syntax-rulesの中間表現を考える会
これすっげぇ難しい。。
中間表現の概要と必要性
自前のSchemeフロントエンドを実装する上ではsyntax-rulesの実装はどうしても避けて通れない。syntax-rulesは一応Scheme標準(R6RSとかR7RS)的には唯一のマクロ機構なので、これが無いとマクロが書けない。
今回は↓のような構成を考えてみた。
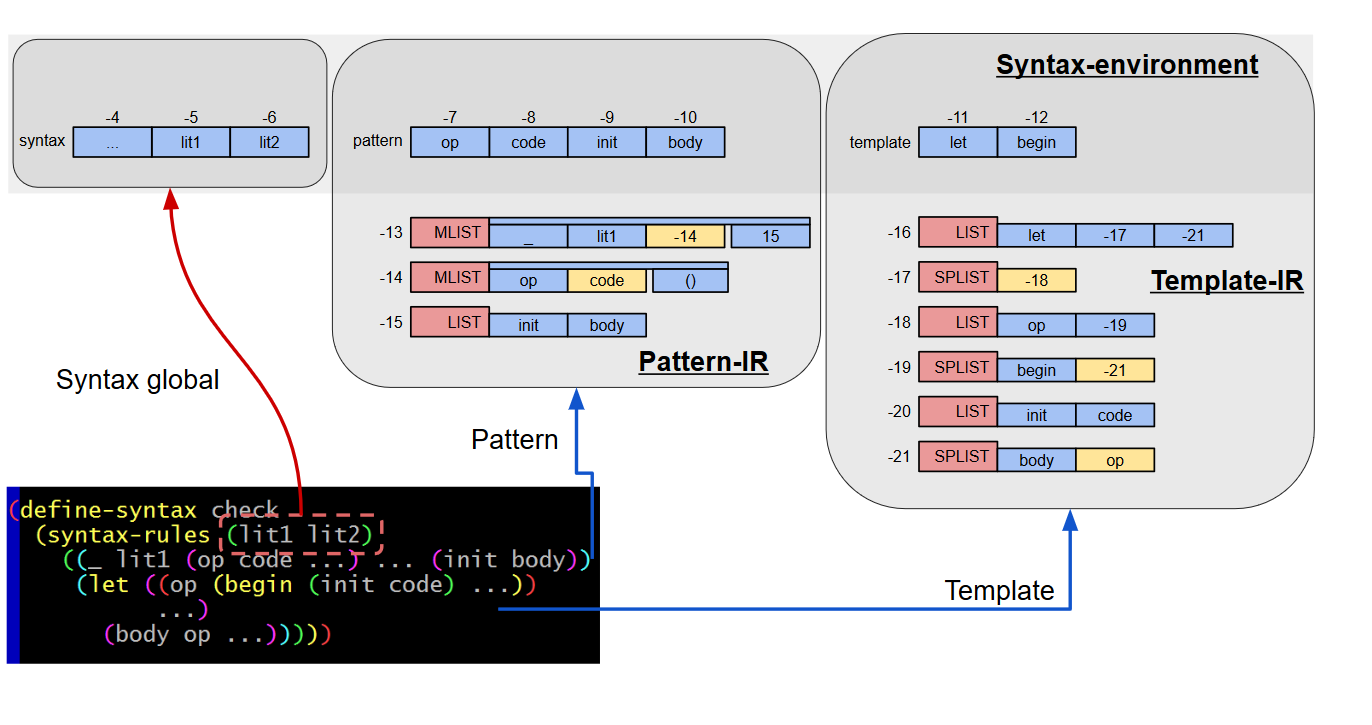
... ちょっとクールな図が思いつかなかったので非常に解りづらいが、1つのsyntax-rulesルールから、
- 環境(グローバル、{テンプレート、パターン}xN)
- パタン中間表現 xN
- テンプレート中間表現 xN
を生成する。環境には負値のインデックスを振り、vectorの参照一発でlookupできるように配慮する。(テンプレートやパタンに負の正確数が表われた場合はエスケープの必要がある。というわけで、-1や-2、正値はエスケープしなくても良いようにオフセットしている。)
そもそも以前見た( http://d.hatena.ne.jp/mjt/20150728/p1 )ように、その辺のsyntax-rules実装の大半は明示的な中間言語を持たず、syntax-rulesを直接古典的マクロに変換したり(NMosh)、ランタイムでパタンを解釈している。
設計目標としては:
- 可能な限りO(1)アルゴリズムを使う。普通だな!
