スタブDLLの作成 - NCCCとは
- 前回: http://d.hatena.ne.jp/mjt/20150601/p1 - 定数テーブル
既にGithubには定数スタブのコード生成を完成させてコミットしているが、それについて書くのはDLLの準備が整ったタイミングに延期してcall stubの生成に話を進める。
以前( http://d.hatena.ne.jp/mjt/20150523/p1 )書いたように、yuniFFIで使用するグルーコードは定数(constant table)とコールスタブ(call stubs)で構成される。定数は、型のsizeofとか構造体のメンバのoffsetof、APIで使用する定数を含み、これによりC APIと情報をやりとりするために使用するbytevectorを生成するのに十分な情報を含んでいる。
call stubは、C APIを一定の呼び出し規約で呼び出せるように、C APIをwrapする関数で構成される。ここで使用する"一定の呼び出し規約"をNCCCと呼ぶ。
NCCC(Normalized C Calling Convention)
yuniFFI最大の特徴はNCCCにある。NCCCは、Normalized C Calling Conventionの略で、どのような引数の組合せであっても、一定の呼び出し規約でC APIを呼び出し可能にすることを目的としている。
NCCCによるwrapを行うことで、全てのAPIの引数(シグネチャ)は
void some_api(uint64_t* in, int in_len, uint64_t* out, int out_len);
に統一される。つまり、C APIの呼び出しを通信に見立て、in のパケットを送りつけると out のパケットが返ってくるイメージと言える。
StubIR処理系によって生成されるcall stubは、
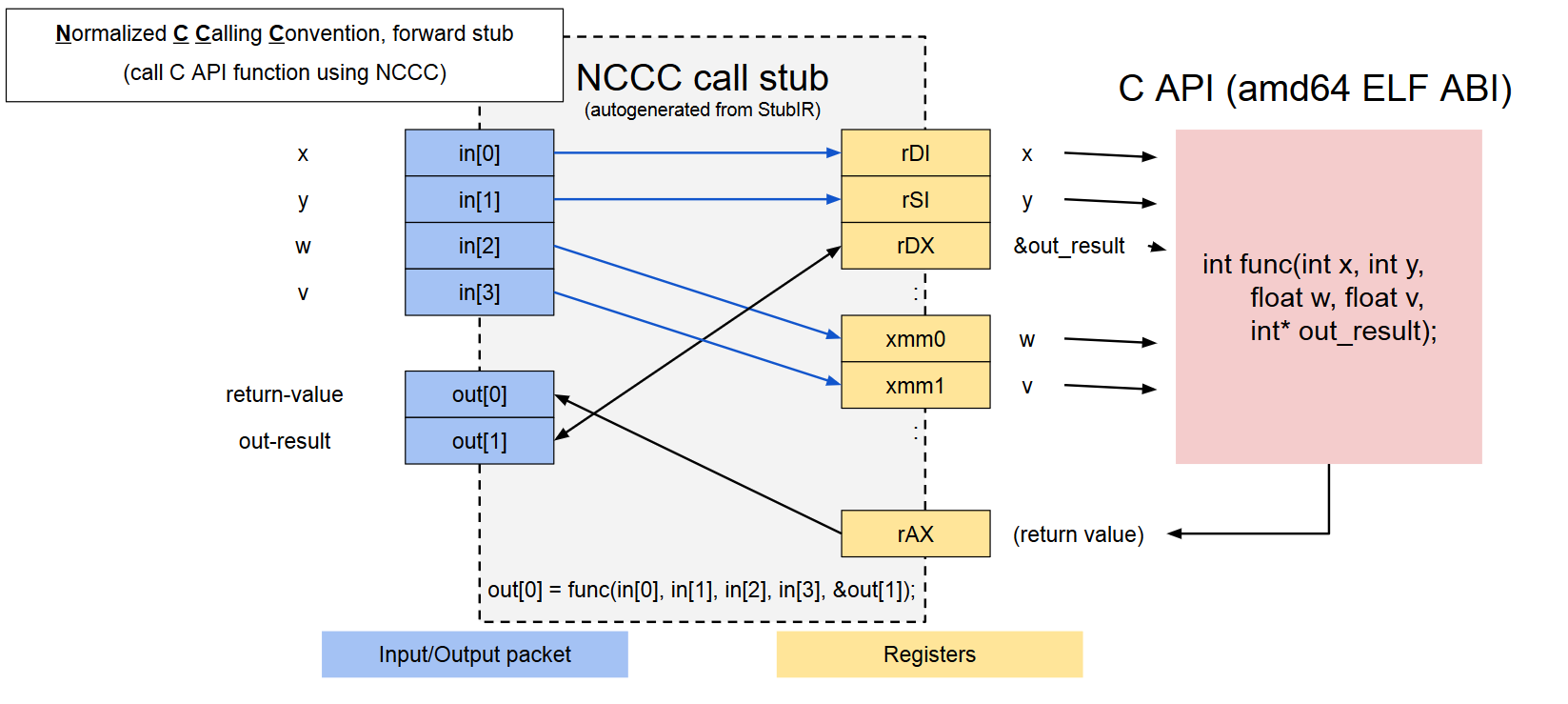
この図のように、bytevectorとして受け取ったin、outパケットからC呼び出し規約に沿ったレジスタへの詰め替えを行う。
NCCCのメリット
yuniFFIは最少の手間で各種処理系上に実装できることを目標としている。実際、Gauche( http://d.hatena.ne.jp/mjt/20150213/p1 )やchibi-scheme( http://d.hatena.ne.jp/mjt/20150316/p1 )のために書いた処理系固有のコードは非常に少い。
NCCCのメリット、つまり、APIの引数インターフェースを均一化することのメリットはいくつか考えられる:
- C言語レベルで実装できる。つまり、実装にABI知識を要求しない。このため、emscriptenのような現実的なABIを持たないC言語処理系にも(原理的には)対応することができる。
- これはWin32のように複数の呼び出し規約が併用されるようなシチュエーションで、特に問題を簡単にする。
- 処理系間でスタブDLLを共有できる。NCCCのwrap先は、やっぱりC言語APIであるため、C言語APIのバインディングが可能な言語であればyuniFFIのスタブDLLを使用することができる。
- 関数でなくてもwrapできる。いわゆる関数マクロでもwrapすることが可能であり、また、定数テーブルのエクスポート等実際のAPI呼び出し以外の雑用にもNCCCをインターフェースとして使用できる。このため、真に、処理系のyuniFFIサポートに要求されるのはNCCC関数の呼び出しだけになる。(実際には、callbackのサポートのために追加の考察が必要になる。)
- シグネチャが一定であるため呼び出しのチェインが可能となる。つまり、NCCC関数からホスト言語を介さず別のNCCC関数を呼び出すスタイルのAPIを作成することができる。例えば、API処理時間の計時や、errnoの読み出しとエラーコードの付与等。
