プリチャンはどこに向うか

桃山。
前回( http://d.hatena.ne.jp/mjt/20180401/p1 )の予想は新加入キャラが紫ってのしか当たってない!しかもクロスオーバーは初年度である今年からゲームの方で展開されている。VTuberはアイカツがやった( http://nlab.itmedia.co.jp/nl/articles/1806/07/news141.html )けどストーリーキャラクタではない。マイルームは"プリ☆チャン わちゃわちゃ会"としてコミュニケーションパートが実装されたがチーム構成がephemeralなのは変わっていない。宇宙はモチーフとしてアニメに登場しているが、さすがにもっと現実的な方面の切り方となった。
来年どうすんのかというのは非常に難しいところで、"キラっと"だけ替えるのかタイトル総替えか。。個人的には総替えすべきと思うけど。。
うまくいっていると思うところ
プロジェクト全体のコスト効率はかなり改善されたと感じる。
アーケード筐体はプリント筐体になっているが、このプリントはおそらく40〜50円/プレイのコストが掛かっていてこれを無くすことはできないので、どうしても開発や運用のコストを削ることでの利益確保になる。プリパラでは各キャラクタ毎に筐体オリジナル曲を制作していたが、プリチャンではこれを原則的に廃し、"歌ってみたシリーズ"としてインフルエンサー(乃木坂46)、LOVEマシーン(モーニング娘。)のカバーを制作している。...なぜこのラインナップになるのかはちょっと解らないが、アニメ楽曲がavex制作なのに、こちらはSMEの楽曲というあたりに事情を感じる。
コーデはブランド推しをやめて2チーム両方に同じものを着せ、更に限定カラーなどを駆使してバリエーションを出している。パーツや楽曲、モーションも含め相当量のアセットは前作プリパラからの再利用で構成されており、物量感を出すことにはある程度成功していると思う。
おもちゃ類はなんと1種に抑え、タカラトミー(!= アーツ)として出しているおもちゃ(カード/収納除く)はプリチャンキャストただ一種、しかも過去のシリーズとは異なりデジタルトイではない。筐体連動も印刷されたコードのみ。
運用面でも重篤な不具合(cf. http://nlab.itmedia.co.jp/nl/articles/1812/06/news115.html )を出すこともなく比較的おだやかに進行した印象。プリパラでは雑誌付録のコードがredeemできない等課金系の問題が見られたがシステム側の成熟があるのかもしれない。クラッシュ等のソフト品質はデータが無いので謎。
好みの問題
個人的にはプリチャンのデザイン方面は絵が若い感じというかなんというかフレッシュで良いと思っているけど、世間的にはあんまりそういう評価を聞かないので感覚がズレてるかもしれない。
アニメも当初見られた暴力的な傾向は鳴りを潜めていて日曜朝らしい良いアニメになっていると感じる。ただ、一貫した目的の無いドラえもんのようなアニメで良いのかというのは否定的意見が多い印象がある。
うまくいっていないと思うところ
着地点の無いコンテンツは売りようが無いのは前回ので散々書いたけど、それ以上にプロモーションが不味いんじゃないかという気がする。たとえば公式YouTubeチャンネルの登録者数は1万程度で、アイカツの公式チャンネルの1/10以下となっている。開設期間や視聴層(= 国籍など)の差は有るものの、予測されるプレイヤー数にここまで差は無い。公式の略称で"プリ☆チャン"(間に☆を入れるぶん検索性が低くTwitterのようなSNSでのトレンドになりづらい)を使うといった小さな問題から、そもそもIPホルダーの分散がそのままコミュニケーションの分散になってしまっているという大きな問題まで、さまざまな問題を解決していく必要がある。
コスト面の努力は感じるが、逆に言えば"そこまでしないと生き残れないのか"というのが正直な感想でもある。...まぁそれでもアイカツフレンズよりは贅沢を感じるし、オトカドールに至っては今年はアップデートが無いし。。
シリーズはどこに向うのか
まったく良いアイデアが無い。ハイターゲット(いわゆる大型女児)向けに営業を続けるのか、プリパラのようにもっと低年齢層に振るのかは決断が要るポイントだけど、正直リスクを取ってまで営業を拡大することを支持できるポイントが無い。
アニメキャラクタの商売はプリティーオールフレンズとして主に筐体外で展開している。逆にマイキャラの商売は(グッズ販売は設定されているものの)筐体内に閉じているので、展開のしようは有るかもしれない。プリチケメーカーのようなアプリは過去に展開していたので、同様にWebサイト等外部でマイキャラを作らせて誘引するなど。
マイキャラの音声は当初ボーカロイドを使うことが企画されていた( https://twitter.com/SHINOHBA/status/976571267942834176 )など、まだまだマイキャラのシステムには技術的制約で構想を実現できていないポイントが数多くあり、技術的なブレークスルーによって"ウリ"が産まれる可能性は大いにあると考えている。アニメキャラクタと同じプラットフォームで活躍するマイキャラの存在はコンテンツとの新たな関わり方になる可能性がある。
