BiwaSchemeで同期I/Oもしたい
ゲームの細かいデータハンドリングはSchemeで書いているので、Webアプリ側でも同じロジックを使いたい。というわけでBiwaSchemeにyuniを適当に移植した。で、適当に移植してみると、やっぱり普通のScheme処理系としても使えた方が便利...というわけでbytevectorや同期ファイルI/Oのような欠けている機能もyuniで使っているものは一通り実装した。
BiwaSchemeへのupstreamも意識して機能は基本的にJavaScript側に実装している。
非常に悩ましいのはJavaScriptは文字列がimmutableなため、R7RSで標準となっているmutable-stringsが実装できない点。専用の文字列ハンドルを導入して無理矢理実現するか、そもそも健全なプログラムはmutable-stringsを使うことは無いので実装しないかが悩みどころ。個人的にもmutable-stringsは殆ど使わない。
bytevectorはUint8Arrayで実装した( https://github.com/okuoku/biwasyuni/blob/5e93dc14f9901e0e20b90c56f4e037526f29b1d8/biwasyuni.js#L309 )。同期I/Oはどうせnode.jsでしか使わないのでBufferで良いような気もするが。。yuniではbytevectorのreadは必須でない(R6RSとR7RSで構文が違うので移植性が無い)ため、reader側はサポートを入れていない。
バイナリポートはget_bytes_at(bytevector指定箇所への読み取り)とget_bytes_all(内容全部の読み取り)を拡張している(https://github.com/okuoku/biwasyuni/blob/5e93dc14f9901e0e20b90c56f4e037526f29b1d8/biwasyuni.js#L137 )。openだけはyuniの側でScheme実装としている( https://github.com/okuoku/yuni/blob/7726eb4a0126c9585806160321f9e629e2a1ce2b/lib-runtime/biwascheme/prelib.scm#L12 )。これはbrowserfsがnode.jsと同じようなfsインターフェースをIndexedDBのようなブラウザ上のストレージに対して提供しているため、(current-port等と同じような感じで、)current-fsをオーバーライド可能にした方が良いかなという気がしていることに因る。
いくつかのBiwaScheme標準手続きはoverrideしている。例えばR6RSからR7RSで拡張されたstring-copy等の手続きはr6:string-copyにリネームしてyuniの標準ライブラリ側でR7RS版を実装した。また、yuniではloadは常にPauseを返し最終結果でresumeを呼ぶように修正している。
biwas.define_libfunc("load", 1, 1, function(ar){ // Override: (load fn) // NB: Override load because we may return a Pause on load'ed code. // FIXME: Parhaps it's same for scheme-eval... var pth = ar[0]; var src = fs.readFileSync(pth, "utf8"); // FIXME: Make this async. return new biwas.Pause(function(pause){ var interp2 = new biwas.Interpreter(interp, this.on_error); interp2.evaluate(src, pause.resume); }); });
標準のloadは手続きがPauseを返すことを想定していないため、loadしたスクリプトがPauseを返すと異常な挙動になってしまう。このようにすることで、browserfs等を使ってブラウザ上でもファイルのload等をローカルストレージから実施できるように拡張できる可能性がある。PauseオブジェクトはBiwaSchemeの便利な機能で、継続をwrapしたJavaScriptオブジェクトとしてPauseオブジェクトを生成でき、手続きから返すことでVMの実行を一時中断できる。これによりJavaScript界ではよくある、コールバック駆動の非同期処理を同期処理のように記述することができる。
Isomorphic プログラム環境として実は有望なのではないか
yuniにとって、BiwaSchemeはs7に続く2つめのGeneric runtime処理系となっている。というわけで、yuniのランタイムをロードした状態であれば、擬似的なSyntax-rules( http://d.hatena.ne.jp/mjt/20180521/p1 )やyuniのR6RS-liteライブラリ機構を使えるので、BiwaSchemeと他のScheme処理系で同じように動作するプログラムを容易に組むことができる。(まだFFIが無いので現状実用的でもないが)
Scheme環境の他所に無い特徴として、Gambitのような実用的かつ静的な最適化コンパイラの存在がある。ランタイムサイズを極限まで絞った環境と同じコードがJavaScriptやJavaでも動作するので、今までに無いIsomorphicアプリケーションが考えられるかもしれない。
各種オーディオエンジンの調査
ゲームで使うオーディオエンジンのポータビリティを高めるために、WebAudioのCバインディングを考えて、その移植レイヤを各種オーディオエンジンに対して実装するのが良いような気がしている。
...というよりは、固定機能で実現されることが多いOpenALのオーディオエフェクトと、BiquadFilterとかIIRFilterのようなフィルタプリミティブだけを提供するWebAudioではどうやってもセマンティクスが合わないので、どちらに合わせるかというのが単に問題になる。Emscriptenのように、WebAudioをOpenALでwrapし、OpenALを移植層として使う方が簡単かもしれないが、如何せんOpenAL自体があまりメジャー実装に恵まれていない。。
特に近年のVRの流行でオーディオエンジンもリバーブのbakeや、シーンのジオメトリ表現によるオーディオポータルの生成といった専用ゲームエンジンにあるような機能を提供しつつあり、これらを良く抽象化するAPIデザインはなかなか難しい。
LabSound
LabSoundはChromiumのWebAudio実装を抜き出してC++ライブラリにしたもので、機能性としてはWebAudioのものとほぼ同一になっている。グラフの構築はAudioContextを使用して行うためどちらかと言うと用法はOpenALに近い。拡張機能としてPureDataとリンクするためのPdNode等が追加されている。
ライセンスはBSD2で、当初はこれをwrapしてOpenAL実装にできないか検討していた。
Google Resonance Audio
- https://developers.google.com/resonance-audio/
- https://github.com/resonance-audio/resonance-audio - Ambisonics合成、FMOD / Wwise / Unreal / Unity / VSTほか向けのプラグイン
- https://github.com/resonance-audio/resonance-audio-web-sdk - JavaScript向けのSDK