- wrapperを定義から自動生成できる。NCCC wrapperはpure Cで実装でき、処理系固有のAPIが入る余地は無いため、StubIRの記述内容から自動的に生成させることができる。
NCCCのデメリット/デザインチョイス
NCCCは非常に非効率であるというわかりやすいデメリットがある。このため、パフォーマンスが重要な局面では採用できないかもしれない。
また、Gaucheやchibi-schemeと同様スタブDLLが必要であるため、任意のDLLをwrapするためには開発環境が必要になる。
デザインチョイスとしては:
- スタブDLLの内部で直接Schemeオブジェクト(シンボル、文字列やリスト)を生成することはできない。このポイントを最適化したとしても、どうせパケットの処理やファイルの読み書きでbytevectorとSchemeオブジェクトを相互変換するユースケースは残るため、メリットは限定的になると判断している。
- 現状は64bit wordなシステムに特化している。これは、doubleを正常に扱うためには64bit境界で揃える必要があることが多いため。この点は将来的には解消したい。
- libffiやnmoshのようなダイナミックバインディングは、APIがABIを規定していないケースでは使用できない。ダイナミックバインディングでは、API上ではシンボルしか規定されていなくてもその実際の値を何らかの方法で調べて記述する必要がある。
他のSchemeのFFI方式との比較
多くのScheme、例えば、Racket / nmosh / Vicare / ...はダイナミックバインディング方式を採用している。これはSchemeコード上でC APIのシグネチャを記述し、処理系側には各種呼び出し規約を実装して実現される。yuniFFIと同様Cコードの記述は不要。また、実行時のコンパイルも不要なため、ライブラリのDLLだけでスクリプトを記述できる。これはWindows/Macのようなコンパイラが普及していない状況では有利かもしれない。
Gaucheやchibi-schemeはC言語でのバインディングを要求している。処理系のC APIを使用することでSchemeオブジェクトを直接生成でき、最大のフレキシビリティを提供するが、処理系固有のAPIを学習する必要は有る。yuniFFI同様DLLのビルドが必要。
最近のnmoshはpseudo FFI( http://d.hatena.ne.jp/mjt/20130818/p1 )と呼ぶ仕組みによって、yuniFFIとダイナミックバインディングの中間解を提供している。src/call-stubs.inc.cには
typedef void (*func_pipp_v_t)(void*, int, void*, void*); void callstub_pipp_v(func_pipp_v_t func, uint64_t* args, void* ret){ func(*(void* *)(char *)&args[0], *(int *)(char *)&args[1], *(void* *)(char *)&args[2], *(void* *)(char *)&args[3]); }
のようなstub関数が大量に定義されている。pippはpointer int pointer pointerを引数に取り、vはvoid*を返すことを表わす。つまり、yuniFFIがNCCCスタブをAPI毎に生成するのに対し、pseudo FFIはシグネチャ毎にスタブを生成する。この方法はyuniFFI同様ABI知識を使用せずにFFIを実現することができるが、yuniFFIのようなフレキシビリティは提供しない。(= 事前生成したstubに存在しないシグネチャを持つAPIを呼び出すことはできない) - 実際にはpseudo FFIはyuniFFIの祖先に相当する。