逆に言えば、これらの技術的なブレークスルーを取り入れていないうちは、新規のコンテンツが入り込むスキのあるニッチが存在すると言える。例えば変身前のマイキャラを含めた2世代キャラクタの実装には衣装のスケーラビリティを実現する必要があるが、そのためには衣装のあらたなオーサリング方法論が必要になる。
Anker Soundsync A3341
- https://www.ankerjapan.com/item/A3341.html
- 製品サイト
- https://k-tai.watch.impress.co.jp/docs/column/todays_goods/1139433.html
- ケータイWatchの製品レビュー
AptX sink機器が手元に無いので購入。Windows10以降は標準でAptX codecがシステムに搭載されているのでAptXで再生された(2回点滅)。
光デジタル入出力を備えていて、光デジタル機器を無線化する用途に使える。また、アナログ入出力も備えている -- 説明書には"AUX input"としか記載されていないライン入力端子は実は出力にも対応しており、ケータイWatchのレビューにも有るように適当なスピーカーを無線化する用途にも使うことができる。ただし、充電しながらの使用を推奨していないので設置用途に向かない。ヤマハYBA-11( https://jp.yamaha.com/products/audio_visual/accessories/yba-11/index.html )とかelecom LBT-AVWAR700( http://www2.elecom.co.jp/products/LBT-AVWAR700.html )みたいにBluetoothのデジタルレシーバって存在しないわけでは無いんだけど。。
説明書記載の点滅回数とCODECの対応は以下のようになっていて、
- 1 SBC
- 2 AptX
- 3 AptX LL(LowLatency)
- 4 AptX HD
- 6 AAC
なぜか5番が無い。
S/PDIF出力周波数はBluetooth側の入力と一致。手元の環境では44100Hzでの出力になる。バッテリ駆動の製品だけあって比較的真面目に出力制御を実装していて、PCのS/PDIF入力で聞くと曲間等でノイズが入る(出力が途切れる?ためと考えている)。例えばAUXに入出力デバイスを接続した場合はちゃんとS/PDIF出力は消灯する。
持ち歩きを想定したバッテリ搭載だけど、ちょっとその意義はわからず。入出力ともにマルチペアリングは2台まで、同時処理は1台のみなのでシェアリングには使えないし、公式サイトの画像だって明かに据え置きで使ってるし。。
AptX codecは既にAOSP( https://android.googlesource.com/platform/system/bt/+/3a3ec66a1bb7f5c99b17239021d6d184a3abd4ee%5E%21/ )やffmpegに入っている( https://patchwork.ffmpeg.org/patch/5879/ )。
オブジェクトベースオーディオのためのE-AC-3拡張の規格書を読む
Dolby AtmosのようなオブジェクトベースオーディオをSTBで動作するアプリから出力するにはE-AC-3くらいしか現状選択肢がない。E-AC-3(いわゆるDolby Digital Plus)上のJOC(Joint Object Coding)は一応AppleTVとAmazon FireTVの両方がサポートしている。
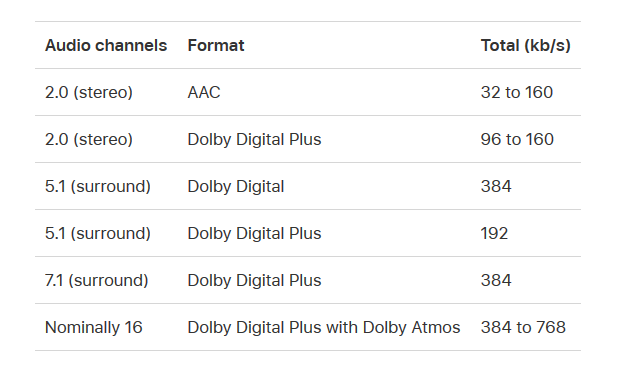
"Nominally 16"(16チャンネル相当)って微妙な表現だな。。
で、このDolby Digital Plus上のオブジェクトオーディオは一応標準化(ETSI TS 103 420)されていて、Dolbyのかなり簡潔なKBにURLが有る。
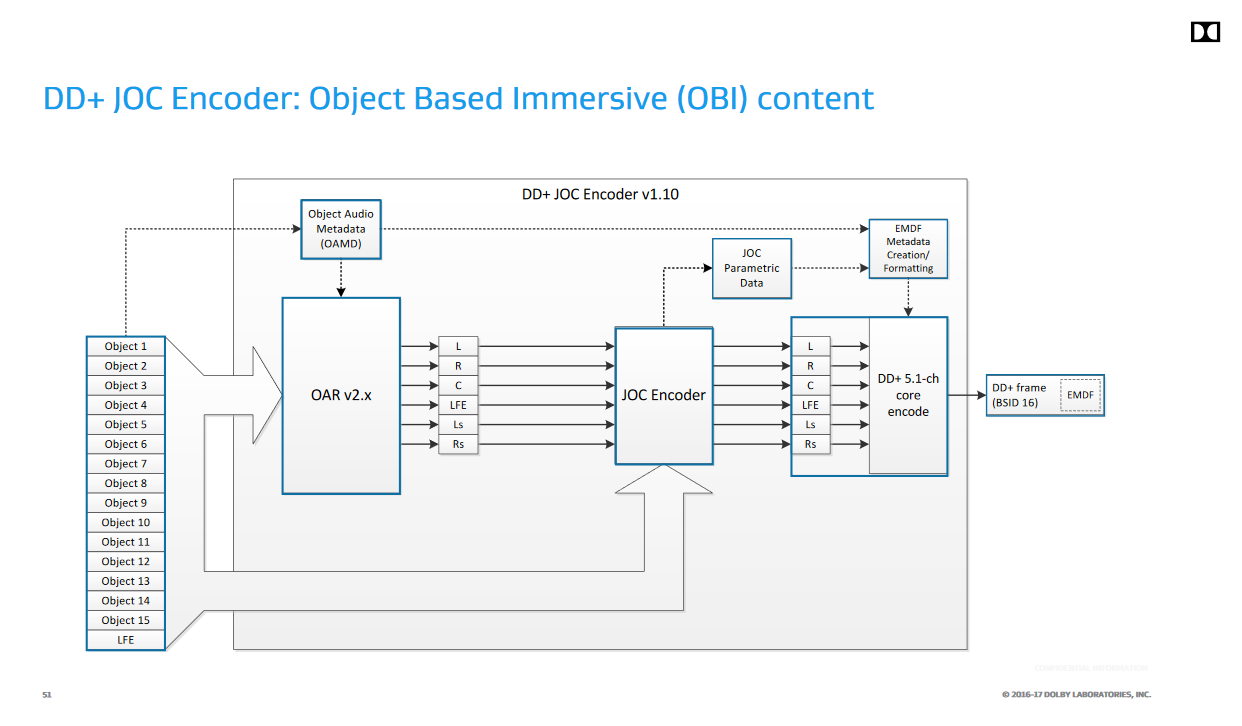
いきなりコレを読むよりも、AESでのDolbyの発表スライドにある図を見た方が良い気がする。
(エンコーダ)
(デコーダ)
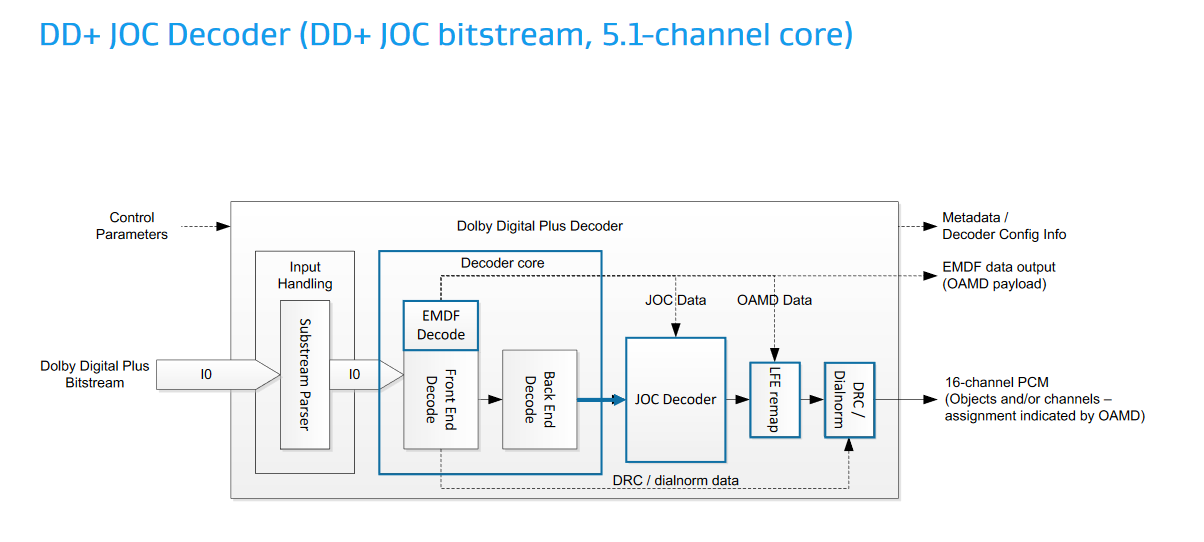
規格は図中の、OAMD(Object Audio MetaData)やJOCの仕様を規定している。この図では16 chを出力するように書かれているが、規格自体は最終的なスピーカーマッピング等は規定していないので、もっと多くのPCMチャンネルにデコードする実装も考えられる(一般家庭に16個以上スピーカーを置くのは非現実的だが、バーチャルサラウンドではずっと多くの仮想スピーカーを使用できる)。要するに元の5.1 / 7.1ストリームを16とかそれ以上の数のオブジェクトに"拡張"するのがJOCで、ETSI TS 103 420は16chのストリームを直接扱えるようにAC-3を拡張するわけではない。
