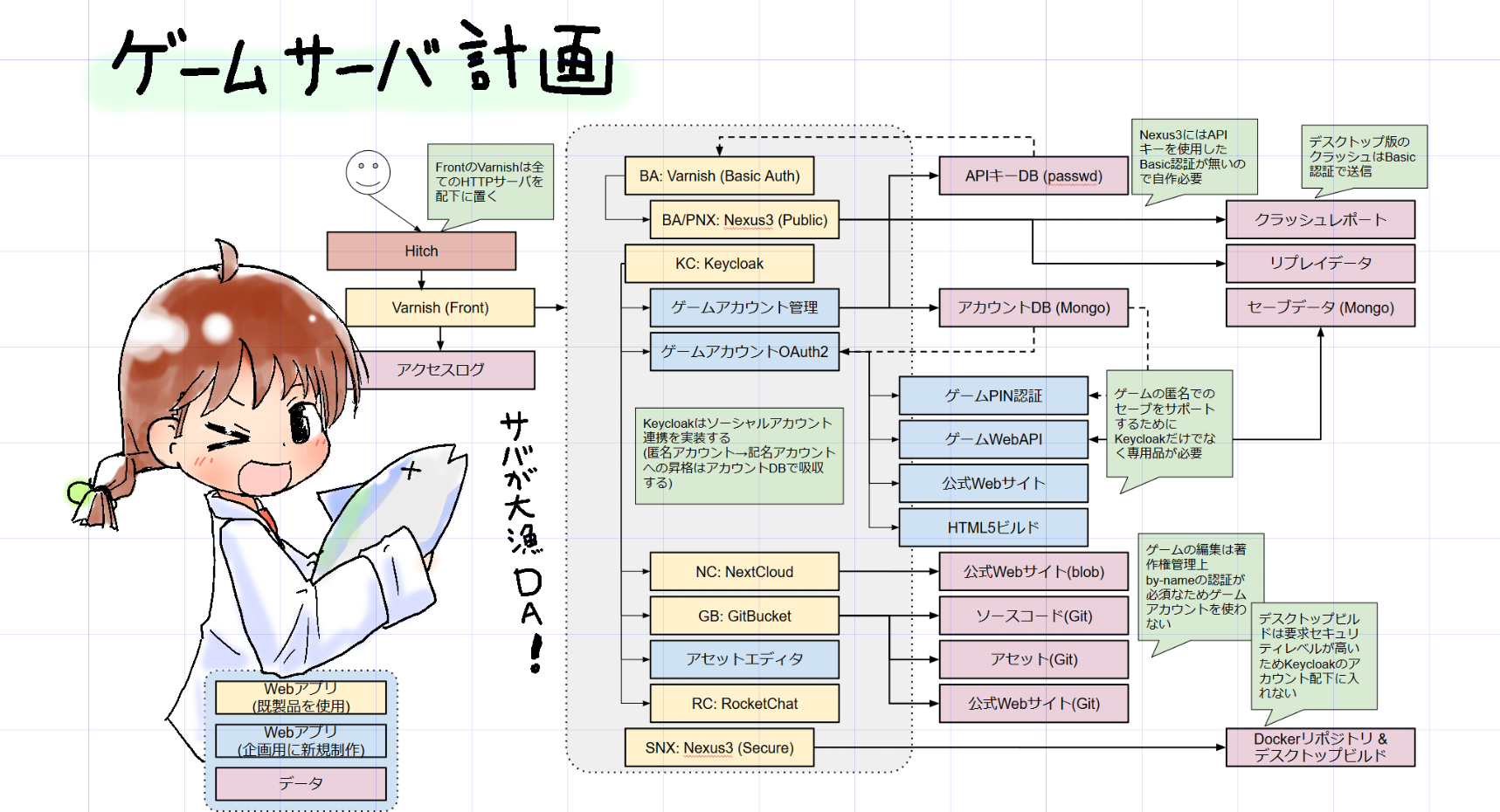
... 実際のゲームサーバがどうなるかはまだ検討しきれていないが、とにかく、大量のWebAPIサーバを抱えるシステムになってしまう。
一番重要なポイントは、1アプリ1コンテナを徹底してDocker前提の計画としたこと。世間的によく使われる普通のワークフローを可能な限り採用する方向にした。その他製品の選択としては:
- HTTP(S)リバースプロキシは当初計画ではnghttp2を使った自前のWebサーバだったが、VarnishとHitchの組み合せにした。nginxとかに比べて個人的に(多少)使い慣れているので。。Varnishは次のバージョンでUNIX Domain Socketを使ったbackendが使えるようになることと、HTTP/2の終端も一応できるようになったりと機能性としては十分と考えている。
- IAM(IdP)実装としてはKeycloakを選定。Gluu ( https://gluu.org/ )のような他の競合製品と比べて一番将来性が有るんじゃないかと思っている。また、内部APIが比較的しっかりしていてゲーム側の仕様に合わせた拡張が比較的容易そうなのもポイント。
- リポジトリサーバは Sonatype Nexus3。これは以前から採用。
- コントリビューション用にNextCloud、GitBucketとRocketChatを採用。NextCloudは、いわゆるアップローダやベータビルドの配布場所として使用する。将来的にはゲーム側にクラッシュリポータを用意したいが。。GitBucketはソースコードビューアとしての使用(ネタバレ防止のためシナリオデータはGitHubではなくプライベートリポジトリに置く)、RocketChatは2Pプレイのデバッグ時など細かいコミュニケーションが必要な場合に使用。世間的にはRocketChatのようなSlack cloneとしてはMattermostが有名で、実際Mattermostの方が完成度が高いと思うが、いわゆるSSOがEnterprise版専用で今回の目的に合わないので不採用。同様の理由でownCloudでなくNextCloudにした。
最大のポイントは自前のIdPから既製品のKeycloakへの乗り換えで、アプリケーション間の接続をOpenID Connectに統一する等アーキテクチャ上の大きな変更が必要になる。
上手くいっていないこと
- https://github.com/okuoku/tew-serv/issues/1
- Keycloakはユーザのプロファイルピクチャを直接的にはサポートしていない。個人的には超重要な機能だと思っているのでどうにかしたいが良いアイデアがない。
Keycloak自体は、各アカウントにメタデータを付けることができ、そのメタデータはAPIを通じてアクセスできるし、OpenID Connectのclaimとして送出することもできる。また、そもそも、GitBucketはOpenID Connectのpictureに現状対応していない等対応状況もマチマチになっている。
- https://github.com/okuoku/tew-serv/issues/2
- GitBucketはユーザにE mailアドレスが必要。システムではあんまりe-mailアドレスを処理したくないが、GitBucketはE-mailを必須としている https://github.com/gitbucket/gitbucket/blob/f13a473b4ea11aaecfc74378aef7329b2888c35e/src/main/scala/gitbucket/core/service/OpenIDConnectService.scala#L80 。
これに対する解決策としては単にダミーのe-mailアドレスを生成して埋めてしまう手があるが、そもそも半匿名ユーザを大量に抱えること自体があんまり目指すモデルでは無いような気もしている。よくあるやりかたとしては、誰でも名乗ることができる"mob"ユーザを用意し、それをGitBucket上での唯一のユーザとして共有することが考えられるが。。
各Webアプリをリバースプロキシ配下に配置する
これ自体は散々他所でも繰り返されている話題だが、RocketChat以外は結構面倒だった。。
KeycloakはXMLで設定する必要があった。というわけで、Dockerコンテナからデフォルト設定を抜き出し、手でweb-contextを書き換えている。ちなみに、ここを書き換えても既に登録されたアプリケーションは自動的に追従しないので、設定はインストール時(= 最初のサーバ起動よりも前)に行う必要がある。
Keycloakはデフォルトでは "/auth" 以下のURLで操作するが、ここでは "/kc/auth" 以下に変更している。
<web-context>kc/auth</web-context>
(個人的には伝統的にアプリケーションに2、3文字のプレフィックスを付け、ポート番号でのマルチプレクスは極力行わないようにしている。今回はKeycloakなので"kc"。)
Keycloakは自分に設定されたURLスキームを推論せず、常に X-Forwarded-Proto に従うため、オプション PROXY_ADDRESS_FORWARDING をKeycloak側に設定した上で、Varnishからは
set req.http.X-Forwarded-Proto = "https";
のようにして、X-Forwarded-Proto を設定してやる必要がある。
GitBucketは設定にアプリケーションURLの設定が有るが、何故かリバースプロクシ側でもURLをリライトしないと上手く動かなかった。たぶんプロクシ側が正常に設定できていないが、ログを見ても判然としなかったので後回し。
set req.url = regsub(req.url, "^/gb/", "/");
この手のURL書き換えはVarnishの得意分野。ここでは、先頭の /gb/ を除いている。こういうURL変換は、Webアプリ側で /gb/ が付くようなURLを使われるとダメになるため良くない。
KeycloakにTwitter認証ボタンを付けて、生成されるユーザ名に"twitter"をプレフィックスする
単純にアカウントの認証をTwitterで行うだけならば、Qiitaに書いてある通りにすればできる。
- https://qiita.com/tamura__246/items/02b3b75f36a22d0c960a
- Keycloakのソーシャル連携(SNS連携)を試してみる
ただ、これだと"Twitterでサインイン"ボタンを押した後に(Keycloak上の)アカウントの登録フローに飛ばされてしまう。この登録フローは不要なので無効にする。サインインフローをカスタマイズするためには、login flowを修正する必要がある。デフォルトでは