- 可能な限りソースコードに表われないシンボルをinternしない。NMoshも含め、Scheme処理系によってはシンボルGCが存在しないこともあるので、マクロシステムは可能な限りシンボルをinternしないように配慮する方がメモリ効率に優れる。
- シリアライズ可能なオブジェクトのみを使用する = write可能なオブジェクトのみでIRを構成する = ハッシュテーブルを使わない。殆どのSchemeでハッシュテーブルはwrite可能でない。
というわけで、IRは全てvectorで表現する。
環境の構造
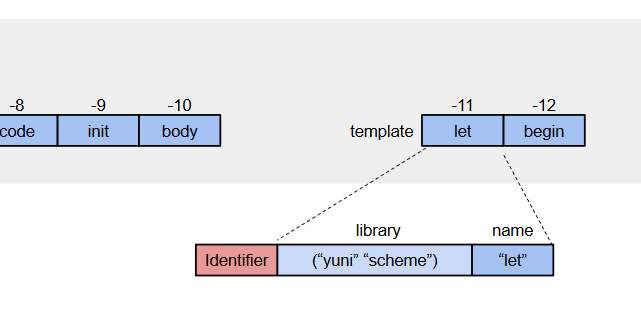
IRには当該syntax-rulesの環境が出力される。環境は普通のSchemeの環境フレームと同じようなものだが、
- index
- 種別 = Identifier | パタン変数 | 即値 | IR
- ライブラリ名 (Identifierのみ)
- ソースシンボル名
- body (IRのみ)
の組が1エントリとなる。更に、環境全体を1つのベクタで表現すれば、indexは先頭のオフセットだけ記録すれば良いことになる。
(実際にIRに記録されるものは、syntax-rulesの記述全体で有効な環境と、clause(パタン/テンプレートの組)のみで有効な環境の2つに分かれることになる。)
パタン / テンプレート要素表現
ここが未だできていない。
マクロを実際に使用した際に挿入されるコードの単位がパタン/テンプレート要素といえる。
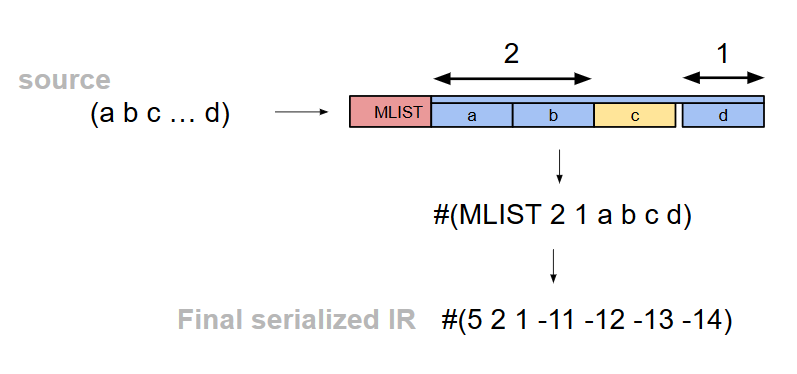
(※ 図では#(5 2 1 ...) となっているが、↓のようにMLISTは 4 を当てているので、正しくは#(4 2 1 ...)。)
IRの図で赤い箱になっているところがパタン/テンプレートの要素クラスを表わしていて、この要素クラスが結構な種類に及ぶ。たとえば、ここではクラスMLISTのパタン要素を表わしている。
MLISTは ... を含むリストで、
- ... より前の要素
- ... となっている要素(図では黄色)
- ... より後の要素
の3コンポーネントで表現される。このとき、vector3つでそれぞれの要素を表現するのではなく、要素の数を別途記録することでvectorを1つに抑えている。このようにしてvectorの数をケチることによって、ライブラリをロードした際のメモリ消費を抑えることができる。。。
実際には、今までの図に出てきていないようなクラスが当然存在する。
- パタン要素クラス
1 : (p0 . p1) => PAIR[ p0 : p1 ] 2 : (p0 p1 p2) => LIST[ p0 p1 p2 ] 3 : (p0 p1 p2 . p) => DLIST[ p0 p1 p2 : p ] 4 : (p0 p1 ... p2 p3) => MLIST[ p0 : p1 : p2 p3 ] 5 : (p0 p1 ... p2 p3 . p) => MDLIST[ p0 : p1 : p2 p3 : p ] 6 : #(p0 p1 p2) => VEC[ p0 p1 p2 ] 7 : #(p0 p1 ... p2 p3) => MVEC[ p0 : p1 : p2 p3 ]
MLISTはmeta listの略(適当に付けた)。DLISTはdotted listの略。DLISTの最終要素を空リストにすればLISTと等価になるけど、実際問題として殆どのsyntax-rulesマクロはDLISTを使わないのでクラスを分割してその分容量をケチっている。
- テンプレート要素クラス
1 : (a0 . a1) => PAIR[ a0 : a1 ] 2 : (a0 a1) => LIST[ a0 a1 ] 3 : (a0 a1 . a2) => DLIST[ a0 a1 : a2 ] 4 : a0 ... => SPLICE[ a0 ] ;; Single element 5 : SPPAIR ;; (a0 . a1) ... 6 : SPLIST ;; (a0 a1) ... 7 : SPDLIST ;; (a0 a1 . a2) ... 8 : #(a0 a1) => VEC[ a0 a1 ] ;; Fixed length vector 9 : #(a0 a1 ... a2 a3) => MVEC[ a0 : a1 : a2 a3 ] ;; Variable length vector 10 : SPVEC ;; #(a0 a1) ... 11 : SPMVEC ;; #(a0 a1 ... a2 a3) ...
... テンプレート要素クラスは考え中。SPLICEは現在展開中のリストまたはベクタにspliceする形でコードを挿入する。パタンは1エントリ内に複数のellipsisを含むことは無いが、テンプレートの方では普通に ... を複数含むケースが存在できるため、専用の配慮が必要になる。たぶんMVECも独立させる必要は無いな。。
例えば、テンプレート
(a b ... c ...)
は、
%root = LIST[a %1 %2] %1 = SPLICE[b] %2 = SPLICE[c]