- https://googlechrome.github.io/omnitone/ - JavaScriptで実装されたAmbisonicsデコーダ
GoogleのResonance AudioはWebやAndroidを含めた各種環境向けの空間オーディオSDKで、Ambisonicsを中心に据えたデザインになっている。OpenALではBlueRippleの実装が同様のデザインを持ち、OpenAL Softも近いAmbisonics合成パスを最近実装している。
リバーブに関してはVRでは一般的になったshoeboxモデル(直方体の部屋を仮定し、部屋のサイズと壁材質に合わせたリバーブを設定するモデル)を採用している。またオープンソースのライブラリでは多分初めてリバーブのbakeに対応しており( https://developers.google.com/resonance-audio/develop/unity/developer-guide )、Unityのゲームシーンにprobeを配置することでAPIのパラメタ設定を行わせることができる。残響パラメタは一般的なRT60を採用。
公開APIにはなっていないものの、各種フィルタやグラフAPIが有り、WebAudio同様のフィルタを備えている。
Windows Sonic
Windows Sonicは最近のWindows 10やXboxで使用できる空間オーディオAPIで、Dolby Atmosのトランスポートをサポートする等外部/ハードウェアレンダラをサポートしているのが特徴。ただしXboxでハードウェアレンダリングした場合16オブジェクトに制約され、ソフトウェアレンダリングの場合のAPI制約も128オブジェクト(含bedチャンネル)となっている。
8.1.4.4のようなチャンネルフォーマットをサポートする一方、Ambisonicsをサポートしていない。Barcoはチャンネルベースオーディオを推すホワイトペーパーを以前出していて( http://d.hatena.ne.jp/mjt/20140504/p1 )Dolby Atmosと対決姿勢を見せていた一方、Dolbyに支持されたこのAPIがAmbisonicsをサポートしていないのはちょっと気になる傾向と言える。
Ambisonicsの非サポートに見られるように、Windows SonicのAPIセット自体はAtmosのようなレンダリングシステムとのインターフェースに特化していて、フィルタやリバーブ等の機能性を持たない。何を組み合わせるべきなのかは調査中。
Steam Audio
- https://valvesoftware.github.io/steam-audio/ - APIリファレンスはCHM形式で提供されている
- https://github.com/ValveSoftware/steam-audio - FMOD等プラグインのソースコード
Steam Audio はValveに買収されたImpulsonicのオーディオSDKを無償化したもので環境のbakeやTrueAudioによる畳み込みオフロード等の高機能を誇る。特に無償のミドルウェアで直接的にTrueAudioをサポートしているのは珍しい気がする。Ambisonicの再生やHRTFレンダリングもサポートしているものの、フィルタやオシレータのような機能性は無く、どちらかというとOpenALに近い機能性と言える。
また、つい昨日リリースされたbeta14で、IntelのEmbreeレイトレーサ( http://embree.github.io/ )を使用したオーディオシミュレーションに対応している( https://steamcommunity.com/games/596420/announcements/detail/1674659226616741624 文中のphononはSteam Audioにおけるオーディオエンジンの名称)。
サイトはgithub.ioに有るもののオーディオエンジン部分のソースコードは公開されていない。バイナリはAndroid/Linux/OSX/Windows向けに提供。
Oculus Audio
- https://developer.oculus.com/audio/
- https://developer.oculus.com/documentation/audiosdk/latest/concepts/book-audio-reference/ - API リファレンス
ココで最初にとりあげた( http://d.hatena.ne.jp/mjt/20150308/p1 )際はネイティブAPIは公開されていなかったが、現在はC APIも公開されている。Ambisonicsの再生に対応しており、機能性は比較的普通。
同時発音数等をモニタするプロファイラ( https://developer.oculus.com/documentation/audiosdk/latest/concepts/audio-profiler-using/ )を提供している。Wwiseの統合ミドルウェアでは比較的よく見られる機能だが、単体のspatializerで提供されるのは比較的珍しい。
BiwaSchemeでWebアプリを書きたい
BiwaSchemeでyuniのライブラリシステムを導入する目処が立ったので、BiwaSchemeを使ってWebアプリのロジック部分を書けないか検討することにした。
BiwaSchemeには組込みのjqueryサポートが存在するが、今回は(個人的によく使っているので)mithril.jsベースのSPAを前提として考えることにする。
組込み
今回はビルドシステムとしてParcelを使うことにした。設定ファイルの類はほぼ不要(yarnで適当に依存を足すだけ)、エントリポイントのHTMLは至極シンプルで、
<!doctype html> <head lang="en"> <link rel="stylesheet" href="index.scss"> </head> <body> <script src="index.js"></script> </body>
だけになる。index.jsがJavaScript側のエントリポイントになり、ここでBiwaScheme等をロードしている。
var m = require('./node_modules/mithril'); var biwas = require('./node_modules/biwascheme'); var bfs = require('./node_modules/browserfs'); var root = document.body; m.render(root, "Hello."); // debug
Parcelのようなビルドシステムはコード内のrequire記述をパースし、依存関係を自動的に抽出する。
load相当処理の実装
Parcelで普通にビルドするとNode.js用のloadやdisplay実装が使われてしまうため、mithril.jsのXHR wrapperを使って適当にload相当の処理を実装する。
var errhook = function(e) { console.error(e); } var biwa = new biwas.Interpreter(errhook); m.request({ method: "GET", url: "/check.scm", deserialize: function(v){return v;}, }).then(function(str){ biwa.evaluate(str, function(res){m.render(root, res);}); });
ここでは、Schemeプログラム check.scm を / から読んでいる。Parcelのデフォルトでは dist ディレクトリがルートになるので、dist/check.scmにプログラムを置く必要がある。