オブジェクトのプロパティとしてはSizeがWidth、Height、Depthの3値を持つ直方体で規定されるのが目を引く。全てが0なら点音源、1なら無指向でリスニングルーム全体を占めるサイズの音源ということになる。
... これ直接Ambisonicsとかを伝送できるようにした方が良くない。。?何か特許を採用する必要があったとかでどうしてもJOCを採用しなければいけない事情が有ったのかもしれないけど。。JOCによって各オブジェクトの特徴量として出てくるのはQMFフィルタバンクの係数マトリクスなので、オーディオエンジンはオブジェクトの位置だけでなく各チャンネルへのダウンミックス係数やオブジェクトの元波形やミックス先から抽出した各サブバンド毎のゲインを保持しておく必要がある。そこまで複雑なデータを用意するなら、最初から7.1ミックスとヘッドホン用のミックスに絞った方がマシだな。
一応この規格ができたのが2016年で、そろそろFOSS実装が有っても良さそうなもんだけど、MediaInfo( https://mediaarea.net/en/MediaInfo )のライブラリ( https://github.com/MediaArea/MediaInfoLib )がフォーマット情報の表示に対応しているくらいで、デコーダやエンコーダは未だ無いようだ。
Intensity Pro 4K
Amazonでほぼ定価購入。
Blackmagic Design(BMD)は結局このIntensityのライン、要するに一般消費者向けのキャプチャ製品は最近出していないが、まぁアナログSD/HDソースや2Kソースであればコレで十分。。
いつものプリパラ。キャプチャによってできたTGAをPNGに変換している。
 ( http://storage.osdev.info/pub/idmjt/diaryimage/1810/neta181028l1.png )
( http://storage.osdev.info/pub/idmjt/diaryimage/1810/neta181028l1.png )
良いところ
もういくつHDMIキャプチャ買ってるんだという気になってくるけど:
- デジタルソースはDot-by-dot正確にキャプチャできる。前買ったAVT-C878は右端1ラインが欠けるのが超気になったけど、Intensityではちゃんと全画面キャプチャできる。
- SDKが有る。BMDのプロ用キャプチャ製品と同じDecklink Desktop Video SDKが使える。
- マルチチャンネルPCMをキャプチャできる。実は市場の製品でマルチチャンネルPCMをサポートしたキャプチャはあまり数が無く貴重と言える。。
とにかく決め手になったのはSDKが有るところで、逆に言うとあんまり通常の人間には薦めづらい。例えば、付属のキャプチャソフトは圧縮録画がMotion JPEGくらいしか選択肢が無く(Macであれば更にProResが使える)、チャンネル順も謎だったりする。
MotionJPEGで撮ったソースを元にYouTubeに上げてみた。
GStreamerを使用してコマンドラインでキャプチャする
GStreamerにはDecklinkのプラグインが既に存在するので、それを使うことでコマンドラインからキャプチャすることもできる。手元の環境ではアマレココ等では正常にキャプチャできなかったが、Decklinkを直接使うこれらのプラグインではまぁまぁの信頼性でキャプチャできる(が、たまに失敗するし10bit RGBには対応していない)。
適当なバージョンのGStreamerを導入し、以下のようなコマンドラインで再生できる:
gst-launch-1.0.exe -m decklinkvideosrc connection=hdmi mode=1080p60 video-format=8bit-bgra buffer-size=20 ! \
autovideosink \
decklinkaudiosrc connection=embedded ! audioconvert ! audioresample ! autoaudiosinkmodeやvideo-formatはキャプチャするソース毎に手で設定する必要がある。ココではNintendo Switchの設定なので60Hzで8bit-bgraとなっている。手元のWindows環境はWASAPI共有モードを192kHzで運用しているため、オーディオを再生するためにはaudioresampleエレメントを挟む必要があった。
また、どうもbuffer-sizeは20くらい無いと安定してキャプチャできないようだ。。単純に最初の方のフレームを脱落させれば良いと思うんだけど、やり方がわからず。
サラウンド音声のキャプチャ
... LPCMに関しては普通にできる。が、そもそもサラウンド音声をキャプチャしても公開するプラットフォームが無いのであんまり需要が無いのではないかという気はする。
