MIT/GNU SchemeでどうやってYuniFFIをサポートするか問題
- http://d.hatena.ne.jp/mjt/20160318/p1
- prev: ネイティブコードインターフェースの抽象化
せっかくyuniがGambitでも動いているので、同じR5RSであるMIT-SCHEMEにも移植したいのが人情。
が、MIT/GNU Schemeは他のyuniが動作する処理系とは違って、
- そもそもbytevectorが無い。MIT-Schemeでは文字列(string)をバイト単位で読み書きできるのでそれで代用できるが、R6RS/R7RSで要求されているような独立型はそのままでは実現できない。
- bytevector扱いしている文字列をFFI関数に渡す方法が無い。このため、一度malloc()したバッファにコピーする必要がある。
このため、MIT-Schemeのような処理系の存在を前提に、yuniFFIの互換性戦略を再考することにする:
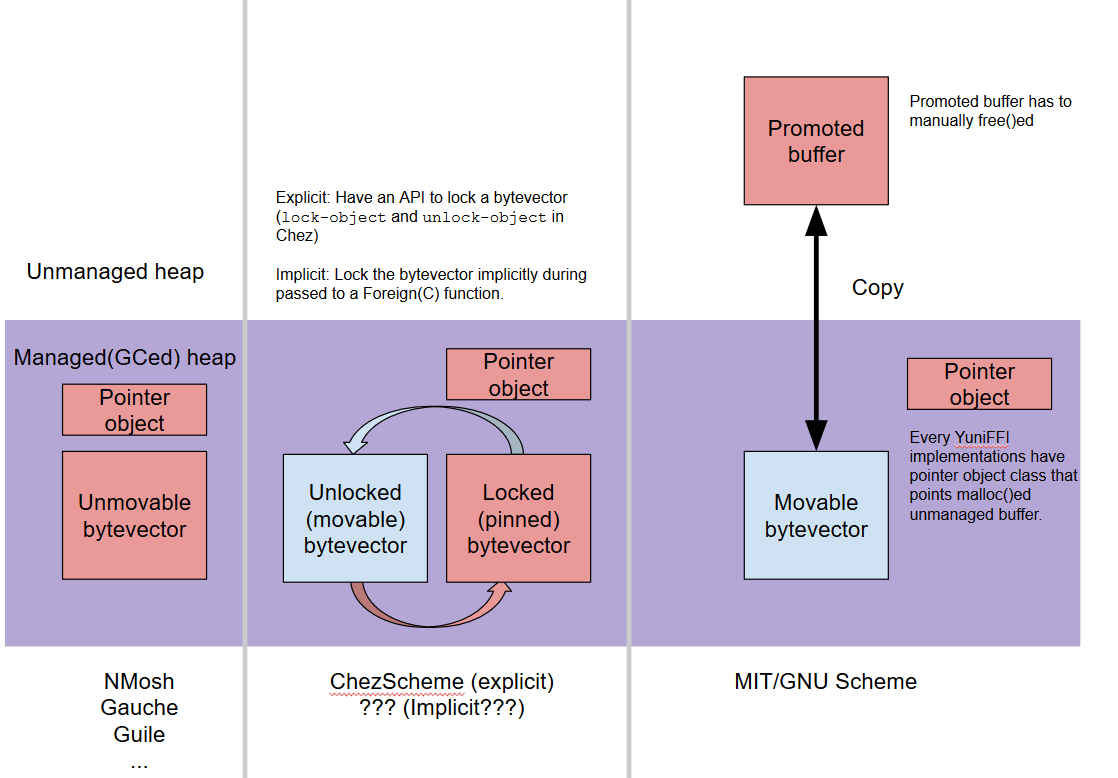
前回( http://d.hatena.ne.jp/mjt/20160318/p1 )、処理系のbytevector実装方針を2種類に分割したが、もうちょっとstraightforwardな分類を考えた。
- bytevectorが固定されていて移動しない処理系。BoehmGC系の実装はこれに当てはまることが多い。実際コピーGC等の方法で大きな領域を移動してしまうとキャッシュが勿体無いためこの実装方針には一理ある。
- 普段は移動する可能性があるがbytevectorを固定できる処理系。印象としては、正確なGCを備える処理系はここに分類されることが多い気がしている。
- bytevectorを固定する方法が存在しない処理系。そのような処理系では、FFI関数にbytevectorを渡す前には一旦コピーする必要がある。
既存のScheme処理系をこの3(4?)種類に分類する必要がある。最も移植性が高いのはMIT-Schemeのように毎回コピーを要求する処理系であると考えられるが、流石に実用的観点から言って手動GCを要求するような処理系は可能な限り減らしたいところ。。(一度promoteしたbytevectorをweakテーブルに入れ、"定期的に"参照されなくなったかどうかをチェックしてfree()する必要がある)
(... 実際のところ、LarcenyはImplicitな処理系と言えるが、"Schemeコードに制御を渡さなければGCは発生しないのでオブジェクトは移動せず、bytevectorを渡すときはcallbackするな"という実装なのでもっと別の考察が必要になる。つまり、Schemeコードをcallbackしないことが確実な呼び出しであれば後述のpromoteをpinに置き換えることができるため、最適化の余地がある。が、これをAPIでどう表現するか考えないといけない。)
バッファAPIと自動的なpromote/demote、pin/unpin
上記のような分類を考えた場合、FFI関数に渡すことのできる"バッファ"は以下の3種類存在することになる:
- bytevector
- ロックされたバッファ - アドレスが変化しないことが保証されているメモリ領域で、FFI関数に渡すことができる
- pointerオブジェクト - malloc()等unmanaged heap上に確保されたオブジェクトを指すためのオブジェクト