js-invoke/async
BiwaSchemeは組込みでNode.jsのファイルシステムやjqueryのバインディングが付属してくるが、今回は他のアプリに合わせてBrowserfsやMithril.jsを採用するためそれらのバインディングを用意する必要がある。
基本的にはBiwaSchemeのドキュメントにあるようにJavaScript側でバインディングを書くことを想定しているように見えるが、コードの取り回しを考えるとJS側のコードを減らしScheme側の比重を高めたい。というわけで、コールバックを取る非同期APIのためのプリミティブとして js-invoke/async を用意してみた。
js-invoke/asyncは コールバックは引数の最後 を想定していて、非同期APIの呼び出し中はSchemeプログラムの実行をPauseし、コールバックが呼ばれるとSchemeコードの実行を再開する。js-invoke/asyncの返値はコールバックの引数そのものとなる。
// (js-invoke/async js-obj "method" args ...) biwas.define_libfunc("js-invoke/async", 2, null, function(ar){ var js_obj = ar.shift(); var func_name = ar.shift(); // FIXME: Require underscorejs for isString?? return new biwas.Pause(function(pause){ var cb = function(){return pause.resume(arguments);}; ar.push(cb); js_obj[func_name].apply(js_obj, ar); }); });
js-invoke/asyncを使ったSchemeコードは:
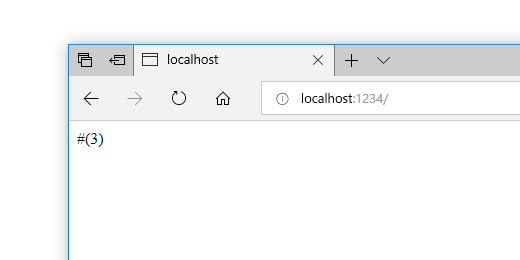
(define (object->string obj) (let ((p (open-output-string))) (write obj p) (get-output-string p))) (define the-result 0) (define x (js-closure (lambda (arg cb) (cb (+ arg 1))))) ;; myfuncの実体、引数1つとコールバックを受けとり1加算してcbに渡す (define theWindow (js-eval "window")) (js-set! theWindow "myfunc" x) ;; 適当にwindow.myfunc() を登録 (set! the-result (js-invoke/async theWindow "myfunc" 2)) ;; myfuncの呼び出し (myfunc 2 cb)、cbはScheme側を実行再開 (set! the-result (object->string (car (js-array->list the-result)))) the-result ;; 先のload相当処理で、返値がWebブラウザ上に表示される
このコードをdist/check.scmに配置すると、結果として"#(3)"が表示される(3 = 2 + 1)。(ベクタになっているのは、JavaScript側のコールバックが多値を返すケースを想定しているため。コールバックの引数が2つ以上であれば、その分長いベクタが返ることになる。)
... これで任意のJavaScript非同期APIを同期手続きのように呼び出せるが、そもそもJavaScript(〜ES5)には末尾再帰最適化が無いので、どこかで継続を打ち切るように書かないとスタックが伸びつづけてヤバい気はする。これはBiwaScheme側の実装をチェックしてみる必要が有りそう。
未解決問題
BiwaSchemeはNodeとブラウザの両方で load のようなAPIをサポートしているが、yarn経由で適当にビルドした場合BiwaScheme側のpackage.jsonに従ってNodeの方が使われているようだ。今回はmithril.jsを組込む都合、jqueryバインディングは不要だし何らかの形でコンフィギュレーションを切れると良い気がするが。。たぶんコレに関してはnpm的に直接的な解法はなくて、biwascheme-coreパッケージと同-node、-browserパッケージを用意して分割するしか無いと思う。
js-invoke/asyncのインターフェースは悩みどころで、もうちょっと抽象化したSchemeフレンドリなAPIの方が好ましいかもしれない。
まだyuniのビルドシステムとParcelを繋ぐ良い方法を思いついていない。たぶんParcelのプラグインとして書くのが良いと思うが、ParcelのCLIから使うためにはnpmパッケージとしてpublishしないとダメなんではなかろうか。。
Scheme雑記
なんか今週schemeトピック多くない?
今週のyuni/yunibase
処理系ブリッジフレームワークであるところのyuniではs7( https://ccrma.stanford.edu/software/snd/snd/s7.html )をサポートしてみた。yuniffi等もそのうち入れる予定。
yuniでサポートしている処理系は特に理由が無い限りyunibaseにも収録することにしているのでs7も収録したけど、急にMUSL libcでビルドできなくなり( https://github.com/okuoku/yunibase/issues/62 )この息の長い処理系がアクティブに開発されていることを示した。s7というかその上位プロジェクトのsndはコミットログがすごい https://github.com/spurious/snd-mirror/commits/master 。
yuniはR7RS処理系を基本に置いていて、R6RS処理系は互換層を挟んで対応している。その互換層の一部がR6RSのパッケージマネージャであるAkkuに収録された https://gitlab.com/akkuscm/akku-r7rs 。AkkuはR6RS処理系向けのパッケージマネージャだが、R7RSライブラリの取り込みをサポートするつもりのようだ。
yuniではs7の次はBiwaSchemeのサポートを目指しているけどBiwaSchemeのdefine-macroはレキシカルスコープされないのでlet-syntaxがサポートできず、どうしたもんか考え中。(既にBiwaSchemeにはsyntax-caseの開発ブランチが有るので、あんまりBiwaScheme側を改造する方向でのサポートはやりたくない。) まだライブラリのimportが動作していないが、yuniのテストで見つかった問題を直してPRした( https://github.com/biwascheme/biwascheme/pull/120 )。
唐突にSTklosがリリースされる
先週突然STklosがリリースされた。
STklosはGaucheのCLOS風オブジェクトシステムの始祖に相当する処理系で、名前が示唆する通りGUI開発の考察が有り、独自のパッケージシステムScmPkgを持つ。
...yuniは一応FFIがありアクティブに開発されているScheme処理系はみんなサポートするつもりなので隙を見てサポートしたい。。
唐突にmit-schemeのFFIが1.0になる
突然mit-schemeのFFIが1.0になった http://git.savannah.gnu.org/cgit/mit-scheme.git/commit/?id=c851b8c5100ad7a2b54c753728609fe7be5019ea 。