手元の機器だと、他にHauppaugeのHD PVRがS/PDIF経由でDolby Digitalをキャプチャできたので、Dolby Digital Liveに一旦エンコードして録画するというクッソ面倒な方法で一応キャプチャできていた。Intensityの場合は普通にHDMIの8chオーディオを直接キャプチャできるため、そういう面倒が無いのは素晴しい。
PC以外だとなかなか難しい状況で、(HDCPを抜きにしても)AppleTVやFireTVのようなサラウンド対応STBはそもそも事実上Dolby Digital(と、同Plus)が唯一のサラウンド方法論になるため、その辺のコンシューマ機器でサラウンド音声を取れる物は実はゲーム機くらいしか無い。逆にゲーム機はXbox、Switch、PS4の全てがLPCM出力に対応していていづれもサラウンド音声をIntensityでキャプチャできる。
ビルドログ保持/分析ポリシのメモ
軽い気持ちで考えてたけどコレ意外と難しいぞ。。
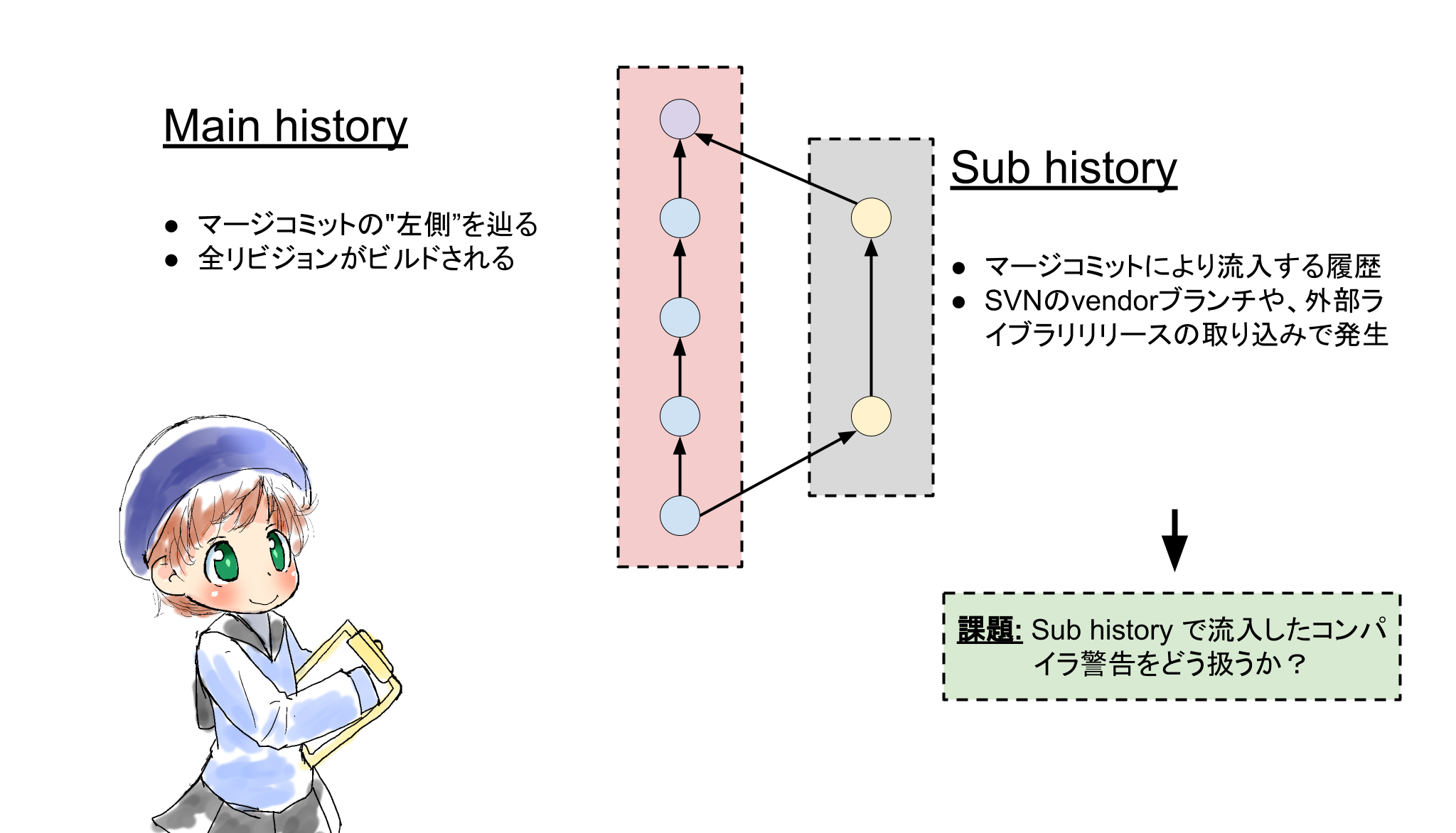
やりたいこと
しかし、現状の開発はGitでやっているので当然マージ等も発生し、"全リビジョンのビルド"自体が現実的にはできない。もっと悪いのはlibpngのような外部ライブラリをリポジトリにマージの形で抱えていることで、当然libpng等の変更をいちいちビルドしていたらいくらお金があっても足りないのでビルドの間引きはどうしても考える必要がある。
最新版のビルド警告だけを保持してblameだけで良い? → ダメ。警告の出現タイミング != ソース行の導入タイミング。ヘッダやプラットフォームSDK自体の非互換修正、ツールチェーンの更新等によって新たに警告が出現するのはよくあること。
履歴の分類(Main/Sub)による直線化ヒストリの定義
まず、マージによって導入される変更を細かく追うのは諦める。
Gitのようなバージョンコントロールシステムの履歴はDAGになるが、このうち"左側"の履歴だけをMain historyと呼び、そうでない履歴をSub historyと呼ぶことにする。Gitではマージの左右の概念が無いが、一般的には左がMainというかpublicにpushされていたリビジョンになることが多いように思う。残念ながらGitはrefにログが無いのでマージが有った場合履歴の左右どちらがメジャーなのかを決定するための情報が無い。(GitHubのNetwork graph https://github.com/ashinn/chibi-scheme/network はおそらくpush履歴を使用しているのではないだろうか。)
Sub historyはビルドログ自体を保持しない。このため、Sub history側で新規に増えたコンパイラ警告は、Main historyと交差するマージコミットにattributeされることになる。しかし、Sub history側のblameによって結果を近似できる可能性がある。
一方、Main historyは全リビジョンをビルドする。Main history、ようするにメイン開発者である自分のコミットは全リビジョンをビルドするのは現実的と言える -- そもそもCIしているので常に達成されている。Main historyは直線になるという重要な特徴がある。Gitはファイルヒストリを持たないためこのようにしてシミュレートしてやる必要があるが、SubversionのようなVCSでは、ancestryとしてこの概念を直接的に持っている(マージは後付けで付与された機能であり、本来のリポジトリフォーマットとしては、あるファイルには高々1つの祖先が常に存在する)。
この分類の導入によって、"Main historyはパーフェクト、Sub historyはblameによる近似"という目標に再設定できる。
取り組む課題
Main/Sub historyの概念の導入で問題が多少シンプルになった。次に取り組む課題としては、
blameメタデータをGitリポジトリに突っ込むフォーマットを考える。blameをO(1)またはそれに近いパフォーマンスにするためには、blameデータのキャッシュが必須になる。Gitはまぁまぁの品質のデルタ圧縮をコンテンツに対して行えるため、blameデータ自体もテキストデータにしてGitリポジトリにしておけば、容量を節約しつつデータベースとして機能させることができる。はず。
ホワイトスペースの扱い。コンパイラ警告の出現場所の特定という意味では、(Pythonのようなホワイトスペースが意味を持つ言語を除くと)ホワイトスペースの変更はblameに影響させないのが望ましい。しかし、ホワイトスペースの変更自体もそこまで頻繁に起こるものでもないので、ヒューリスティクスの失敗ということで無視してしまっても良いかもしれない。
Sub historyの漸近的な解決。バグを追うようなケースで、sub historyをビルドしたいようなケースも考えられる。その結果をblameデータリポジトリに投入するためにはどのようなフォーマットが考えられるだろうか?