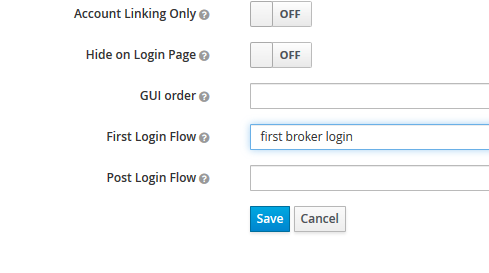
のように、"first broker login"が割りあてられているが、このフローは左の"Authentication"メニューから別のフローを作成して置き換えることができる。
というわけで、最初の"Review Account"がDISABLEDになっているフローを作成して、割り当てることでほぼ期待通りのUIフローになった。
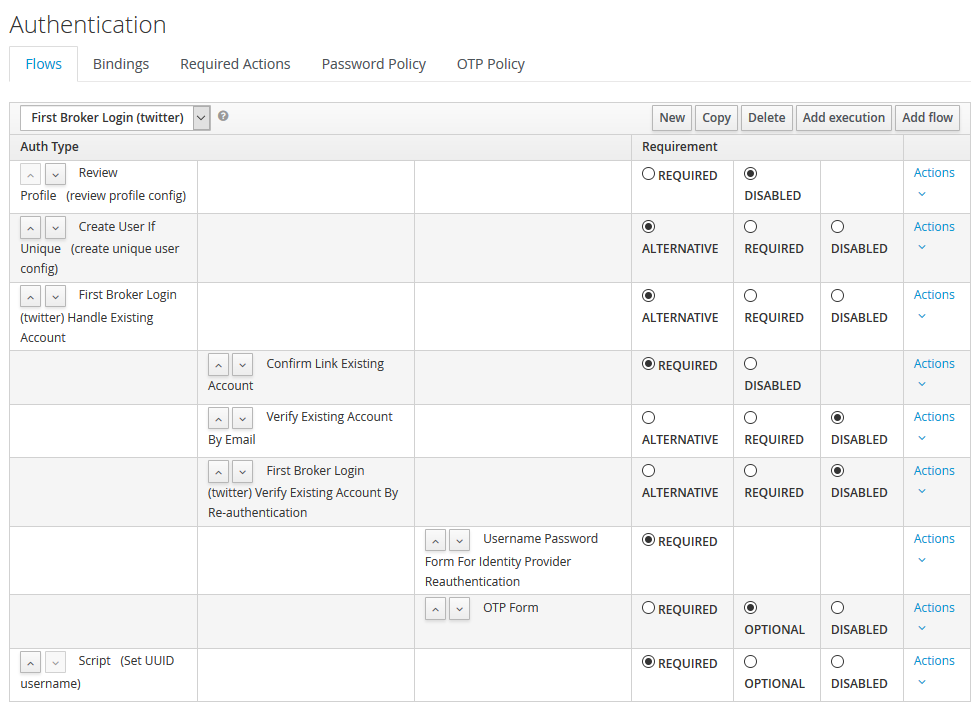
最後に付与されている"Set UUID username"はユーザ名をtwitterから指定されたものではなくUUIDに置き換えるもので、
// import enum for error lookup AuthenticationFlowError = Java.type("org.keycloak.authentication.AuthenticationFlowError"); function authenticate(context) { user.setUsername("twitter" + user.getId()); context.success(); }
のようなスクリプトを与えている。スクリプト内では、KeycloakのJavaDocに有るような各種オブジェクトとメソッドがそのまま使用できる。例えば変数userには、認証中のユーザを表現するUserModelオブジェクトが渡ってくるので、そのメソッドsetUsername()を呼べばユーザ名をオーバーライドできる。
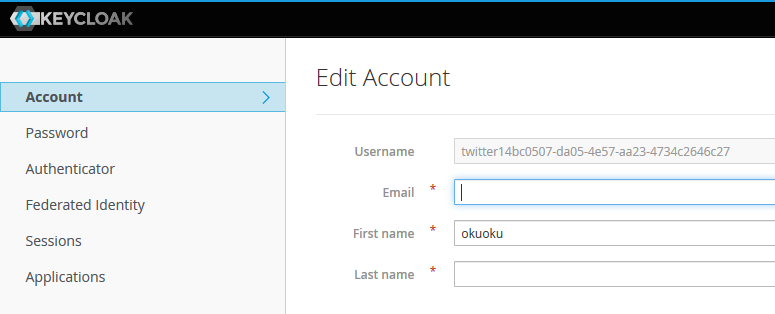
作成されたアカウントが twitter + UUID の形式になっていることが確認できる。
GitBucketの認証をKeycloakの提供するOpenID Connectで行う
実際に接続方法はGitBucketのWikiに有り https://github.com/gitbucket/gitbucket/wiki/OpenID-Connect-Settings keycloakでの設定サンプルも有るのでコレに従えばOK。今のところ、GitBucketが公式で配布しているDockerイメージは4.20で、OpenID Connectに対応していない。というわけで、4.21を使ったDockerfileを公式のDockerfileを元に用意した。
重要なポイントは、OpenID Connectの接続時にGitBucket → Keycloakの接続が行われる点で、このために、テスト環境で使用している自己署名証明書をGitBucket側のTruststoreに追加する必要があった。これをやっておかないと単に"internal server error"となって認証に失敗する。
COPY out.cer /gitbucket/ # keytool is an interactive tool... RUN echo yes | keytool -keystore /etc/ssl/certs/java/cacerts -storepass changeit -importcert -file /gitbucket/out.cer
("changeit"がデフォルトのキーストアパスワードになっている。)
更に、テスト環境ではmDNSを使ってホストのIPアドレスをlookupしているが、Dockerコンテナ内部からは基本的にmDNS lookupはできないため、docker-compose.yamlにextra_hostsを追加して静的に/etc/hostsに追加してやる必要がある。
extra_hosts: - ubuntults.local:${MYIP4}
ここでは、mDNSホスト名としてubuntults.local、実際のIPv4アドレスは環境変数MYIP4に格納しているものと仮定している。
RocketChatの認証をOAuth2で行う
RocketChat自体はSAMLに対応しているのでそちらを使うのがスジな気もするが、どうもKeycloakが生成する生のRSA証明書が扱えないようなので一旦OAuth2で試してみた。
OpenID ConnectはOAuth2上に実現されているため、KeycloakのOpenID Connect実装をOAuth2実装と見做して認証に使用できる。Keycloakに作成したRealmの名前が"Check"の場合、
- URL: https://ubuntults.local:801/kc/auth/realms/Check/ ← /kc/ は通常のKeycloakでは付かない。
- トークンパス: https://ubuntults.local:801/kc/auth/realms/Check/protocol/openid-connect/token
- 介して送信されるトークン: "ヘッダ"
- 個人情報パス: https://ubuntults.local:801/kc/auth/realms/Check/protocol/openid-connect/userinfo
- 認証パス: https://ubuntults.local:801/kc/auth/realms/Check/protocol/openid-connect/auth
- ID: RocketChat ← Keycloakの"Clients"を選んだときに表示される名前
- シークレットキー: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx ← "Clients"で"Access Type"を"confidential"に設定したときに現われるタブ "Credentials" に記入されている
- Username field: preferred_username
で、GitBucket同様、自己署名証明書の対策も必要になる。RocketChatはnode.jsで書かれているため、単に NODE_TLS_REJECT_UNAUTHORIZED=0 を環境変数に設定すればチェック自体を無効化できる。
# Allow self-signed certificate for now (for OAuth2) - NODE_TLS_REJECT_UNAUTHORIZED=0
... たぶんちゃんと証明書をインストールした方が良いが、どうせ本番環境ではLet's encryptするのでとりあえず逃げておく。
chibi-scheme 0.8 / Sagittarius + MinGW / Racketは7でChezに移行する?