MIT/GNU Schemeは、それこそザ・Scheme処理系で、最近はbytevectorが実装され http://d.hatena.ne.jp/mjt/20170227/p1 、過去にあったFFIでバッファを表現できなかった問題 http://d.hatena.ne.jp/mjt/20160913/p1 などが解消している。
忙しくて開発を追い切れていないが、あとはsyntax-rulesがR7RS仕様になればyuniとしてはネイティブサポートと言っても良い状況ではないかと思う。(今はAlexpanderを使って事前にexpandしたプログラムを実行させる方式での対応としている。このような処理系はMIT-SchemeとGambitだけで、Gambitは今のs7サポート同様libraryをマクロとして定義する方式に代える予定。)
他にもChicken-r7rsがChicken 5向けのコミットをpushする等、歴史のある処理系の動きが目立った週になった気がする。
CMakeをSchemeにする -- S式のtokenize
意外な伏兵。。
CMakeはそれなりに高速なスクリプティング機能が有るため、やる気になればそれなりに実用的なScheme処理系にできるんじゃないかという気がしている。が、適当にやったらやっぱり遅かったのである程度は真面目にやる必要がありそうだ。
適当な実装
S式をtokenizeするには、適当な状態遷移マシンを用意して1文字づつ処理すればできる。 ...できるんだけど超遅い。以下、yuniの簡易テストコード https://github.com/okuoku/yuni/blob/cce309e917efbb7e0787e5bed7dd040996f9e452/_sanity.sps を読むのに掛かった時間で比較する。
素朴な実装はこういう感じになる: https://gist.github.com/okuoku/6a1a4ea859735cdc19779db3314bb63d
string(SUBSTRING "${${ctx}_buf}" ${${ctx}_cur} 1 __input) ... if(("${__input}" STREQUAL " ") OR ("${__input}" STREQUAL "\r") OR ("${__input}" STREQUAL "\n") OR ("${__input}" STREQUAL "\t") OR ("${__input}" STREQUAL "\"") OR ("${__input}" STREQUAL ";") OR ("${__input}" STREQUAL "(") OR ("${__input}" STREQUAL ")")
つまり、単に1文字をSUBSTRINGによって取り出し、それを文字列比較で比較していけば良い。(CMakeのSUBSTRINGはSchemeと違って第二引数として長さを取る。)
が、これが超遅い。
oku@stripe ~/repos/dryscheme-cmake $ time cmake -P check.cmake > /dev/null real 0m7.699s user 0m7.671s sys 0m0.015s
意外なことに、ORの部分を正規表現に置き換えると速度が向上する。
oku@stripe ~/repos/dryscheme-cmake $ time cmake -P check.cmake > /dev/null real 0m5.849s user 0m5.718s sys 0m0.031s
つまり、正規表現の破棄/生成コストよりも、ORの連鎖を処理するコストの方が高いと言える。高速なCMakeスクリプトを書きたければ行数を減らすしかない。
tokenを正規表現で引く実装
正規表現のコストが文字列比較並に安いのならば、正規表現を使った方が良いに決まっているので、正規表現でtokenを引く実装が考えられる: https://gist.github.com/okuoku/2beb787118d0cff574bdc817d4c547ac
elseif("${${ctx}_buf}" MATCHES "^(\\(|\\)|\\[\\]|'|`|#vu8|#u8|,@|,|#f|#t|#\;|#\\\\[a-z]+)(.*)")
CMakeはifコマンドに正規表現マッチ機能が有り、サブマッチを変数にバインドして直接アクセスできる。これを使用することで、tokenの抽出を行うことができ、tokenizer自体もまずまずコンパクトに書くことができる。速度の方もそれなりに改善して、
oku@stripe ~/repos/dryscheme-cmake $ time cmake -P check.cmake > /dev/null real 0m1.802s user 0m1.781s sys 0m0.015s
半分以下のコストで処理できるようになった。
...が、高々11KiB程度のコードを読むのに2秒掛かるのはちょっと。。
REGEXP MATCHALLで一気にトークンに分割する方法
たぶん文字列をちょっとづつ読むというのが構造的に重い(文字列の確保と解放を繰り返すことになる)。というわけで、処理を2パスに分割し、tokenはstring(REGEXP MATCHALL)を使用して一気にCMakeのリストに変換できるように考える。
REGEXP MATCHALLをコードに適用する前に、以下の変換を行う:
- ソース中のセミコロンをescapeする。CMakeのリストは単に文字列をセミコロンで区切ったものであるため、リストの内容にセミコロンを含めたいときは適当に処理する必要がある。個人的には、printableでない適当な文字に置き換える方法をよく採用している(手抜き)。
- 文字列中のdouble quoteを事前にエスケープする。
- SRFI-30 ネスト化コメント( https://srfi.schemers.org/srfi-30/srfi-30.html )を削除する。CMakeの正規表現にはlazy matchが無いため、ネストされたコメントにマッチさせることはできない(はず)。
- 通常のセミコロン行コメントを削除する。
このうち、後段のdouble quoteのエスケープ置き換えと、ネスト化コメントの削除は単一パスで実行できる。また、セミコロンやダブルクォートの変換が入ってしまうので文字定数は事前に処理する必要がある。
この前処理を実施することでトークンは単一の正規表現で表現でき、stringコマンドのREGEXP MATCHALLによってリストに変換することができる: https://gist.github.com/okuoku/7fd831c53b9bf7e970fad5bbb4301985
function(yuni_sexp_tokenize out str) yuni_sexp_tokenize_preprocess(prep fil) string(REGEX MATCHALL "\"[^\"]*\"|#vu8|#u8|#t|#f|#\\[a-z]*|#\\.|#|,@|,|[()`']|[^ \r\n\t()`']+|[ \r\n\t]+" lis "${prep}") set(${out} "${lis}" PARENT_SCOPE) endfunction()
これは上2つの1トークンづつマッチしていく手法よりも圧倒的に速い。
oku@stripe ~/repos/dryscheme-cmake $ time cmake -P check.cmake >/dev/null real 0m0.121s user 0m0.093s sys 0m0.015s
100ms程度ならまぁ許容できる速度だと思う。ただし、この方法だとトークンの行番号とか桁位置が取れないという問題がある。
define-macroのみ備える処理系のsyntax-rulesサポートは可能か?