revert処理のモデリング = 行編集モデルの拡張。Revertによって一旦削除された行を再導入した場合、警告の発生したリビジョンも実際に書かれたリビジョンに戻したい。このためには、現在 "新規"/ "削除" の2操作しか存在しない編集モデルに、"復帰"を導入する必要がある。おそらく、他ファイルへのコピーのような操作も拡張できるだろう。
nginxとLassoを使ってサイトをOpenID Connect(Auth0)で保護する
試験的にQiita版: https://qiita.com/okuoku/items/51e12289061ade156107
★ 注: Lasso自体はあんまりプロダクションに向いていない印象を受けた。全く同じことはoauth2_proxyでも可能で、oauth2_proxyのforkもいくつかあるので、そちらを検討する方が良い気がしている。
基本的にはサイト側でOpenID Connectのサポートをするのが望ましいが、nginxにはリクエストヘッダだけを一旦別のHTTPサーバに送信し、その結果によってアクセス可否を決める auth_request モジュールがあるため、HTTP認証サーバと適当なブラウザベースの認証機構を用意すれば任意のサイトを任意の認証フレームワークで保護することができる。
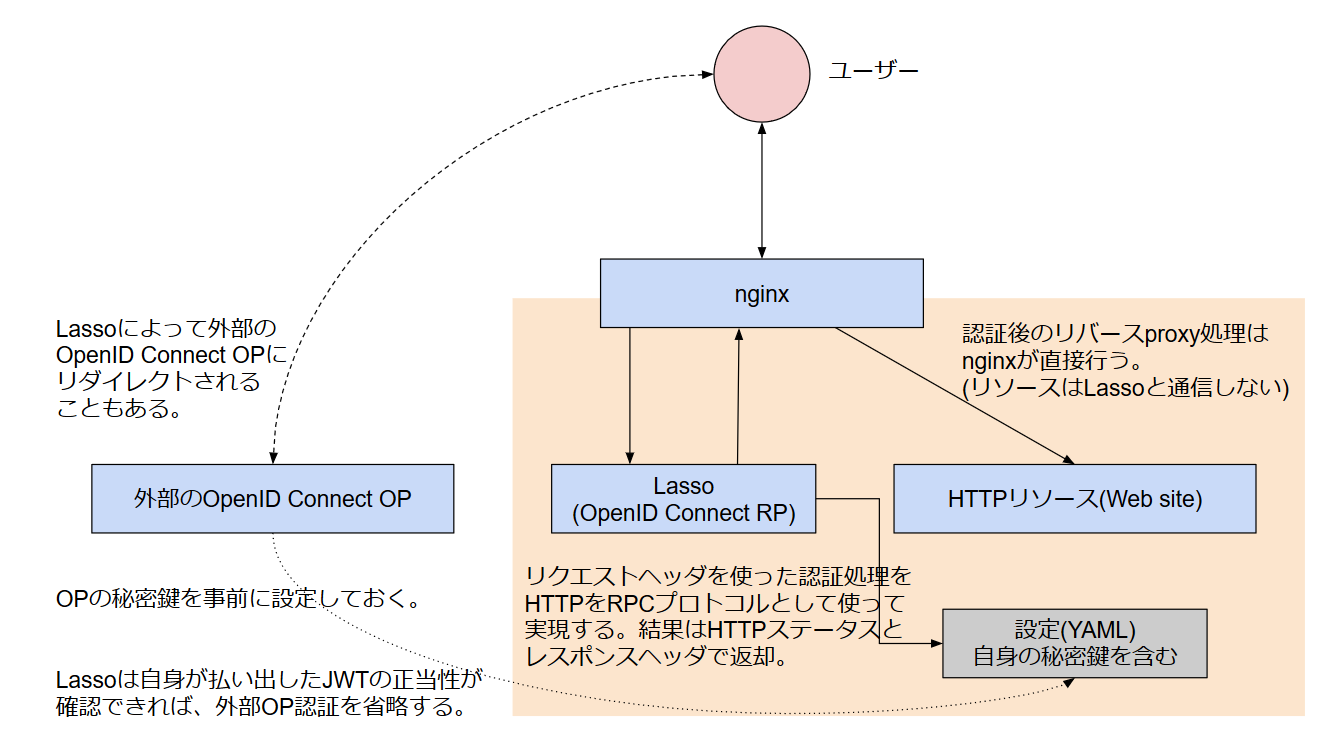
従来は oauth2_proxy というbit.ly製の認証プロクシがこの手のユースケースには(おもにk8s界隈で)よく使われていたが、oauth2_proxyはbit.ly側でのメンテナ不在により今月末でのプロジェクト終了が宣言( https://github.com/bitly/oauth2_proxy/issues/628#issuecomment-417121636 )されている。
認証プロクシは、バックエンドHTTPサーバへのリクエストも行う。それに対して、 auth_request による認証の移譲ではバックエンドサーバへのリクエストはnginxが行うことになる。このため、auth_requestで使う認証サーバはnginxの十分近くに配置する必要がある -- 認証プロキシに比べて、TCPなりなんなりの接続コストがそのままリクエスト遅延に上乗せされる。もっとも、認証プロキシでは事実上フロントエンド側のリバースプロキシによって2重のコンテンツバッファリングが発生してしまうので、どちらも一長一短な気はする。
- https://github.com/LassoProject/Lasso
- LassoのGitHubページ
- http://nginx.org/en/docs/http/ngx_http_auth_request_module.html
- nginxのauth_requestモジュールのドキュメント
- https://developer.okta.com/blog/2018/08/28/nginx-auth-request
- Oktaのブログ: Use nginx to Add Authentication to Any Application
今回の方法はメジャーなSSOベンダである Okta のブログに有るが、OktaでなくAuth0( https://auth0.com/ )を使ってみた。どちらも開発者向けには無料アカウントが有り、1000人までのユーザベースなら無料となっている。(Auth0は、更にFOSSと認められた場合は製品版も完全無料で使用できる -- TravisCIのようなfree-for-dev https://github.com/ripienaar/free-for-dev モデル)。
今回は、stripe.local/auth/* をLassoのための認証に使用し、stripe.local/testingというWebリソースの保護を考える。
nginxの設定
nginxの設定はほぼOktaのブログに掲載されている通りだが、リライトを使ってrootを移動している。
http {
server {
listen 443 ssl;
server_name stripe.local;
ssl_protocols TLSv1.2;
ssl_certificate f:/serv/keys/out.cer;
ssl_certificate_key f:/serv/keys/key.pem;
location /testing/ { ★ ここが保護したいリソース
auth_request /lasso-validate;
error_page 401 = @error401;
root f:/serv;
}
location @error401 { ★ Lassoから401エラーが帰ってきた場合のリダイレクト先
return 302 https://stripe.local/auth/login?url=https://$http_host$request_uri&lasso-failcount=$auth_resp_failcount&X-Lasso-Token=$auth_resp_jwt&error=$auth_resp_err;
}
location /auth { ★ ブラウザからLassoにアクセスできるようにする
rewrite /auth/(.*) /$1 break;
proxy_set_header Host login.stripe.local;
proxy_set_header X-Forwarded-Proto https;
proxy_pass http://127.0.0.1:9090;
}
location /lasso-validate { ★ 認証の移譲先
proxy_pass http://127.0.0.1:9090/validate;
proxy_pass_request_body off;
proxy_set_header Content-Length "";
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_set_header X-Forwarded-Port 443;