小ネタ3つ。
chibi-scheme 0.8.0
いくつかWin32対応を入れたchibi-scheme 0.8.0がリリースされた。
組込み言語として現状欠けているのはWin64サポートなのでどうしたもんか考え中。bignumさえ無ければどうにでもなる気がするけど、chibi-schemeのbignum実装はfixnum * fixnumを格納できる整数型が言語に存在することを前提にしていて、Win64のようにfixnumで64bit巾整数を使ってしまうと、もう処理系の整数型でbignumの期待を満たすものがなくなってしまう。(gccはint128_tが使えるため64bitアーキテクチャでもアーキテクチャのword * wordを直接処理できる。)
簡単には演算を全てマクロなりインライン関数でwrapしてしまうというのが考えられるけど、元のgcc実装のパフォーマンスに影響せずに置き代える方法が見つからなかった。当然メンテナンス性にも影響する。
もう一つはWin64ではfixnumを32bit巾に縮小するという手が考えられるが、chibi-scheme内部では言語ポインタをfixnumで表現できることを前提にしている箇所がいくつか有るため諦めた。
gcc専用の機能は一度依存するとなかなか抜け出せなくなってしまうのが絶妙と言える。yuniもネスト関数を使ってコールバックにコンテキストを渡すことを検討していた時期があった。
- ネスト関数を使ってqsortのコールバックにctxを持たせる例:
#include <stdio.h> #include <stdlib.h> int compar_with_context(int ctx, const void* a, const void* b){ /* 本来はこれをスクリプトにしたい */ int aa; int bb; aa = *(int*)a; bb = *(int*)b; printf("ctx: %x, a: %d b: %d\n", ctx, aa, bb); return (aa - bb); } void qsort_with_context(int ctx, void* base, size_t cnt, size_t w, int (*cb)(int, const void*, const void*)){ int invoke(const void* a, const void* b){ /* ネスト関数を使用してフレーム外の自動変数 ctx にアクセスする */ return cb(ctx, a, b); } qsort(base, cnt, w, invoke); } int main(int ac, char** av){ (void)ac; (void)av; int context = 0x1234; int arr[] = {9, 2, 5, 5, 1, 0}; qsort_with_context(context, arr, 6, sizeof(int), compar_with_context); for(int i; i!= 6; i++){ printf("res(%d): %d\n", i, arr[i]); } return 0; }
ネスト関数はclangではサポートされていないため諦めた。(ちなみにC++ lambdaはこの目的には使えないため、コールバックのABIを維持したまま、コールバック関数にコンテキストを持たせるのは現状の言語標準では実現不能な気がしている)
Sagittarius + MinGW
SagittariusがMinGWでもビルドできるようになったので試してみたが、ちょっと自分の実力では安定して動作させられそうにないので諦め気味。。
- hg-gitからhgにコミットする?
実はできると勝手に思っていたが、hg-gitミラー( https://github.com/ktakashi/sagittarius-scheme )の作業をhgに戻す簡単な方法は無さそう。hg-gitはgitリポジトリからは常に一意なhgリポジトリを作るが、hgリポジトリをgitに変換したリポジトリを取り込んでも一意なリポジトリには戻らない(git-svnと異なりコミットログに入っているメタデータを認識しない)ため素直にhg上で作業する(Gitとのコマンド対照表が https://www.mercurial-scm.org/wiki/GitConcepts に有る)か、hg-gitミラーでの作業をgraftによって持ってくるかという方法になる。
今回はpull request( https://bitbucket.org/ktakashi/sagittarius-scheme/pull-requests/11/win32-fix-mingw-build-with-mingw64-native/diff )をGitで作ったコミットをgraftで持ってくるという手法で送信したが普通にdefaultブランチに誤爆したので公開されるコミットはhgで作業した方が良いだろう。。
- C/C++間でのDLL変数の扱いの差
Sagittariusの拡張モジュールはWin32上では何故かC++でコンパイルされている。MinGWでこれをやると依存DLLが増えてしまう(あるいは明示的にstatic linkさせる必要がある)ためどうにかしたいところ。
拡張モジュールは以下のようなコードを持ち:
#ifdef __cplusplus extern "C" { #endif extern __declspec(dllimport) void* Sg_ProcedureClass; #ifdef __cplusplus }; #endif struct tmp { void* addr; }; struct tmp check = { &Sg_ProcedureClass + 7 };
Windows上では、このコードはC++ではビルドが通り、Cではビルドが通らないという結果になる。
Microsoft(R) C/C++ Optimizing Compiler Version 19.11.25547 for x64 Copyright (C) Microsoft Corporation. All rights reserved. check.c check.c(14): error C2099: 初期化子が定数ではありません。
これはdllimportを付けたオブジェクトは定数とは見做されなくなる制約に依る。C言語では静的変数の初期化は定数で行わなければならないが、C++ではコンストラクタが使用できる(ため定数でなくて良い)。
One drawback to using this attribute is that a pointer to a variable marked as dllimport cannot be used as a constant address. However, a pointer to a function with the dllimport attribute can be used as a constant initializer; in this case, the address of a stub function in the import lib is referenced. On Microsoft Windows targets, the attribute can be disabled for functions by setting the -mnop-fun-dllimport flag.