追記: Redditの投稿 https://www.reddit.com/r/lisp_ja/comments/8kttfy で、Common Lispでの実装 http://www.ccs.neu.edu/home/dorai/mbe/mbe-lsp.html に言及がある。
追記: (最後の段はあんまり正しくない。 __ でgensymする場合、単一のsyntax-rulesテンプレート中に2回以上 __ が出現した場合は同じシンボルを出力するように出力をキャッシュする必要がある。こういう感じに: https://github.com/okuoku/yuni/blob/e03dc40e14389f9b1b63fd07fbb63ffbfe3fd228/lib-runtime/generic/synrules.scm#L40 )
yuniで提供されるライブラリの殆どはFFIを経由したCライブラリのwrapperになると考えられる。このため、ライブラリはマクロや補助構文をexportしないことが殆どになると言える。この要件の元でなら、define-macro(伝統的マクロ)しか備えない処理系でも自前のマクロ展開器を実装せずにR7RSライブラリやsyntax-rulesを実装できるのではないか。
(以前書いたように、マクロをエクスポートする場合は他のバインディングもグローバルにbindするという制約が必要になる http://d.hatena.ne.jp/mjt/20160825/p1 )
各種define-macro処理系
ここでのdefine-macroはScheme処理系にたまに見られるマクロ機構で、特定シンボルに"変換器"となる手続きをバインドし、ソースコードを実行前に変形することができる。
- http://www.iro.umontreal.ca/%7Egambit/doc/gambit.html#index-define_002dmacro http://www.iro.umontreal.ca/%7Egambit/doc/gambit.html#index-gensym
- Gambitのdefine-macro と gensym と uninterned-symbol?
- https://ccrma.stanford.edu/software/snd/snd/s7.html#macros
- s7のdefine-macro と gensym と gensym?
- http://www.biwascheme.org/doc/reference.html#macro
- BiwaSchemeのdefine-macro と gensym
- https://www-sop.inria.fr/indes/fp/Bigloo/doc/bigloo-25.html#Macro-expansion https://www-sop.inria.fr/indes/fp/Bigloo/doc/bigloo-7.html#g3445
- biglooのdefine-macro と gensym
- (MIT-GNU/Schemeはer-macro-transformerが使えるので実はこの考察は不要)
通常のシチュエーションでは、ランダムなシンボルを生成するgensym手続きとセットで提供される。Gambitやs7では、シンボルがgensymで生成されたものかどうかを判別することが可能だが、BiwaSchemeやbiglooではそうではない。
gensymが追加のオブジェクトを取れるかどうかにも微妙な差異がある。
define-macroでsyntax-rules(もどき)を実現するための制約
s7のように自由に環境クエリが可能なものを除くと、define-macroによる伝統的なマクロは、
- Scheme手続きによる式の変形
- gensymによる他と衝突しないシンボルの生成
のみが可能となっている。このため、syntax-rulesによるマクロが本来備えている"自動的な健全性"はどうやっても実現できない。なので何らかの現実的な制約を加えてどうにかdefine-macroでも実装可能なレベルに落としてやる必要が生じる。
... これがなかなか難しい。というか、制約として存在して困るケースが全然思いつかないので、何がダメになるのかが分からない。
define-macro処理系ではマクロの定義にdefineだけが使える。つまり、let-syntaxやletrec-syntaxに相当する構文が存在しないということになる。ただ、let-syntaxは通常のletとdefine-syntaxに開くことができるし(たぶん)、letrec-syntaxはそもそもdefine-syntaxでエミュレートできる(letrec*をdefineでエミュレートできるのと同じ)。
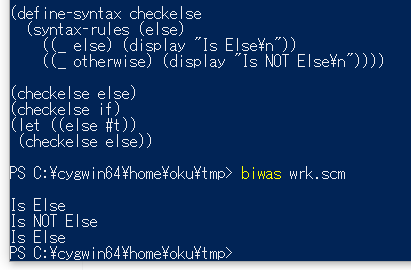
健全なマクロの例によく出てくる有名な例としては、"elseのような補助構文を別の意味にbindした場合に正常に動作しない"というケースだろう。でも個人的にはこれを真剣にやりたいケースに遭遇したことが無い(Cとかだと有るんだけど)。define-macroでsyntax-rulesを実現する上では、補助構文(syntax-rulesで与えたリテラル)は字面上での一致しか見ることができないため、補助構文をマスクするような記述はできないことになる。