auth_request_set $auth_resp_jwt $upstream_http_x_lasso_jwt; ★ リダイレクト先指定で参照できる変数のセット
auth_request_set $auth_resp_err $upstream_http_x_lasso_err;
auth_request_set $auth_resp_failcount $upstream_http_x_lasso_failcount;
}nginx は常にユーザのリクエストヘッダをLassoに転送し、LassoはCookieの内容をチェックして認証済かどうかを確認する。認証済のCookieを持っていなかったら、Lassoは401を返してnginxに上で宣言したような @error401 を実行させ、結果的にユーザは302でLassoの /login に転送される。正当なCookieを持っていたら、Lassoは200を返し、nginxはそのままコンテンツの提供を継続する。
Lassoは保護されたリソースへのリクエストを全て検証することになるので、パフォーマンスに対する要求はそれなりに高いことになる。
ここでは認証したユーザ名の処理は特に実装していない。つまりOpenID Connect認証に成功したユーザは無条件でリソースへのアクセスが許可される。Oktaのブログの セクション Bonus: Who logged in?やLassoのREADME.mdに、HTTPヘッダを経由してユーザ名を渡す方法が有る。
Auth0の設定
Auth0では適当にテナントを作成した上で Regular Web Application を作成し、Allowed callback urlsをLassoの /auth を指すように設定する。今回の場合は、 https://stripe.local/auth/auth になる(本来は /auth だけだがrootを移動しているため)。

LassoにはOpenID Connectの自動設定(discovery)機能は無いので、LassoのYAMLには諸々の設定を手動で実施する必要がある。これらのデータはAdvanced settings >> Endpoints 以下にある。
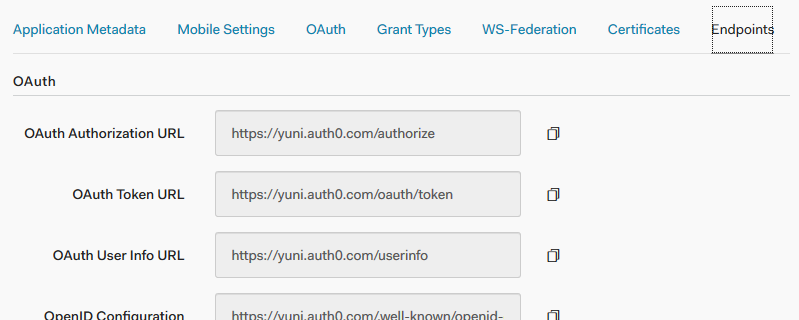
実際のユーザについては、Auth0の無料アカウントでは2種類までのソーシャルログインを有効化することができる。ソーシャルログインを使うと、ユーザの持っているGoogleとかTwitterのアカウント認証で認証を代替できる。ただし、複数のソーシャルアカウントを1つのAuth0上のユーザに結びつける機能は無料アカウントでは提供されない。(non-profitなFOSSについてはJIRA/Confluenceのように有料版をコストなしで提供している。)
Lassoの設定
Lassoの設定は、Lassoのexecutableがあるディレクトリ上の config/config.yml で行う。
lasso: logLevel: debug # ★ 機密情報もガンガン出るので注意 listen: 127.0.0.1 port: 9090 # !!!! FIXME !!!! allowAllUsers for now. # Lassoは元々Googleアカウント等への統合を想定しているため、ユーザ名中のドメインを追加で検証できるようになっている allowAllUsers: true publicAccess: false jwt: issuer: Lasso maxAge: 240 # 240分 = 4時間は再認証しない secret: lZlMPLfBjcIQCjbxjEoKep5dWn6xDjyW # これは乱数で良い compress: true cookie: name: Lasso-cookie secure: true domain: stripe.local httpOnly: true session: name: lasso-session headers: jwt: X-Lasso-Token querystring: access_token redirect: X-Lasso-Requested-URI db: file: data/lasso_bolt.db # data/ ディレクトリを事前に用意しておくこと oauth: provider: oidc # ★★ 以下のclient_idとclient_secretは本来開示してはいけない。 client_id: TfMpW26Hah9HI5sQw0WpVoCIhCS2V5qN client_secret: Q9eBFIKMRkhSGjjfrSxDITHDNgV2UwnMO4KqKR5jTBCqNbSNQBfRC50fZ5ozX1fc auth_url: https://yuni.auth0.com/authorize token_url: https://yuni.auth0.com/oauth/token user_info_url: https://yuni.auth0.com/userinfo scopes: - openid - email callback_url: https://stripe.local/auth/auth # Auth0に設定したCallback urlに一致すること
OpenID Connect OPのなかには、callback_urlとしてローカル端末を許可していないことがある。Auth0の場合は問題なく設定できるが、プロバイダ側で許可されていない場合はhostsを書くとか何らかの方法でワークアラウンドが必要になる。
YAMLにはいくつかの機密情報を設定する。client_idとclient_secretは認証を提供するOpenID OP(= Auth0)がRP(= ここで設定したLasso)の真正性を確認するのに必要となる(プロトコル上機密情報なのはclient_secretの方)。jwtのsecretはLassoが発行するJWTの認証鍵として使われる(これをランダムにしないと、別のLassoインスタンスが同様にJWTを発行できてしまう)。
OpenID Connectはユニバーサル認証手段になれるか?