というわけで単にdllimportを止めるか、DLL/.soを超えた変数の参照を行わないようにする必要がある。chibi-schemeやyuniは拡張モジュールからは初期化用APIをエクスポートし、ロード時に明示的に呼び出す方式にしている。関数のみを動的モジュールとの交信に使用するのは歴史的事情に依る: 遅延ロードや呼び出しのhookといった処理は関数の呼び出しの方が適用しやすい。
- 低確率でextlibsのテスト中に刺さる
1/20くらいの確率でテスト中に固まる現象がMinGWでビルドしたデバッグ版でのみ発生する。何らかの理由でSg_WaitWithTimeoutが無限待ちになっているような気がするが原因不明。
- Visual Studioで見たparallel stack。(VSはDWARFが読めないためシンボルはあまり正しくない - 周辺の適当なDLLシンボルを出している)
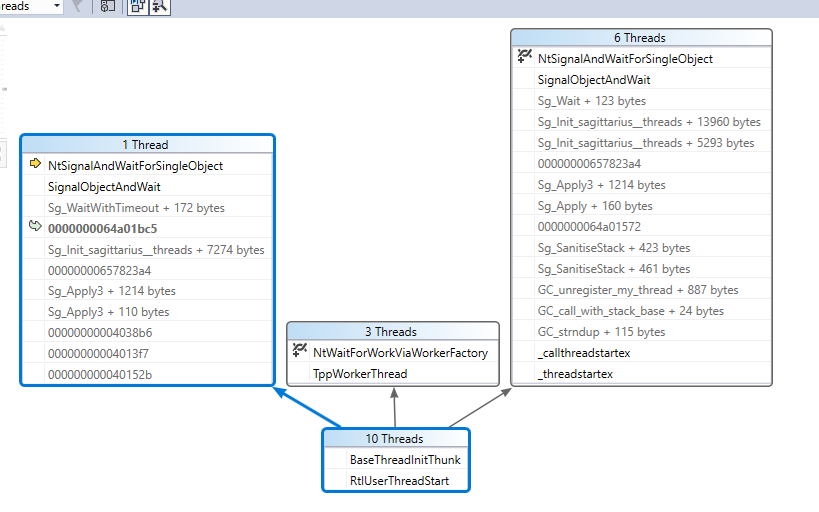
Sagittariusは条件変数の絶対時刻タイムアウト(pthreadのもの)をsleepに使用しており、Windows上でもCritical Sectionを使用して条件変数をエミュレートすることで同じようなロジックを実現している。絶対時刻タイムアウトはタイムアウトの設定の瞬間にシステム時刻が変動すると待ち時間が一緒に変動するという問題があり、原理的には待ち時間が異常になる可能性はある。
Windows APIは相対時刻を取るため、Sagittarius自身の移植層でAPI呼び出し前に相対時刻に変換しなおしている。そもそも、実際にはLinuxのような他のOSでも内部で相対時刻に変換しているためこの挙動自体はWindows固有では無いとも言える。。(例えば、Linuxのプリミティブであるfutex(2)はnanosleep(2)と同じような相対時刻を取る。)
Racketは7でChezに移行する?
- https://blog.racket-lang.org/2018/01/racket-on-chez-status.html
- http://www.cs.utah.edu/~mflatt/racket-on-chez-jan-2018/
- 少し長いバージョン。Chezに加えられた拡張についても説明がある。
- https://github.com/racket/racket7
Racket on Chezについての説明がRacketのblogに有る。Racketは現状PLT Schemeから発展した処理系となっているが、バックエンドとしてChez Schemeを使用し独自のScheme処理系から移行するようだ。Chez Scheme自体は非常にScheme的というかライブラリ等は基本的にバンドルしない方針となっているので、Racketがいわゆる"battery included"な処理系としての立場を確立するかもしれない。
... yuniはScheme処理系としてRacketを使っているので、Chezへの移行が完了したタイミングでRacket移植はおそらく不要になるだろう(パッケージシステムへの対応自体は必要かもしれないけど)。
この努力の中で、RacketのOS移植層はnon-blockingなrktioライブラリに整理されて従来のRacket6とChez版であるRacket7に共用されている。
Racketといえばtyped racketといった様々な言語が使える点が特徴なわけで、ランタイム自体の機能性はあまり押していかないというところなのだろうか。他にChezに移行できそうな環境といっても思いあたらないので、Chezへの移行がトレンドになるようなことも無さそうではあるけど。
1パスS式アセンブラCOMFY-65を読む
S式をベースにした言語はそれこそLisp/Schemeのような高級言語からWeb Assemblyのテキスト表現( https://webassembly.github.io/spec/core/text/index.html )のようなある種の中間表現まで巾が有るが、一番ギリギリのラインは、COMFY-65やSassyのようなS式アセンブラだろう。
- http://home.pipeline.com/~hbaker1/sigplannotices/sigcol03.pdf
- COMFY言語の解説(BAKER3) - (読み飛ばして良い)
- http://home.pipeline.com/~hbaker1/sigplannotices/sigcol04.pdf
- COMFY-65の解説とソースリスト(BAKER4) - COMFYコンパイラの実装(Emacs Lisp)、プリミティブの解説
- http://home.pipeline.com/~hbaker1/lisp/ にソースが置いてある
- http://sassy.sourceforge.net/sassy-Z-H-1.html
これらはアセンブラなのでレジスタの割当は自前で行う必要があるが、ジャンプ命令/分岐命令の替わりにCOMFYと呼んでいるプリミティブを使用できる。COMFYの記事では6502とZ80に言及しているが、これらはそもそもレジスタが少いアーキテクチャなのでレジスタの割り当てに悩む必要性はあまりない。
1pass実装の難しさ = 可変長命令のfixup
いわゆる1pass言語の難しさは色々な側面がある。ココで度々引いているTURBO Pascalでは、高級言語としての言語仕様から実際のアセンブルに至るまで可能な限り1passとなるように設計されている。当然TURBO Pascalでは最適化は犠牲になっているが、同時に、生成されるコードにもある種の"特徴"が表われる結果になっている。
例えば、WHILEループが生成するコードを考えたとき、
WHILE l1: condition ;evaluate condition J.. l2 ;:condition met ★ 条件判断 JMP l3 ★ 条件不成立時にループ本体を避ける l2: statement JMP l1 ;try again l3: ;end of loop
条件判断を逆方向にすれば"JMP l3"を避けることはできるんじゃないかという気はする。しかし、1passコンパイラではこの戦略は取れない。8086の条件分岐命令は全てshortジャンプ(飛び先のアドレスが命令相対の符号付き8bitアドレス)であるため、ループの本体が127バイトに収まらない限り"JMP l3"の省略は不可能であり、コードを左から右に解釈してコードを生成していく1passコンパイラではループ本体のサイズを事前に知ることができない。(実際のTURBO PascalはCASE文や他のケースである種のバックトラックを行うことがある。)
...もちろん最初に最も長いジャンプを想定してコード生成しても、後から生成したコードをパッチする方向の実装によってジャンプを最適化することは不可能ではない。この点はCOMFYの作者も指摘している。
Since one already knows the location to which one must jump at the time a branch is emitted, as well as the location of the current instruction, one can easily choose the correct short/long jump sequence.