(define-syntax checkelse (syntax-rules (else) ((_ else) (display "Is Else\n")) ((_ otherwise) (display "Is NOT Else\n")))) (checkelse else) ;; => "Is Else" が出力される (checkelse if) ;; => "Is NOT Else" が出力される (let ((else #t)) (checkelse else)) ;; => define-macroではこちらも "Is Else" になる。通常の処理系では "Is NOT Else"。
というわけで、健全性は一切気にしない方向でsyntax-rulesを実装してBiwaSchemeで実行させてみた。https://gist.github.com/okuoku/968caa7fa751beb029398a20838fbb24 今回は、chibi-schemeのexplicit renamingマクロで実装されたsyntax-rulesを適当にwrapしている。
(BiwaSchemeはnpmに収録されているので"npm install biwascheme -g"とすることでコマンドライン版biwasがインストールできる。)
要するに、syntax-rulesが単にテンプレートに従った式変形ツールになったとして、現実的な問題で困ることができるだろうか?他のポイントとしては、syntax-rulesのテンプレート内のシンボルはそのまま展開されるため、:
- マクロを定義した場所の環境 == マクロを使用した場所の環境 となっている必要がある。つまり、マクロを使用して変数をライブラリからimplicitに持ち出すことはできなくなる。...これは実はChickenのような通常のScheme処理系でもできないことが有るため、移植性という意味ではそこまで大きな問題では無い気がしている。
- "束縛されていないものに関してはマクロ展開のたびに異なる識別子が挿入される"要件を満たすことができない。R6RSで言うところの generate-temporaries https://practical-scheme.net/wiliki/wiliki.cgi?R6RS%3A%E7%BF%BB%E8%A8%B3%3AStandard%20Libraries%3A12.7%20Generating%20lists%20of%20temporaries が実装できないということになる。
逆に、generate-temporariesを専用の構文として分けてしまえば十分かもしれない。
例えば、R7RSの例として載っているletrec実装は、define-macroで書かれたsyntax-rulesでは正常に動作しない。
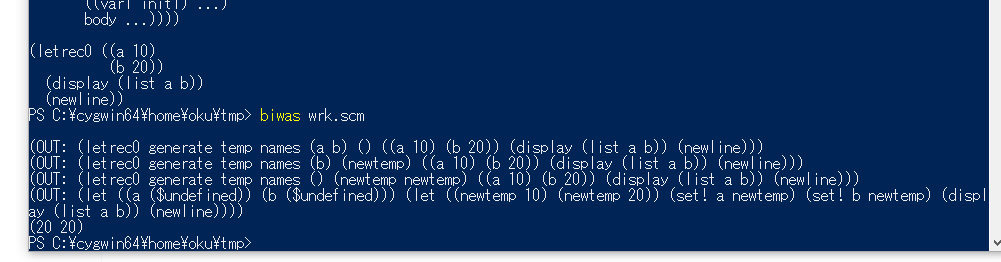 - (10 20)が正解
- (10 20)が正解
これは途中のダンプ結果に現われているように、変数"newtemp"が2回のsyntax-rules展開で被ってしまっているため出力結果が間違っている。本来syntax-rulesでは、マクロの展開結果が未知の識別子を挿入する場合は、その挿入した識別子は他のsyntax-rules展開で挿入されるものと絶対に被らないことを保証しなければならない。通常のdefine-macroでは、挿入しようとしている識別子が未知かどうかを知る手段が存在しないため、この制約を良く実装することができない。
もっとも頭の悪い解法は、適当なidentifier-macroを定義してそれをgensymの意味で使うことだろう。つまり、↑の実装でシンボルフィルタとして渡している baselib 手続を
(define (yuni/synrule-baselib sym) (case sym ((__) (yuni/gensym)) (else sym)))
のように、ある適当なシンボル(ここではアンダースコア2つ)をgensymの意味になるように設定し、
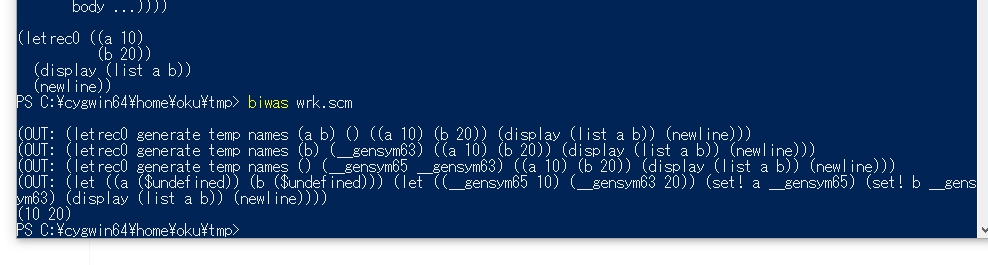
(letrec0 "generate temp names" (y ...) (__ temp ...) ((var1 init1) ...) body ...)
のように、新しい識別子が必要な場所で明示的に使うことで、マクロ手続き側で環境の知識を持っていなくても適切にgensymに誘導するようにできる。
これで、letrecも期待通り動作するようになった。
- https://gist.github.com/okuoku/673981856df0dfd5e9f5dfe44a223c9d 追記: この実装はあまり正しくない。記事先頭の追記参照。
正直ここまでして処理系のマクロ展開器を使いつづける意義ってのが有るのかどうか微妙な線になってきたが、とにかく今のところは受け入れ可能な制約でdefine-macro処理系にyuniを実装することができる気がしている。
ゲーム向けファイルシステムの設計の難しさ
ゲーム向けのファイルシステム抽象化は近年超クッソ激烈に複雑化しており、大分手を付けられない問題になってきた。
ゲーム配布/ストレージ様式の変化
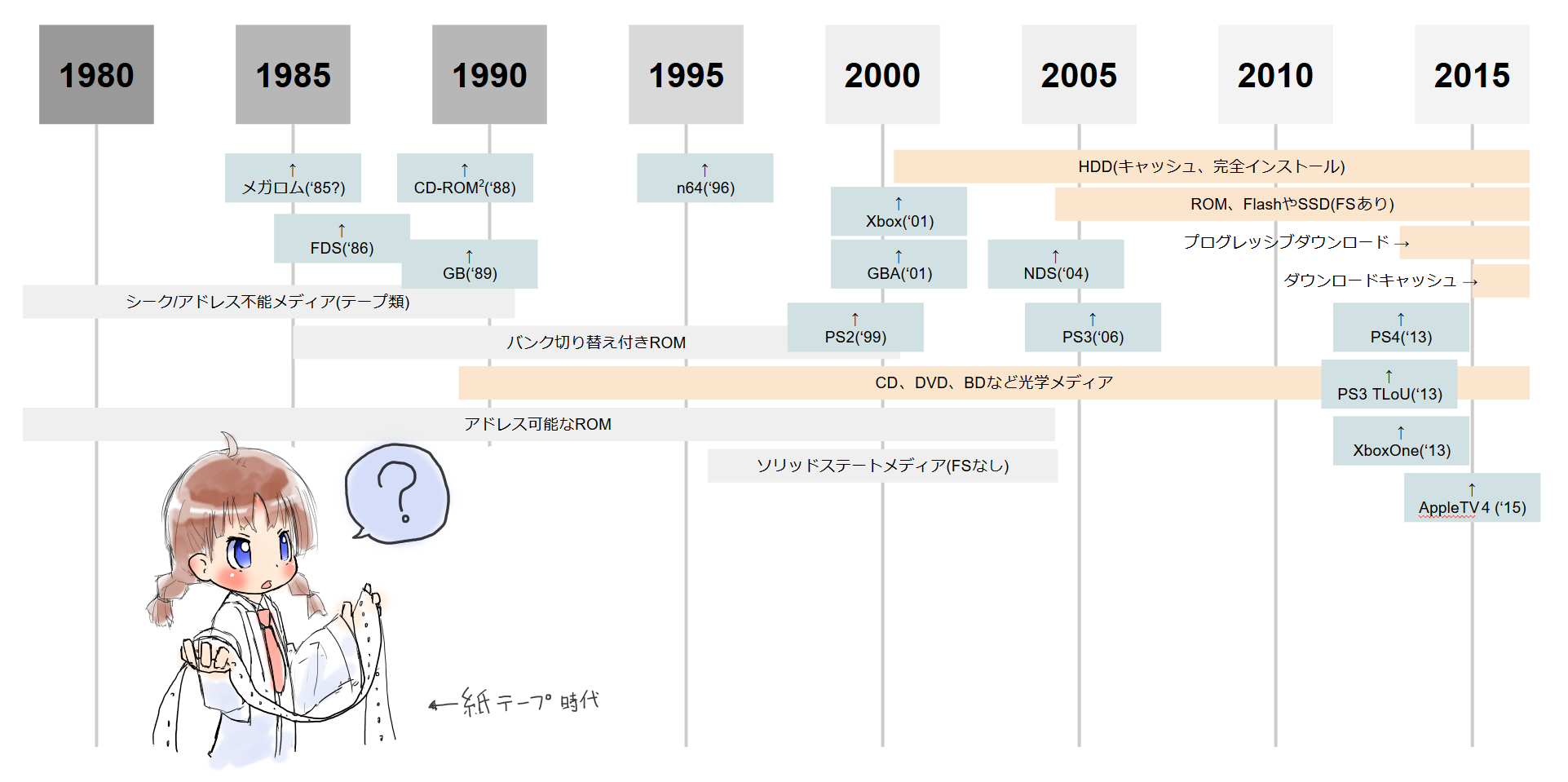