というわけで、auth_requestを使うと任意のブラウザ認証手法をWebサイトに統合できることがわかった。もっとも、これがどの程度役に立つかは何とも言えない。
明確に役に立つのは、本来認証の無いWebサイト -- 例えば内部で作っているダッシュボードとか -- にそのまま認証を付加できるポイントだろう。ただ、他の認証手段(BASIC認証やアプリケーション組込の認証)に比べると:
- Deployが大変。通常の ID/パスワード認証であればBasic認証で良いし、LDAPを認証基盤としていて、かつOktaのようなOpenID Connectプロバイダを採用していないなら(あるいは自由にアプリケーションを追加できる環境でないなら)dex https://github.com/dexidp/dex とかKeyclockのようなOpenID Connect実装を別途用意しておく必要がある。
- アクセス権の扱いが微妙。グループ等のclaimを伝播させる良い方法が無い。有料版のnginxにはJWTのパース処理 http://nginx.org/en/docs/http/ngx_http_auth_jwt_module.html が存在するのでnginx内での処理も可能だが。。
- ユーザサービスを提供する余地が無い。そもそもアプリケーション側で明示的に対応しないと "ログアウト" みたいなリンクを置く場所が無い。
- 複数サービスの統合が難しそう。今回のセットアップでは、Lassoは / に認証クッキーを設定する。このため複数の異なる認証機構を単一ドメインでサービスするためには追加の考察が必要になる。
個人的には、HTTP経由のWindows統合認証が上手く動いた試しが無いので、ID/パスワードを前提とした実装よりは、OpenID Connectベースの認証に寄せた方がSSOや2FAの実装の上では有利な気はしている。...でも自作アプリの割合が多い現状を考えるとアプリ側に認証を用意した方がUI的には便利というか何というか。。
ssh port forwardingとstone経由でLet's encryptのワイルドカード証明書を作成する
Let's encryptではワイルドカード証明書を発行してもらうこともできるが、これにはDNS認証が必須となっている。
...このためだけに動的なDNSサーバを用意するのもちょっと面倒なので、グローバルIPv4アドレスを持つVPSにUDP port 53のパケットを転送させ、ローカルに立てたDNSサーバを使ってDNS認証を通してみた。
要するに、"静的なグローバルIPv4アドレスが割り当てられ、root権限を持っているsshでログインできてCコードをコンパイルできるホスト"と、"NSレコードをそのホストに向けられるドメイン"を持っていれば、PC上にDNSサーバを構築してそこにワンタイムパスワードを置くことで、Let's encryptのワイルドカード証明書を入手できる。
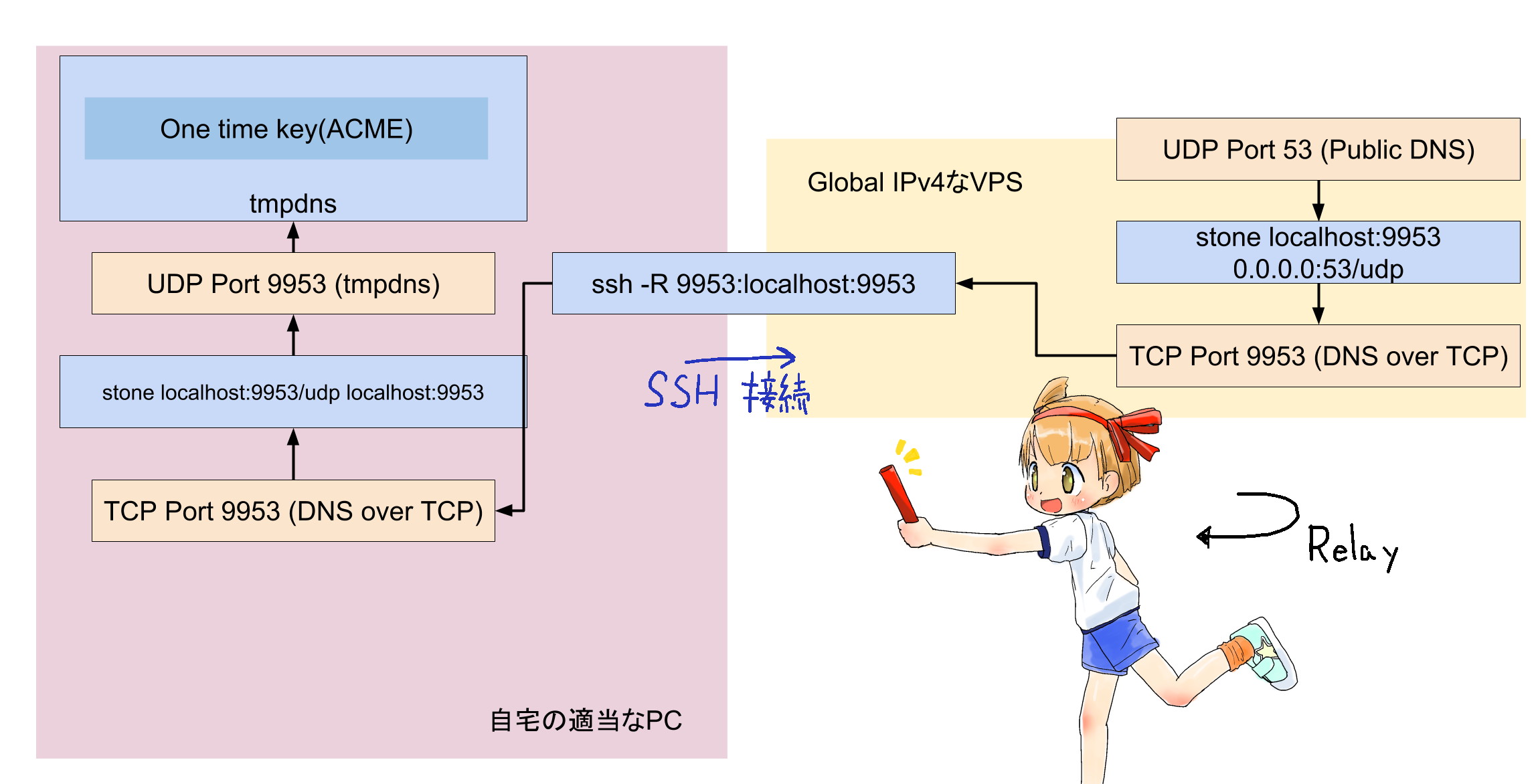
必要なソフトは、
- ssh - sshはTCP接続のフォワーディングができる。
- stone - http://www.gcd.org/sengoku/stone/Welcome.ja.html いわずと知れたトラフィック転送ツール。
- tmpdns - https://qiita.com/binzume/items/698d12779b8ad5cda423 go製のDNSコンテンツサーバ。コマンドラインから直接コンテンツを指定する。
の3つで、SSHとstoneを使ってポート転送をすることで、VPS側でgoのビルド環境を用意する必要が無いのがポイント。
NSレコード / DNSサーバの準備
Let's encryptのDNS認証は _acme-challenge.EXAMPLE.ORG のようなDNS名のTXTレコードを引き、そこにワンタイムパスワードを格納することによって行われる ( https://tools.ietf.org/html/draft-ietf-acme-acme-14#section-8.4 ) 。これは通常のDNS解決によってクエリされるため、他のサーバにコンテンツを移譲することができる。
先のページ https://qiita.com/binzume/items/698d12779b8ad5cda423 は、まさにこの点を使用していて、普段使用しているDNSコンテンツサーバとは別の適当なDNSサーバを静的なIPv4アドレス上に配備して、必要なワンタイムパスワードをLet's encrypt側に見せている。NSレコードの書き方もこのページにある。
ただ、今回はグローバルIPv4を持つサーバにはgoのビルド環境が無いため一工夫が必要になる。
SSHとstoneを使用してDNSクエリのproxyをする
goで書かれたDNSサーバをVPS上に持っていくにはVPS上にgoの開発環境が必要になる。これはちょっと面倒なので、DNSのパケットを手元のPCにproxyしてきて、PC上にDNSサーバを立てることで代えたい。ここでは、インターネット上のUDP port 53トラフィックを手元のPCのUDP port 9953に転送することを目指す。(直接53に転送しないのは、1024未満のポートにbindするにはroot権限が要るため。)
DNSプロトコルはUDP上に実装されているため、インターネットからやってきたUDPパケットを自宅のPCまで転送することができればproxyできたことになる。stoneにはUDP と TCPの相互変換機能が存在する( http://www.gcd.org/blog/2007/06/121/ )ため、これとSSHのTCP転送機能を組み合わせれば良い。