COMFY-65はもっと直接的なトリックで1passを実現している。つまりプログラムを完全に逆順で生成し、コードも高位アドレスから低位アドレスに向かって書き込みを行っていく。これは要するに深さ優先のトラバースに相当するため、単にコード生成手続き(compile)を再帰的に呼べば良い。これは再帰呼び出しのためのコストがコンパイル時に掛かり、(通常のPIC - Position Independent Code - のような)プログラム再配置のための考察が現実的なワークロードのためには必要になる。
(defvar mem (make-vector 10 0) ;; 生成した機械語を格納するためのベクタ "Vector where the compiled code is placed.") (setq mem (make-vector 100 0)) (defvar f (length mem) ;; 生成先を表わすポインタ "Compiled code array pointer; it works its way down from the top.") (setq f (length mem)) (defun init () ;; 初期化手続き (fillarray mem 0) (setq f (length mem))) - snip - (defun gen (obj) ;; 1バイト出力手続き ;;; place one character "obj" into the stream. (setq f (1- f)) ;; 1減算 (aset mem f obj) f) ;; 書き込み先のアドレスを返す
COMFYコンパイラ
(以下はBAKER4の方を参照している。)
COMPFYコンパイラのインターフェースは単純で、
(compile 式 <win-address> <lose-address>) ;; => address
のようになっている。式が分岐命令(test)であった場合は条件によってwinまたはloseのいずれかにジャンプするコードを出力する。(Schemeで言うところのcaseのように分岐先が多数に渡る場合は小細工するしかない。)
COMFYでは、式を以下の3種に分類している:
- test: 分岐命令。条件によってwinまたはloseのアドレスを次に実行するようなコードを出力する。
- action: 通常の命令。IP(Instruction Pointer: 命令ポインタ)を書き換えない命令全て。
- jump: ジャンプ命令。IPを書き換える命令で6502の場合RTS(callからのリターン、BAKER4ではreturn)およびRTI(割り込みからのリターン、BAKER4ではresume)。
分岐の生成はかなり単純化される: コードを逆順で生成することにより、COMFYのプリミティブで生成されるジャンプ先アドレスは常に既知となるため、単にshort jumpが生成できるかどうかを検証して必要なジャンプ命令を出力するだけとなる。
(defun inv (c) ;; 6502条件分岐OPコードの条件を反転させる ;;; invert the condition for a branch. ;;; invert bit 5 (counting from the right). (logxor c 32)) (defun genbr (win) ;;; generate an unconditional jump to "win". (gen 0) (gen 0) (gen jmp) (ra f win)) (defun 8bitp (n) (let* ((m (logand n -128))) (or (= 0 m) (= -128 m)))) (defun genbrc (c win lose) ;;; generate an optimized conditional branch ;;; on condition c to "win" with failure to "lose". (let* ((w (- win f)) (l (- lose f))) ;;; Normalize to current point. ;; w = winアドレスまでの距離、l = loseアドレスまでの距離 (cond ((= w l) win) ;; win == lose ならそもそも分岐でない。何もせず帰る。 ;; lose側が直下(距離ゼロ)でwin側にshort分岐命令で到達できるなら、short分岐命令を出力 ;; (genは8bit値を直接出力、cには分岐命令のOPコードが代入されている) ((and (= l 0) (8bitp w)) (gen w) (gen c)) ;; 逆にwin側が直下でlose側にshort分岐命令で到達できるなら、条件をinvで反転して出力 ((and (= w 0) (8bitp l)) (gen l) (gen (inv c))) ;; win/loseどちらも直下ではないがshortで到達できる場合、loseの分岐ジャンプ、winの分岐ジャンプ の順に出力 ((and (8bitp l) (8bitp (- w 2))) (gen l) (gen (inv c)) (gen (- w 2)) (gen c)) ;; (上記の逆パタン - win/loseのどちらかは2バイトぶん要件がゆるいため両者のチェックが必要) ((and (8bitp w) (8bitp (- l 2))) (gen w) (gen c) (gen (- l 2)) (gen (inv c))) ;; win側がshortで到達できないがlose側が到達できるケース ((8bitp (- l 3)) (genbrc c (genbr win) lose)) ;; fallback。長いジャンプ命令でloseに飛ばし、再帰してwin側の分岐命令を生成する (t (genbrc c win (genbr lose))))))
各プリミティブの実装
COMFYプリミティブのうち、not、seq、loop、if、whileはCompile内部で特別扱いされている。他のプリミティブはマクロで実装できる。
notは、単にwinとloseを逆にしてcompileを再度呼べば実装できる。seqも再帰的に生成されるが、上記のようにジャンプは最適化された形で生成されるので無駄は少い。