...とにかく歴史的に様々な方式が使用されている。例えば、ゲームを発売後パッチするにはHDDやSSDのようなFSを持った大容量ストレージが必要になるが、それが可能になったのは2001年以降(PS B.B. Unitやoriginal Xboxなどの登場以後)と言える。(サテラビュー('95)やDreamcast('98)のようなプラットフォームでもDLCの類は存在したがゲームの不具合修正をpost releaseで行う目的には使えなかった。)
PS4ではプログレッシブダウンロード(ゲームを複数セグメントに分割し、一部のダウンロードが完了した段階で起動許可)をサポートしているが、導入自体はPS3版The Last of Usの方が早い( https://www.theverge.com/2013/5/18/4344260/the-last-of-us-play-while-downloading-ps4-ps3 )。
光学ディスクは非常に長いこと使用されているが、実は光学ディスクから直接ゲームを起動できるのは現行機ではPS4だけで、XboxOneは完全インストールを前提としている。PS4も、ディスクと同容量のHDDをゲームプレイには必要としている。
ゲームストレージの課題
ゲームは大量のデータを消費者に届け、かつ動画のようなストリーミングと異なり複雑なアクセスパターンを持つという点では特異なユースケースと言える。このため様々なゲーム固有の考察がファイルシステムには求められている。
シークは非常に古典的だが現在も問題になる。CD-ROMゲーム機の登場以降、ゲームはCD/DVD/BDのような光学ディスクで配布されるだけでなく、ダウンロードゲームも結局はHDDにインストールされる可能性があるためよく使用されるデータはコピーしてでも近傍に配置する等の配慮が必要になる。
"スクールガールストライカーズの内製クライアントエンジン"( http://www.jp.square-enix.com/conference/2014/technical_seminar/img/pdf/SQEX_DevCon_sugimoto.pdf )は既に4年も前の講演だが現代でも有効な内容で、この領域にいくつかの知見を提供している。スクールガールストライカーズのようなid引きおよびオンメモリ配列によるによるファイルアクセスは多くのゲームで伝統的に使用されており、パッケージ化されたミドルウェアとしては例えばファイルマジックPRO( http://www.cri-mw.co.jp/product/cs/filemajikpro/index.html )が有る。
(モバイルデバイスではフラッシュメモリを前提として良くなったため、データのコピー等を伴うシーク最適化はほぼ不要になった。しかし、プラットフォーム/OSのファイルアクセスは依然非効率なケースがあるため特に理由の無い限りはパックファイルを採用する方がパフォーマンス上は有利なことが多い気がする。)
パッチはシークに比べると最近出てきた問題だがどのプラットフォームでも等しく問題になっている。例えば、UWPではパッチのダウンロードサイズを減らすために以下のようなアドバイスをしている: https://blogs.msdn.microsoft.com/appinstaller/2016/12/03/differential-updates-for-uwp-apps/
- パッケージに含まれるファイル一つ一つのサイズを小さくする
- ファイルの変更ではなく、ファイルの追加を行う
- ファイルを変更しなければならない場合は変更を64KiBのブロック単位にする
そもそもUWPではファイル単位でのパッチを行うが、Unreal Engineのような通常のゲームエンジンはファイルをpackしてしまうためUWPのパッチ戦略はあまり上手く適合していない。もし本当にパッチを効率的に配信する必要があるならば、パックファイル内のファイルを64KiB境界にアラインする必要がある。
...当然このアライン単位はプラットフォーム毎に異なり、例えばSteamの場合は128MiBになっている。Androidはbsdiffを採用しているためアライン単位は存在しない https://developers-jp.googleblog.com/2016/12/saving-data-reducing-the-size-of-app-updates-by-65-percent.html (が、そもそもサイズ制約から.apkでゲームアセット全体を配布するのはあまり現実的でもない)。
大きく分けて、パッチには2戦略存在する:
- 完全適用型: ネットワークからダウンロードしたパッチファイルを元にストレージ上のパッケージを書き換えてしまうもの。ユーザはパッチの適用処理を待つ必要がある。UWPやSteam等プラットフォームが提供するパッチシステムはこちらを実装している事が多い。
- オーバーレイ型: パッチではファイルの追加を行い、ゲーム側でファイル読み取り先を置き換えるもの。前出のファイルマジックPROはこちらを実装している。適用コストは安いがパッケージの占める容量は膨張していくため大きな修正には向かない。
ゲームエンジンから見た場合、これらのパッチ戦略はプラットフォームが提供するものに従うしかないためなかなか匙加減が難しい。ファイルを一切パックせずにシステムが提供するファイルシステムに全てを任せるのが最も(パッチという面では)効率的になるが、パックファイルを使用したアクセス面での効率化を図ることができないことになる。