グローバルIPv4を持つホストでは "stone localhost:9953 0.0.0.0:53/udp" を実行して、0.0.0.0に対するポート53(DNS)のパケットをTCP localhost:9953 に転送させる。bindするポートが1024以下なのでsetuidなりなんなりしておく必要がある。
tmpdnsを動作させるPCではこの逆操作を行う: "stone localhost:9953/udp localhost:9953" を実行しておき、"ssh -R9953:localhost:9953" でグローバルIPv4を持つホストに接続し、stoneによってUDP→TCP変換されたDNSプロトコルを転送する。
あとは普通にacme.shなりなんなりを使ってDNS認証を進めることで証明書が入手できる。
手法の安全性
というわけで、自分のドメインのNSレコードを編集でき、グローバルIPv4アドレスを持つホストのUDPポート53にアクセスすることさえできれば、Let's encryptは証明書を発行してくれることはわかった。
... コレ安全なんだろうか。。?
Let's encryptが使用しているプロトコル(ACME)のIDでは、
o Always querying the DNS using a DNSSEC-validating resolver
(enhancing security for zones that are DNSSEC-enabled)
o Querying the DNS from multiple vantage points to address local
attackers
o Applying mitigations against DNS off-path attackers, e.g., adding
entropy to requests [I-D.vixie-dnsext-dns0x20] or only using TCP
...
It is RECOMMENDED that the server perform DNS queries and make HTTP
connections from various network perspectives, in order to make MitM
attacks harder.
...
Servers SHOULD perform DNS queries over TCP, which provides better
resistance to some forgery attacks than DNS over UDP.のようにいくつかの保護を考察しているが、今回のように実際のTXTレコードの取得はUDPパケット一発で完了してしまっている。もちろん、実際の証明書の発給は別の(TLS保護された)チャネルによって行われるので、攻撃を実施するにはこのTXTレコード応答を改竄しつつ、同時に証明書をリクエストする必要が有るなどそれなりのハードルは有る。
今回のやりかたが通用することでわかるように、少くともLet's encryptの実装ではACME手続きを実施するホストとDNS応答を行うホストは一致している必要がない -- そもそも現実的なシナリオでは両者に関係を求めずらい。
TCP onlyのDNSサーバで上手くいくのかは興味深いポイントだが、時間の都合で試せていない。
SSHポートフォワードとstoneで何でもできるのか
個人的には、この"グローバルIPv4アドレスを持った低機能なサーバにSSH接続してサービスする"形態はもっと色々な可能性があると思っていて、環境含めもっと追求していきたい。
ローカルのprivate環境をインターネットに公開するproxyシステムとしてpagekite( https://pagekite.net/ )のようなサービスがあるが、これをSSHのポートフォワードで実現するものとしてServeo( https://serveo.net/ )がある。pagekiteはサーバを公開するためには専用のクライアントが必要なのに対し、ServeoはSSHクライアントさえあれば良いためかなり手軽になっている。
...というか最初はこのstoneをつかったやり方を全く思いつかず、Azureを借りたり、Herokuやglitch(https://glitch.com/ - LinuxアプリのためにAWSインスタンスを無料で貸してくれるサービス)でできないか考えたり、VPNを張ったりしていた。。意外と"静的グローバルIPv4と簡単なアプリだけ"という構成のサーバは手軽なものが無く、例えばAzureだとContainer InstanceやAzure Functionsに静的IPが振れない等静的アドレスを要求にした途端にかなりハードルが上がってしまう。
日本の特殊な事情としてトラフィックが激烈に安いというポイントが有り、他所の国ではコンテナ化したサービスをアップロードして実行するものでも、日本ではサービスをローカルで実装し公開エンドポイントへのoutbound接続で済ませられる可能性がある。このトポロジの違いを、開発やデプロイの面で生かせないだろうか。
もっとも、SSHプロトコルは現実のワークロードに耐える程効率的でもないし、そもそも静的なグローバルIPv4アドレスの必要性自体が低下している。。Amazon LambdaやAzure Functionsに見られるように、アプリケーションロードバランサの下にAPIサービスを展開することで多くの機能を実現できるので、Webアプリケーションにとって自前のドメイン名や静的なIPアドレスが必要な局面はかなり小さくなっていると言える。今回ワイルドカード証明書を用意したのは、単にPWAのframeを自前のドメインで描画する必要があったためで、PWA本体はそのドメインから配信する必要性自体が無い。