(defun ra (b a) ;; loop/whileで使用される: 一度生成したジャンプのアドレスをパッチする ;;; replace the absolute address at the instruction "b" ;;; by the address "a". (let* ((ha (lsh a -8)) (la (logand a 255))) (aset mem (1+ b) la) (aset mem (+ b 2) ha)) b) (defun compile (e win lose) ;;; compile expression e with success continuation "win" and ;;; failure continuation "lose". ;;; "win" an "lose" are both addresses of stuff higher in memory. (cond ((numberp e) (gen e)) ; allow constants. ((macrop e) (compile (apply (get e 'cmacro) (list e)) win lose)) ((jumpp e) (gen (get e 'jump))) ; must be return or resume. ((actionp e) (emit e win)) ; single byte instruction. ((testp e) (genbrc (get e 'test) win lose)) ; test instruction ;; 分岐命令 ((eq (car e) 'not) (compile (cadr e) lose win)) ;; not: win/loseを逆にして再帰 ((eq (car e) 'seq) (cond ((null (cdr e)) win) ;; (seq) は単にwinへ進む。 (t (compile (cadr e) (compile (cons 'seq (cddr e)) win lose) lose)))) ((eq (car e) 'loop) (let* ((l (genbr 0)) ;; ループ本体の末尾に配置するlongジャンプ命令 ;; (プログラムは逆順に生成しているので、これが先に生成される) (r (compile (cadr e) l lose))) ;; ループ本体をアセンブルする (ra l r) ;; (genbr 0)で生成したジャンプ命令をパッチする r)) ;; ループ先頭のアドレスを返す ((numberp (car e)) ; duplicate n times. (cond ((zerop (car e)) win) (t (compile (cons (1- (car e)) (cdr e)) (compile (cadr e) win lose) lose)))) ((eq (car e) 'if) ; if-then-else. (compile (cadr e) (compile (caddr e) win lose) (compile (cadddr e) win lose))) ((eq (car e) 'while) ; do-while. (let* ((l (genbr 0)) (r (compile (cadr e) (compile (caddr e) l lose) win))) (ra l r) r)) ;;; allow for COMFY macros ! ((macrop (car e)) (compile (apply (get (car e) 'cmacro) (list e)) win lose)) (t (emit e win))))
逆方向のジャンプを生成する必要のあるloopおよびwhileは特別で、一度ゼロ番地へのlong jumpを生成してから ra 手続きでループ先頭のアドレスをパッチするという手法を取っている。
非同期I/O APIの設計がなかなか難しい
yuniで実用的なプログラムを書くためには、どうしても非同期I/Oライブラリが必要になる。というわけで黙々と設計しているけれど、これがなかなか難しい。
非同期I/Oライブラリの難しさ
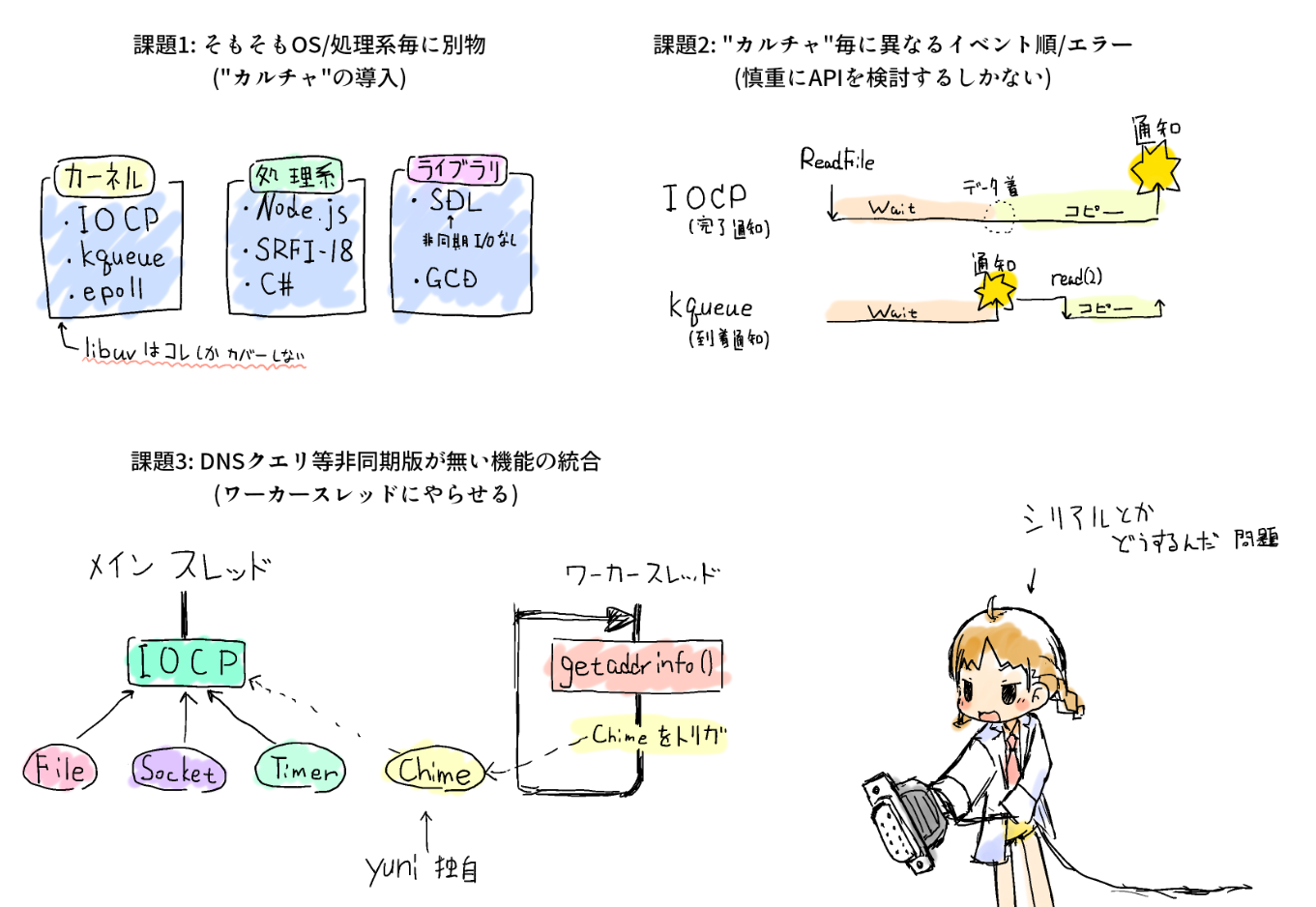
- そもそもOS/処理系毎に別物が必要
"非同期I/Oライブラリなんてlibuv一択だろ"という意見も有るかもしれないし、実際、Node.jsはlibuvのデザインの実用性を証明しつづけていると言える(実際には逆で、Node.jsのOS抽象化レイヤとしてlibuvが実装されている)。が、libuvはカーネル機能の抽象化でしかなく、同じデザインがyuniに適用できるとは限らない。yuniは既にKawa(Java上のScheme実装)やIronScheme(.net上のScheme実装)をターゲットしているので、これらでも動作するような配慮が必要になる。
もし、yuniの非同期I/Oライブラリを単なるlibuvのバインディングとするならば、I/Oを使ったスクリプトを実行するだけでFFIが必須になってしまう。libuvは大体のOSで動くし、libtuvのようなマイコン向けの派生( https://github.com/Samsung/libtuv )まで有るが、それなりのサイズのライブラリをhard dependencyにしてしまうのは気が引けるという問題もある。
yuniでは、バックエンドとなる非同期I/O処理系を"カルチャ"と呼び、単一のプログラム内で複数のカルチャを同時に使用できるように配慮することにした。
- "カルチャ"毎に作法が異なる
この問題はlibuvで既に大体取り組まれているが、OSやライブラリによってイベントのトリガや処理順が大きく異なるため適当な抽象化が必要になる。
例えば、WindowsのIOCP(I/O Completion Port)ではユーザの発行した読み取りリクエストの完了が通知されてくるが、BSD/macOSのkqueueでは、"読み取り可能になった"というイベントが飛んでくるだけで、実際の読み取り要求はその後に発行する必要がある。
異なるカルチャ間で共通のプログラムを使い回すためには、慎重にAPIを設計するしかない。
非同期版が無い場合の配慮
重要なポイントは、非同期I/Oへの配慮が一切ないプラットフォームでも同じスクリプトを動かす必要がある点と言える。
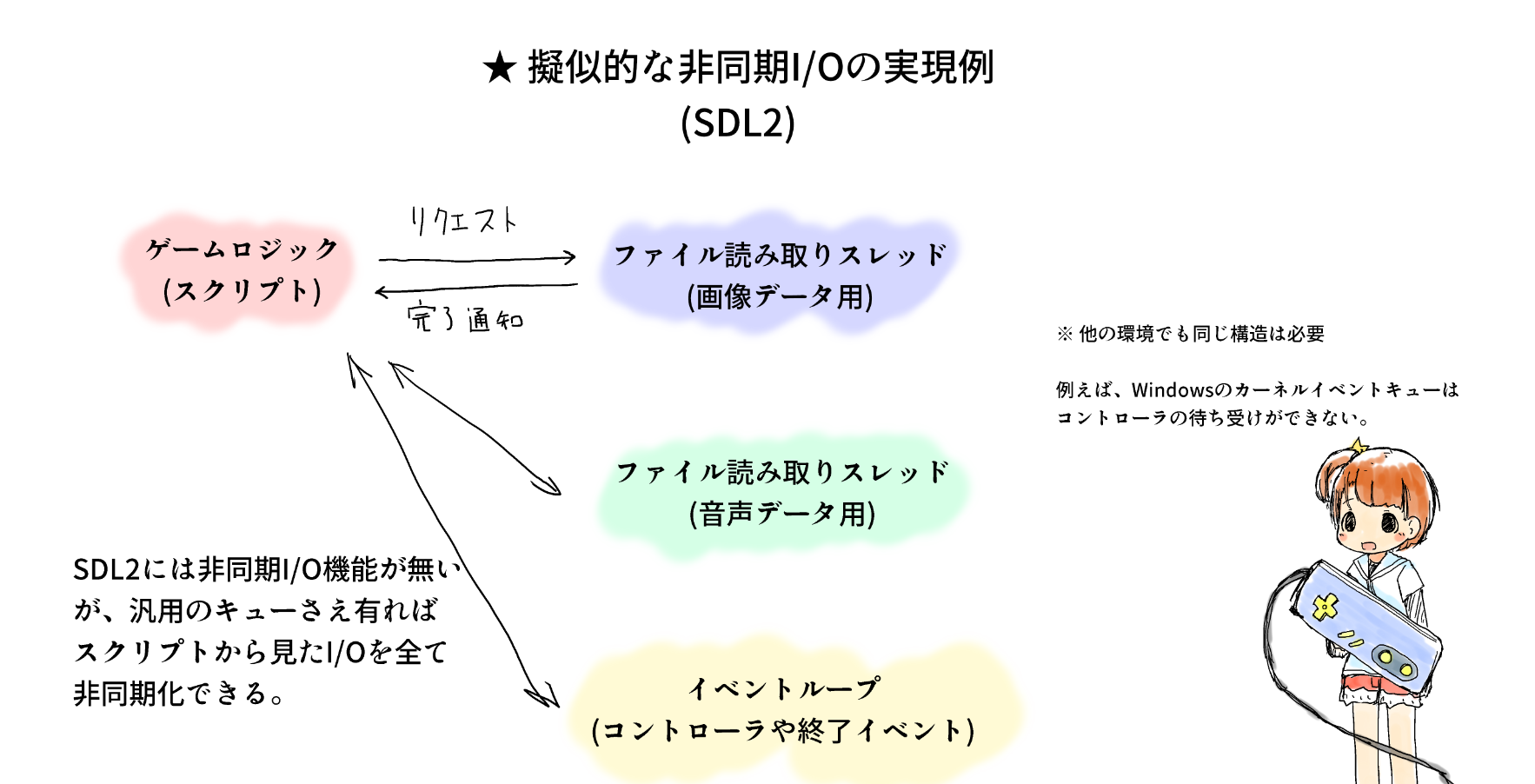
例えば、SDLはスレッドやファイルI/Oを抽象化しているが、そのファイルI/O機能には一切の非同期I/Oインターフェースが用意されていない。(この問題はC++標準ライブラリや、そもそも言語標準にスレッドの概念が無いR6RS/R7RSでも同じことが言える。)
このようなケースではワーカースレッドとキューが使われるが、単純に作ると1ストリーム1スレッドを用意することになってしまう。実際には、同じデバイスで複数のI/Oを併走させても無駄なことが多いため、無駄にスレッドを消費することになる。
中間解としては、I/Oの性質に合わせてスレッドを分割する、つまり:
- 読み取りの応答性が重要なオーディオは別のスレッドに分離する
- 読み取りの応答性が比較的どうでも良い画像データはスレッドを1つに集約する
ことで、オーディオデータの読み取りは直ぐできるようにしつつ、必要最低限のスレッド数で対応することができる。(ただし、実際のゲームではもっと真面目にリクエストキューを実装していることが多い)
