ドキュメントワークフローを考える会
nmosh 0.2.8ではドキュメントを少くとも日本語のものは入れたいと思っている。というわけで、ドキュメンテーションのワークフローを考える。
APIリファレンスについては後回しにする。というのは、リファレンスは他のドキュメンテーションとは大きく内容が異なるため。
ドキュメントフレームワークとして採用するDITAは、ドキュメント内容を以下の4種類に分類している:
- コンセプトトピック : 要約を"〜とは"で始められるもの。1つの事項が何であるかについて説明するためのトピック。
- タスクトピック : 目的を達成するために必要なstepや前提条件、例を列挙したもの。
- リファレンストピック : APIリファレンス等、使用中に常に参照されることを期待したもの。
- 汎用トピック : 他3トピックのベースクラス。
APIリファレンスはそのままリファレンストピックに相当する。これは、実際のコーディングと密接にかかわってくるため多少異なるワークフローが要求されると考えている。
ツール
- documeme
nmoshのドキュメントのために、ドキュメントプロセサを作成することにした(documeme : どきゅみーむ)。基本的な執筆作業はHTMLエディタや普通のグラフィックスエディタで行うが、HTMLとDITAの変換と中間表現となるS式ベースフォーマットの管理はdocumemeで行う。
- HTMLエディタ
なんとこの手のツールはほぼ死滅しており難しいポイント。。まだ良さそうなエディタは見つけられていない。GoogleドキュメントはWord寄りでちょっと微妙に見えた。
- Google Translator Toolkit
(画像はSRFIを読み込んだところ)
Googleは対訳のためのWebツールであるGoogle Translator Toolkitを提供している。これを使用すると、Googleの機械翻訳を無料で使用できる(さらに翻訳業者まで仲介してくれるが)。
Googleドライブ連携が無かったりヘルプを見るとKnolの記述が残ったりしており、サポート回りには少々不安が有る。しかし、Webツールとしての品質はそれなりに高く、実用性という意味では申し分無い。
Google Translator Toolkitは、構築したTM(翻訳メモリ : 日英対訳データ)をダウンロードする機能が無い。このため、OmegaTで翻訳を構築する方が好ましいケースも考えられる。Java製。
逆に、Google Translator ToolkitはTMX(TMの交換形式)を読み取ることができるため、OmegaTで作成したTMを管理することができると期待している。
- DITA-OT
事実上のDITAリファレンス実装。これもJava製で、基盤部はXSLTで書かれている。CHMやWeb helpを生成することができる。
ワークフロー
翻訳を含めたワークフローはこのように想定している:
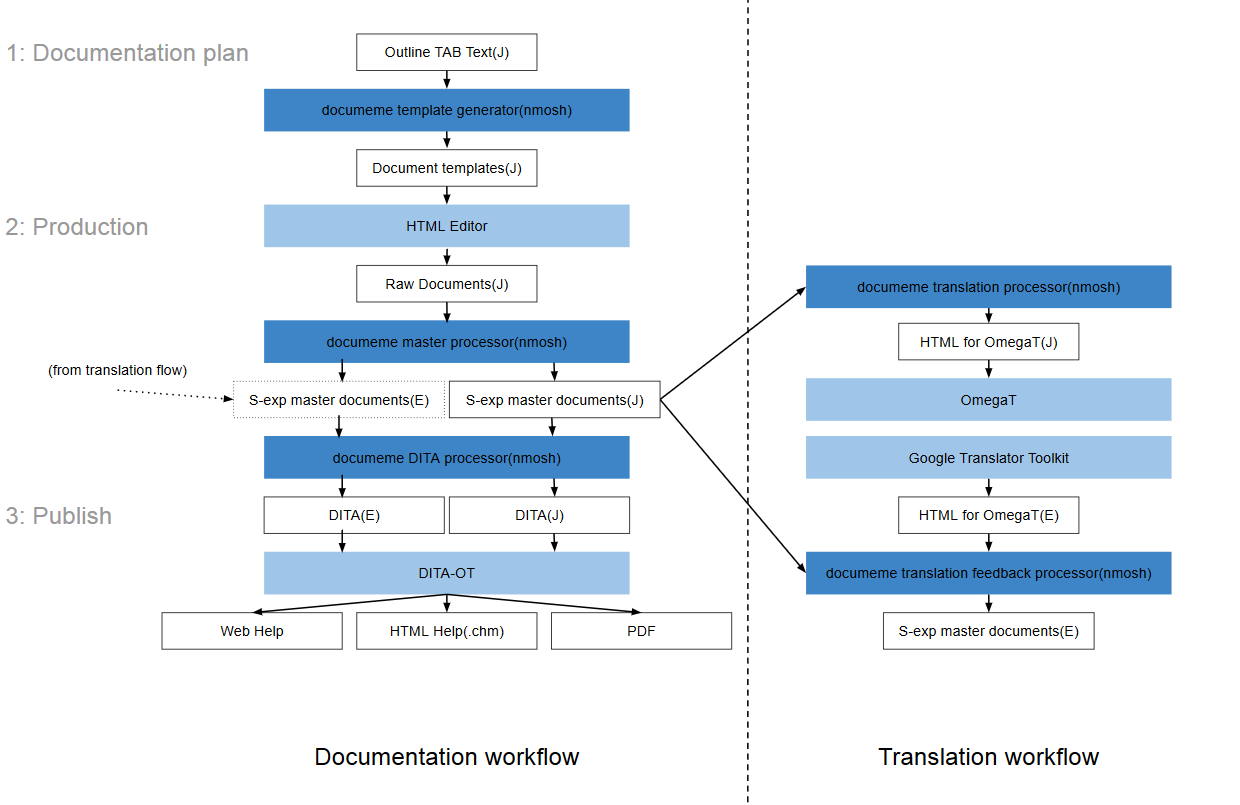
- 1. 計画フェーズ
最初に、ドキュメントの構成だけを先に全て決めてしまう。ここでは、スペースインデントでドキュメントの階層を表現する生テキストを使用する。ここで作成するテキストは、DITAのDITA mapに相当する。