NMoshのように、この3つが完全かつローコストにinterchangebleな処理系も存在する(bytevector→pointerおよびpointer→bytevectorの両方が無条件に可能であり、かつ、bytevectorが"ロックされたバッファ"の要件を満たしている)が、通常はbytevectorとpointerで別々のAPIセットを使用してアクセスする必要がある。
yuniの場合、bytevector領域はR7RSのbytevector-u8-refといったAPIを使用し、pointerは手続き名が処理系毎に異なるため(yuni compat ffi primitive)ライブラリにptr-read/s8といった手続きを用意して処理系毎にwrapしている。
上の処理系分類によって、ある時点で"ロックされたバッファ"がbytevectorのAPIでアクセスできるのか、または、pointerのAPIでアクセスできるのかは異なる。例えば、MIT-SchemeではbytevectorをFFI関数に渡すためには一旦移動しないバッファにコピー(promoteと呼ぶ)する必要があり、コピー後はpointerのAPIでアクセスすることになる。Chez Schemeではこのコピーを避けることができ、オブジェクトが移動しないようにlock-objectを呼ぶだけで良い(pinと呼ぶ)。
このため、移植性のあるプログラムを書かせるにはbytevectorとpointerの違いを隠蔽した、一般的な、バッファにアクセスするための統一APIが必要となる。
この違いを隠蔽するのは主に効率のためと言える。Schemeの標準APIにはbytevectorしか存在しないため、既存のSchemeコードおよびライブラリとのやりとりはbytevectorに一度変換しなければならず、このとき、バッファがpointerで表現されている(= promoteされている)場合はbytevectorにコピー(demoteと呼ぶ)しなければならない。このため、bytevectorを仮定したコードを可能な限り書かせないことでバッファのpromote/demoteを本当に必要な場合に限って行うようにする。
... このバッファAPIの設計がyuniFFIのキモとも言える。
いずれにせよ、自動的にpromote/pinされたバッファはGCによって回収されなくなるため、自動的にdemote/unpinされなければならない。pin/unpinはローコストに行えることが期待されるため、FFI呼び出しの度にpin/unpinを行っても大きな問題にはなりづらいと考えられる。promote/demoteはオブジェクトの確保を伴うため必要最低限とする必要がある。
殆どのケースでは、一度promoteされたバッファはdemoteされない。プログラムが明示的にbytevectorへの変換を要求した場合にdemoteされる可能性があるが、殆どのケースではdemoteではなくコピーされなければならない(bytevectorに対する変更はpromoteされたバッファには一切反映されないため)。ただ、promoteされたバッファの回収処理にはO(N)のコストが掛かる - MIT-Schemeを含め処理系ではふつうオブジェクトに対するデストラクタを提供していない - ため、パフォーマンスのためには積極的にdemoteされる意味が有る。