... このような配慮をどうやってAPIにすれば、他の非同期I/Oを実装したカルチャと共通のプログラムにすることができるだろうか。。
SDL2のように一切非同期I/Oが存在しない環境も有るが、例えばDNS参照は殆どのOSで非同期インターフェースが存在しないため、規模の大小は別にしてどこかでは絶対に必要になる。ちなみにlibuvではライブラリ自体にDNS参照機能を持たせてこの問題を回避している。また、libuvにはスレッドプール機能もあるためイザとなればそちらに逃げることはできる。
マイナーな機能をどうやって抽象化するのか問題
libuvにはファイルコピー機能がAPIとして存在する( https://github.com/libuv/libuv/issues/925 )。実は各OSはファイルコピーを行うAPIをOSレベルで持っていることがあり、専用の最適化も想定されている(例えば、ネットワークファイルシステムであればサーバ上でコピーを行う等)。当然、これらをAPIとして用意しておかないとOSの最適化の恩恵は受けられない。
- http://docs.libuv.org/en/v1.x/fs.html#c.uv_fs_type
- UV_FS_COPYFILEが現時点では最後の追加となっている
例えばシリアルポートの入出力等はlibuvには無い。シリアルポートはたぶん有っても良いと思うけど、では電源イベントとかMIDIはどうか。。
SRFI-18がport入出力でブロックする問題
まぁ一旦Schemeにおけるスレッド実装の最大公約数と言えるSRFI-18( https://srfi.schemers.org/srfi-18/srfi-18.html )で試しに実装するかと思っていたが、どうもSRFI-18環境でSchemeのportとスレッドを共存させる方法が無いらしくどうしたもんか。。
例えば、chickenでは明示的に"I/Oによるブロックは全スレッドをブロックさせる"としている:
Blocking I/O will block all threads, except for some socket operations (see the section about the tcp unit). An exception is the read-eval-print loop on UNIX platforms: waiting for input will not block other threads, provided the current input port reads input from a console.
軽く調べてみたところ、SRFI-18を実装している処理系はネイティブスレッドを使用した実装と、いわゆるグリーンスレッド実装の2種類に分けられる:
- グリーンスレッド実装
- ネイティブ実装
- Gauche: http://practical-scheme.net/gauche/man/gauche-refe/Threads.html
- Guile: https://www.gnu.org/software/guile/docs/master/guile.html/SRFI_002d18.html (プリミティブ: https://www.gnu.org/software/guile/docs/master/guile.html/Threads.html )
- Sagittarius: http://ktakashi.github.io/sagittarius-online-ref/section613.html
portでブロックしても他のスレッドの実行を続けられるのはGambitと各ネイティブ実装だった。このため、仮に各処理系のグリーンスレッド実装を活用するにしても、Scheme portではなく処理系に固有のmultiplex手法を使う必要がある。
ちなみに、他の処理系は実装手法がまちまちで、
- promise/futureベースの実装
- Share nothing(オブジェクトのやりとりは明示的にchannelを使用する)
- nmosh
- 不明(存在するという噂)
- そもそもスレッドをサポートしていない
- Larceny
- Vicare
いずれにせよ、スレッドの無い処理系をサポートするためにはFFI経由での実装がどこかのタイミングでは必要になる。グリーンスレッド実装でFFI必須にするかは微妙なポイントと言える。
次の一手
とりあえず、ビルドトレース( http://d.hatena.ne.jp/mjt/20171204/p1 )で使用しているI/Oプリミティブ、つまり、
- プロセスとpipe
- ファイル
- Socket
を基本セットとして、これらは可能な限り多くの処理系でSchemeオンリーで実装できるように配慮することにする。残念ながらプロセスの起動処理とDNS lookupはどうやってもblockingになるが、今回はblockの期間が上界されるというポイントで妥協することにする。。(DNSでタイムアウトが起こるようなケースでは長くなってしまうが。。)
これらに用途を絞れば、スレッドをサポートしていない処理系でも、いわゆるselect()とnon-blocking I/Oさえサポートしていれば良いことになる。
ビルドトレースツールの制作 の1 - 準備
諸般の事情でnmosh製のビルドトレースツールをネイティブコードで書き直すことにした。週に10万回と起動されるツールなので、オーバーヘッドと安定性がそろそろ気になってきた。
ビルドトレースとは何か?
ビルドトレースとは、要するに"プロダクトのビルド中に実行されるコンパイラやリンカの起動コマンドラインを後から再生できるように収集する"ことで、個人的にソフトウェア品質管理手法として注目している。
一般的には、ビルドトレースはビルドシステムに組込まれて使われる。MSBuildに最近搭載されたBinaryLog https://github.com/Microsoft/msbuild/wiki/Binary-Log はその一例で、ビルドログを構造化されたログフォーマットに保存することができる。
Coverityのような静的解析ツールは、既存のコンパイラ起動プロセスを乗っ取ってビルドログを取得し、後から再生することで実際の静的解析を実装している。同様のものには、compile_commands.jsonを出力するBear https://github.com/rizsotto/Bear が有る。これらは、LD_PRELOADやその他のhook手法を使って実際の乗っ取りを実装している。
ビルドトレース自体を直接的にサポートしたビルドシステムも存在する。CMakeには CMAKE_EXPORT_COMPILE_COMMANDS、CMAKE_C_COMPILER_LAUNCHER や RULE_LAUNCH_COMPILEが有り、これらはビルド時に各種executableの実行をhookしたり、ビルドシステムにcompile_commands.jsonを出力させることができる。ただし、これはビルドシステム全体がCMakeで統一されていなければ意味が無い。(また、CMakeには既にserver modeが存在しビルドに関するメタデータの取得はそちらが推奨されつつある)