nmoshユーザーズマニュアル [nug] ライセンス [license] インストール [install] Windows [windows] Linux [linux] FreeBSD [fbsd] ソースコード配布のインストール [src] 簡易REPL [C:basicrepl] (中略) Linux ターゲットガイド [linux] カーネル機能の使用 [syscalls] mmap [mmap] epoll [epoll] (後略)
ドキュメント構成を注意深く作成することで、無駄なドキュメントの発生を抑えることができる。ドキュメントの加除やマージの際も最初にドキュメント構成を修正する。
カッコ内はドキュメントHTMLのファイル名となる。ここで作成するテキストデータを元に、documemeはドキュメントのテンプレートとindex.htmlを生成することになる。コンセプトトピック等、DITAのドキュメントクラスを使用する場合は、 C: のようなコマンドを付与する。
- 2. 執筆フェーズ
documemeが生成したテンプレートを適当なHTMLエディタで変更し、ドキュメントを執筆する。ソースコード例や"注意"等、DITA的なコンテキストをドキュメント内に埋める場合は、CSSクラスを使用する。
OmegaTやGoogle Translator ToolkitはHTMLマークアップをちゃんと保持してくれるため、生テキストを翻訳するよりもHTMLを翻訳する方が好ましい。(この性質によりMarkdownやtexinfoの採用を諦めた)
- 3. 出版フェーズ
ここは人間の関与は必要無い。DITA XMLとDITA Mapを生成し、DITA-OTで処理するだけとなる。
用語集の収集
統一的なドキュメントを執筆するには用語集が欠かせない。
今のところSchemeの用語について訳はあまり定まっていないように見える。
- http://www.chino-js.com/ja/tech/srfi/ja-convention.html
- Scheme 翻訳規約
- http://practical-scheme.net/wiliki/wiliki.cgi?R6RS%3A%E7%BF%BB%E8%A8%B3%3A%E8%A8%B3%E8%AA%9E%E5%AF%BE%E7%85%A7%E8%A1%A8
- R6RS:翻訳:訳語対照表
- http://milkpot.sakura.ne.jp/scheme/r7rs.html
- R7RSの日本語訳その1
- https://github.com/oitomo/r7rs-small-spec-ja
- R7RSの日本語訳その2
- http://practical-scheme.net/gauche/man/gauche-refj.html
- Gaucheのリファレンスマニュアル
- http://sicp.iijlab.net/fulltext/
- SICPの日本語訳
例えば、上記の殆んどの翻訳やGaucheのドキュメントでは、最も基本的なSchemeのデータ構造である pair を"ペア"と訳しているが、(おそらく日本では最もSchemeの適用として引き合いに出される)SICPの日本語訳では"対"と訳している。これくらい基本的なところでも訳語は一定していない。