プログレッシブダウンロードは新しい話題で、ゲームを完全にダウンロードする前でも起動できるようにし、必要なアセットをOn Demandで供給したり不要となったアセットをデバイスから削除して容量を節約できるようにする。この分野ではiOSのOn demand resourcesが必要な機能性をよく要約している https://developer.apple.com/jp/documentation/FileManagement/Conceptual/On_Demand_Resources_Guide/index.html 。
iOSのOn-demand resourceではファイルを"タグ"に分類し、アプリケーションからは必要なタグを都度宣言させる方法を取る。タグに対応したファイルのダウンロードとマウントおよび削除はiOS側で自動的に管理される。
プログレッシブダウンロードの難しい点はデバッグで、ネットワーク処理はiOSが代行するもののエラー等に関してはアプリケーション側でハンドルする必要がありアプリケーション実装の複雑さを増加させてしまう。しかもプラットフォーム要求なので使わないわけにも行かないという問題がある。(マルチプラットフォームでのリリースを考えると、デバッグのことを最初から考慮して自前のシステムを組んだ方が楽だが。。)
どこまで抽象化できるか
とりあえず現時点では、UnityやUnreal Engineのような統合型のゲームエンジンを採用するプロジェクトではあんまりチャンスが無い。これらのゲームエンジンでは自前のアセットパイプラインを前提に置いており、エンジンのユーザには細かい制御を提供していない。
Unity公式の仕組みには細かくファイル(アセット)を「管理する」という設計思想がありませんので、Unityなら共通であろうという処理が作れないためです。
Unityのシーンシステムを使わず、ゲーム内の複数シーンを単一シーンに纏めるといった工夫をするケースも有るが、この"宴"のケースのようにゲームエンジンにゲームエンジンを載せてしまうといった解法も有る。(ただし、Unity 2018からAddressable Asset System https://www.slideshare.net/UnityTechnologiesJapan/unite-2018-tokyo-96499382/UnityTechnologiesJapan/unite-2018-tokyo-96499382 やスクリプト可能なアセットパイプラインでこれらの問題への対処を始めた。)
クライアント実装の基本的な指針としては:
- 可能な限りOSのファイルシステム機能を直接使用しない。例外: プログレッシブダウンロードなどプラットフォーム機能が必要な場合。通常、ミドルウェア類はファイルシステムインターフェースを外部から与えられることが多い。通常のシチュエーションではstdioのような標準ライブラリが使用できなくなるのに注意する。
- 階層化ファイルシステムを期待しない。実はパスの解決は重い操作で、ファイルシステムによってはシークが必要になる可能性がある。例えば"Assets/a/b/c.png"のようなパスはディレクトリをAssets→a→bと辿る操作が入る可能性がある。一般的には、ファイルをpackすることで階層化ファイルシステムのオーバヘッドを削減していることが多い。
- "カレントディレクトリ"を使用しない(変更しない)。過去にはWinCEのようにカレントディレクトリのコンセプト自体が無いシステムも存在したが、殆どのシステムには依然カレントディレクトリのコンセプト自体は存在する。しかし、packファイル上に実現されるストレージでカレントディレクトリをエミュレーションするのは非効率と言える。また、カレントディレクトリはプロセスグローバルなので、スレッド環境下では良く使えない。"Multithreaded applications and shared library code should not use the GetCurrentDirectory function and should avoid using relative path names. " ( https://msdn.microsoft.com/en-us/library/aa364934%28VS.85%29.aspx )
- 可能な限り文字列パスではなくIDベースのアクセスを採用する(= パスオブジェクトを抽象化する)。ただし、これが有効なシチュエーションは非常に限られている(自前のアーカイブシステムを実装する余地があるケースくらい)。Addressable Assetのように文字列をファイルの識別子として使用できることが多く、ミドルウェア類も通常は文字列でのファイル指定を期待していることが多い。
- ファイルがダウンロードされていない可能性を考慮し、ファイルのavailabilityをクエリするインターフェースを用意する。例えば、iOSのOn demand resourceではタグの単位でファイルのavailablityが変わることになる。
エンジン実装時のポイントになり得るのは、良いプロファイラを実装することと、プラットフォームのパッチ/ストリーミング戦略に良く適合することと言える。ファイルアクセスのプロファイラは一般的な機能になりつつある。例えばゲーム起動時にアクセスされるファイルをpackファイル中の近所に配置することでシーク距離を減らしHDDインストールでのパフォーマンスを向上できる。
プラットフォームのパッチ/ストリーミング戦略への適合は今のところ良い指針が無いが、現状のプラットフォームではiOSのOn demand resourceが最も保守的な実装となっているため、そこに合わせるのが良いと考えられる。