制作中のゲームの先代ビルドインフラ(impulse)ではMake/Ninjaの互換実装を用意し、そこでトレースを実施する方法を取った。互換実装では差分ビルドを実装せず、常にビルドを実行し全ゴールを到達させている。この互換実装のメンテナンスが工数的に難しい(& 内製のMakefile生成ツールが生成したMakefileしか処理できない)ので、もうちょっとシンプルなアーキテクチャでビルドシステムおよびトレースを実現しようというのが根底にある。
(ビルドシステムは基本的にCMakeを使用するが、UnityやUEのように自前のパッケージング方法論を持つツールとの統合が難しいのが課題として浮上してきたという事情がある。)
ビルドトレースのキモはトレースの実施自体ではなく、トレースデータを活用する側にある。しかし、意外とトレース取得自体にも良い考察が無いのが現状と言える。我々は普段GitHubなりなんなりでプロジェクトのソースコード自体は公開しているが、本来はビルドトレースとその分析結果も同時に公開されているべきで、それが有ると無いとではコード理解の効率が段違いになる(トレースが無い場合、手元でビルドしないと実際のビルド結果を入手できない)。良いエコシステムを構築するため、トレースによって取得されたログや分析の標準フォーマットを設計することがこの計画の重要な目的と言える。
必要なもの
今回実装しようとしているビルドトレースは次のように図解できる。
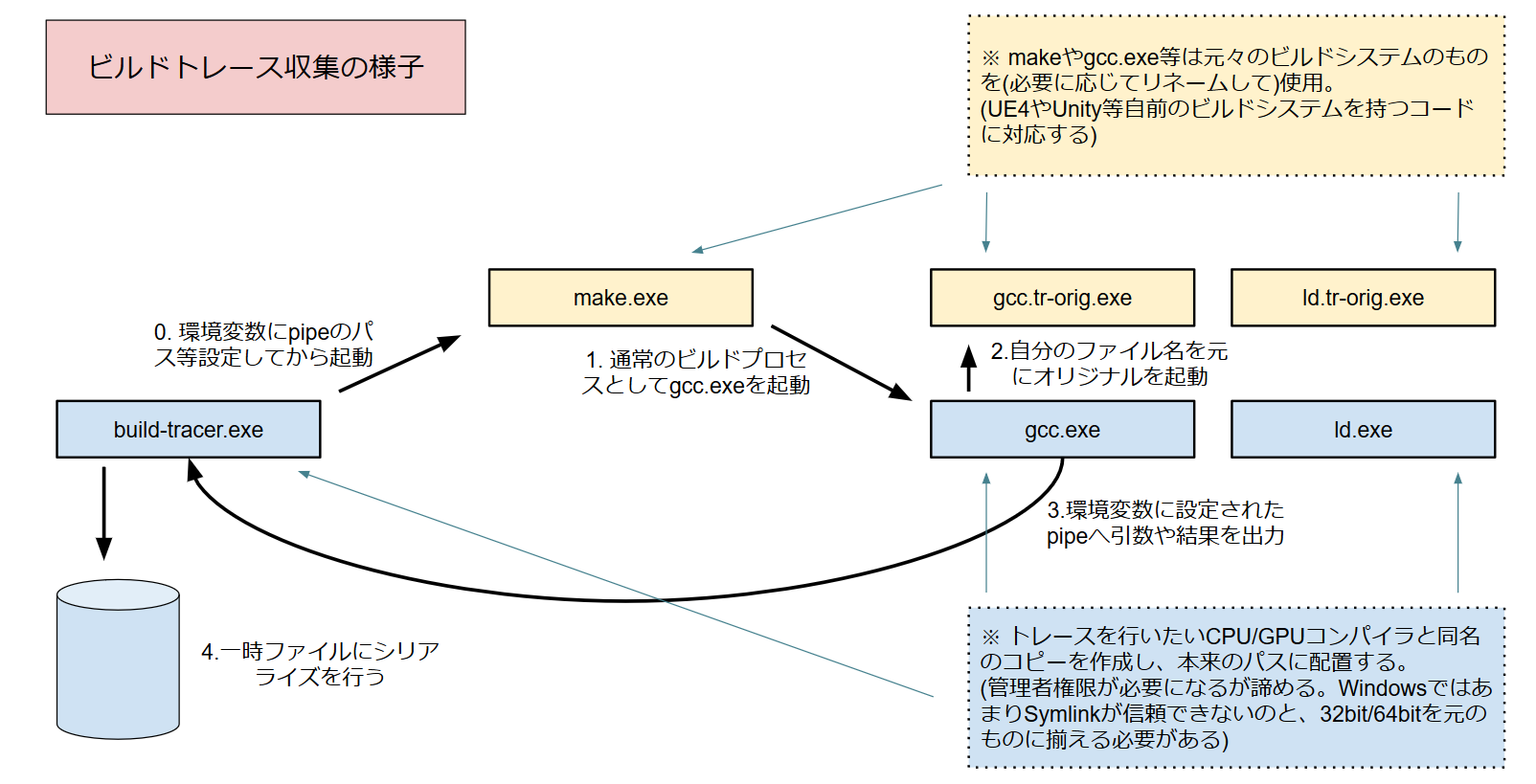
ポイントは"既存のビルドシステムを変更する必要が無い"点で、従来は専用のビルドツールを使用していたトレースの取得を、通常のビルド成果物の取得と同時に、そのままのビルドツールで実施できる点が重要と言える。
必要なものは、図中のbuild-tracer.exeやgcc.exe、ld.exeに相当する実行可能形式ファイル1つということになる(1つの実行可能ファイルをリネームして/binに配備する - ただしWindows環境ではABIを元のビルドシステムに合わせる必要があるためWin32とWin64の両者が必要)。
これに要求される機能はそれなりにあり、ネイティブコードで実装するのがちょっと面倒で今迄のプロトタイプではnmoshで書いたスクリプトを使っていた。しかし、これだとWin32/64のケースのように上手くいかない場合があるのと、nmosh自体が稀に起動失敗する症状が有り追うのが面倒なのでネイティブコード化を進めることにした。
必要な機能としては:
- 自分自身のファイル名を取得する機能。実はPOSIX的には自分の実行ファイル名を取得するための簡単な方法は無く、nmoshでは各OS毎に実装が存在する。https://github.com/okuoku/mosh/blob/c632378031e16fd3fa059087a30ba04055c54656/src/nmosh/win32/process.c#L1906
- 標準入出力とエラー出力をリダイレクトしつつ子プロセスを起動する機能。これはPOSIXであれば大抵の環境にpipeとposix_spawnが有り、Windowsでは専用の実装を用意することになる。POSIXではfdをdupして渡すといった処理を行わせる必要があるが、Win32では直接HANDLEの継承を使うという微妙な違いがある。このため、nmoshではリダイレクトとプロセス生成は一発で行うAPIとして用意していた。https://github.com/okuoku/mosh/blob/c632378031e16fd3fa059087a30ba04055c54656/src/nmosh/win32/process.c#L142
- 環境変数の取得と設定。これもPOSIXとWindowsの2実装で十分。https://github.com/okuoku/mosh/blob/c632378031e16fd3fa059087a30ba04055c54656/src/nmosh/win32/process.c#L1918
- カレントディレクトリの取得と設定。getcwd(2)やchdir(2)は地味にunistd.h上にあるため、Windows上では普通に実装することになる。https://msdn.microsoft.com/en-us/library/windows/desktop/aa364934.aspx
- 引数の解析とレスポンスファイルの回収。意外と自明でないが、Win32上ではシェルに渡せるコマンドライン長にかなり制約があり、レスポンスファイルを使用してプログラムが起動されるケースが有る。このレスポンスファイルはテンポラリディレクトリに作成されビルド後に消去される可能性が有るので、コマンドが終了するよりも前に回収しておく必要がある。悪いことに、レスポンスファイルはネストする可能性がある(手元のビルドでは発生していないように見えるが。。)。プロセスに渡されたコマンドライン文字列は、POSIXでは起動時に即回収する必要があるが、Win32ではGetCommandLine APIでいつでも取得できる。Win32の方が柔軟性のある比較的珍しい例。https://msdn.microsoft.com/en-us/library/windows/desktop/ms683156.aspx
- 名前付pipeの作成と接続。これもPOSIXとWindowsの2実装で十分。POSIXではselectなりpollを使って待合せすることになるが、Windowsには良い代替が無いので素直にIOCPを使うことになる。https://github.com/okuoku/mosh/blob/c632378031e16fd3fa059087a30ba04055c54656/src/nmosh/win32/process.c#L292
- timestampの取得。まぁamd64でしか使わないので普通にrdtscでも良いが。。高速なタイムスタンプとgettimeofdayの2通りが必要。今回タイムスタンプには"カルチャ"を持たせ、ログファイルのパース等を行う側で実時間に変換する方針とする。
さらに、結果をシリアライズしてpipeに流すためのシリアライザが必要になる。cmp( https://github.com/camgunz/cmp )とかmpack( https://github.com/ludocode/mpack )のようなMessagePack実装を持ってきても良いかなと思ったけど、この手のツールはパブリックドメインにしておかないと後々面倒なので独自フォーマットを自作することにした。MessagePackなりJSONなりが必要な場合は、ログをさらに処理して取得することになる。